十一、网络相关面试题讲解
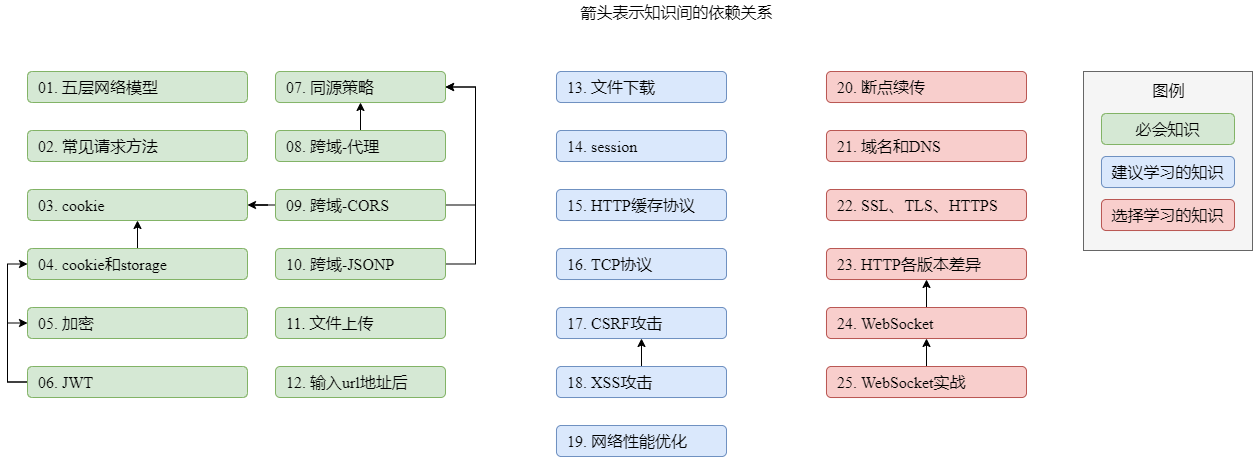
(一)五层网络模型
1.分层的意义
- 当遇到一个复杂问题的时候,可以使用分层的思想把问题简单化
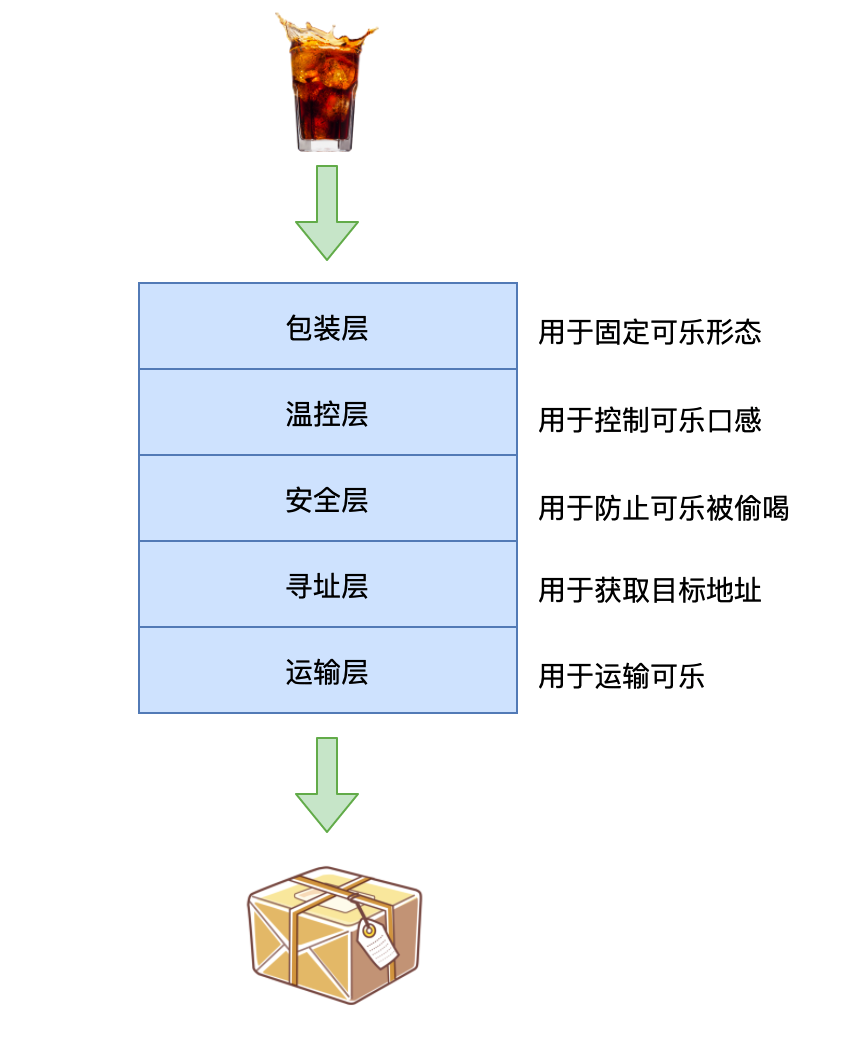
如:有半杯 82 年的可乐,想分享给朋友王富贵,但已经 10 年没有联系了。要完成这件事,可能要考虑:
我用什么装可乐?
可能的方案:塑料瓶、玻璃瓶、煤气罐
怎么保证可乐始终处于低温?
可能的方案:保温杯、小冰箱、冰盒
如何保证可乐不被运输的人偷喝?
可能的方案:封条、在上面写「毒药」
如何获取王富贵的地址?
可能的方案:报案失踪、联系私人侦探、联系物流公司的朋友
如何运输?
可能的方案:自行车、汽车、火车、高铁、飞机、火箭
这就形成了一个分层结构
- 每层相对独立,只需解决自己的问题
- 每层无须考虑上层的交付,仅需把自己的结果交给下层即可
- 每层有多种方案可供选择,选择不同的方案不会对上下层造成影响
- 每一层会在上一层的基础上增加一些额外信息
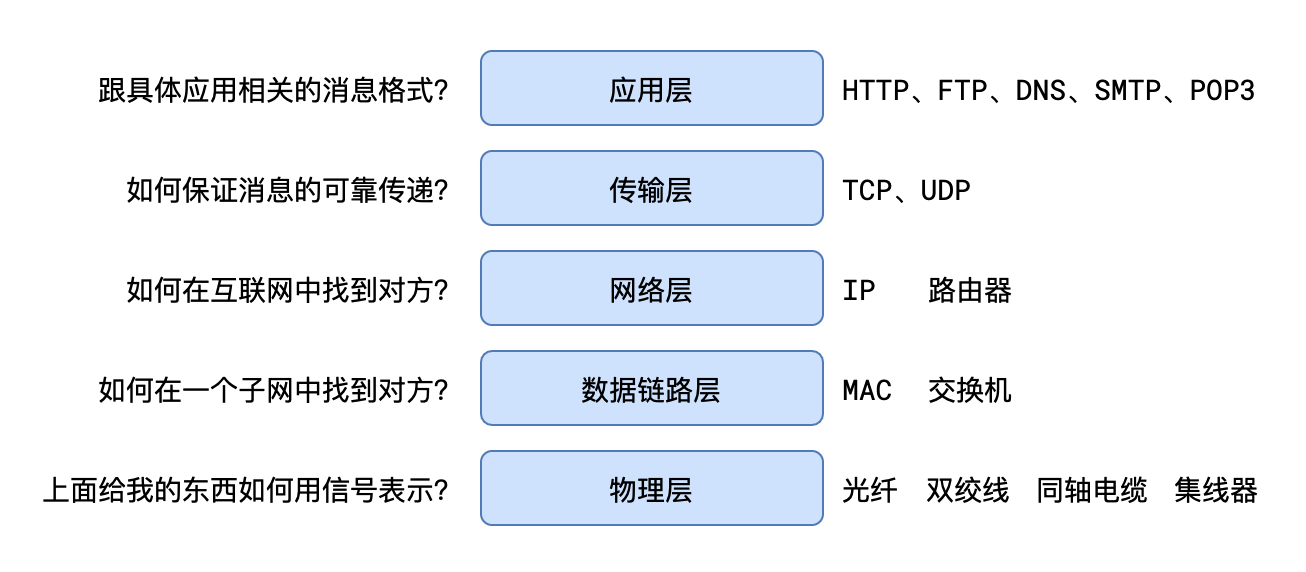
2.五层网络模型
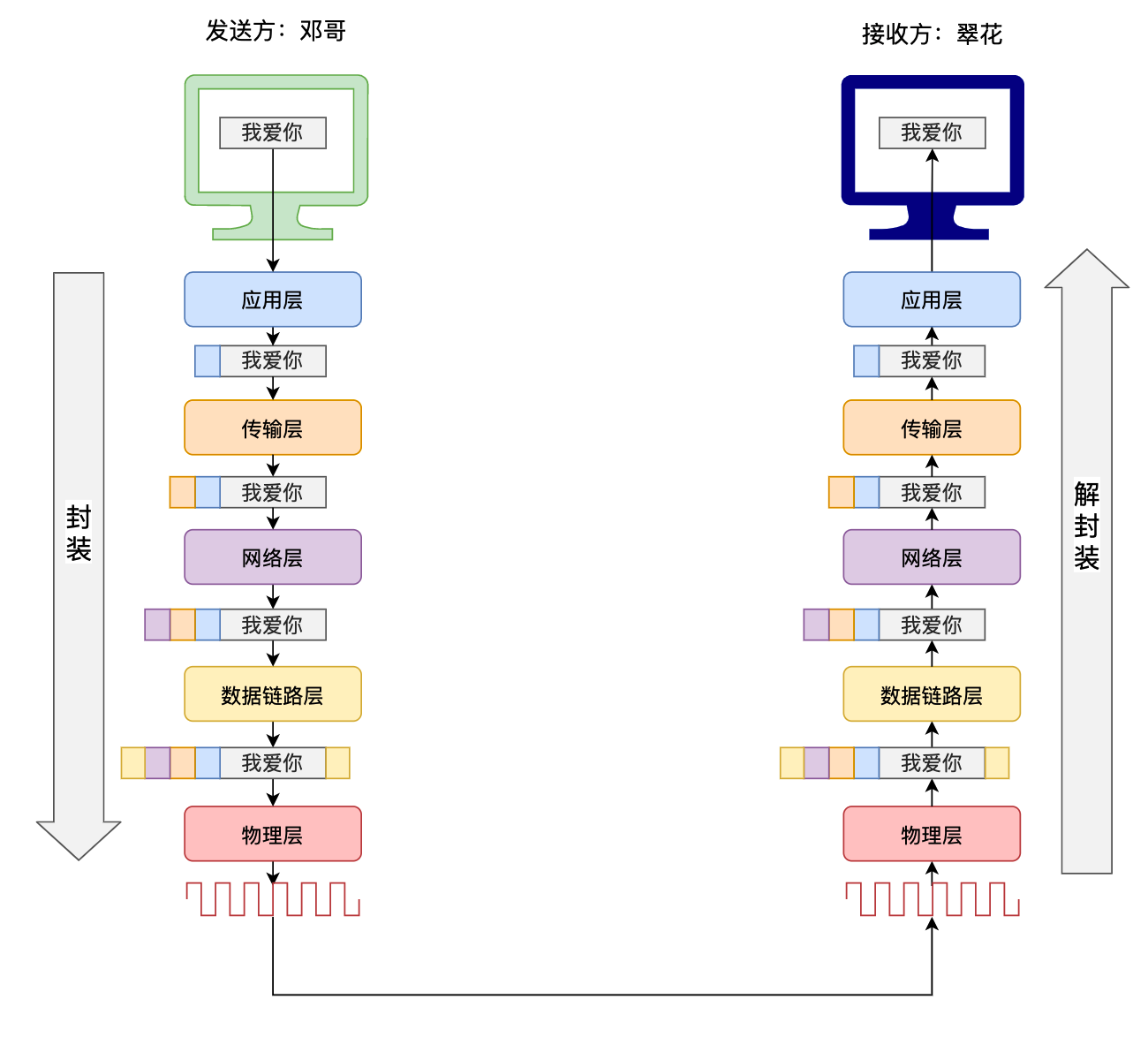
3.数据的封装和解封装
4.四层、七层、五层
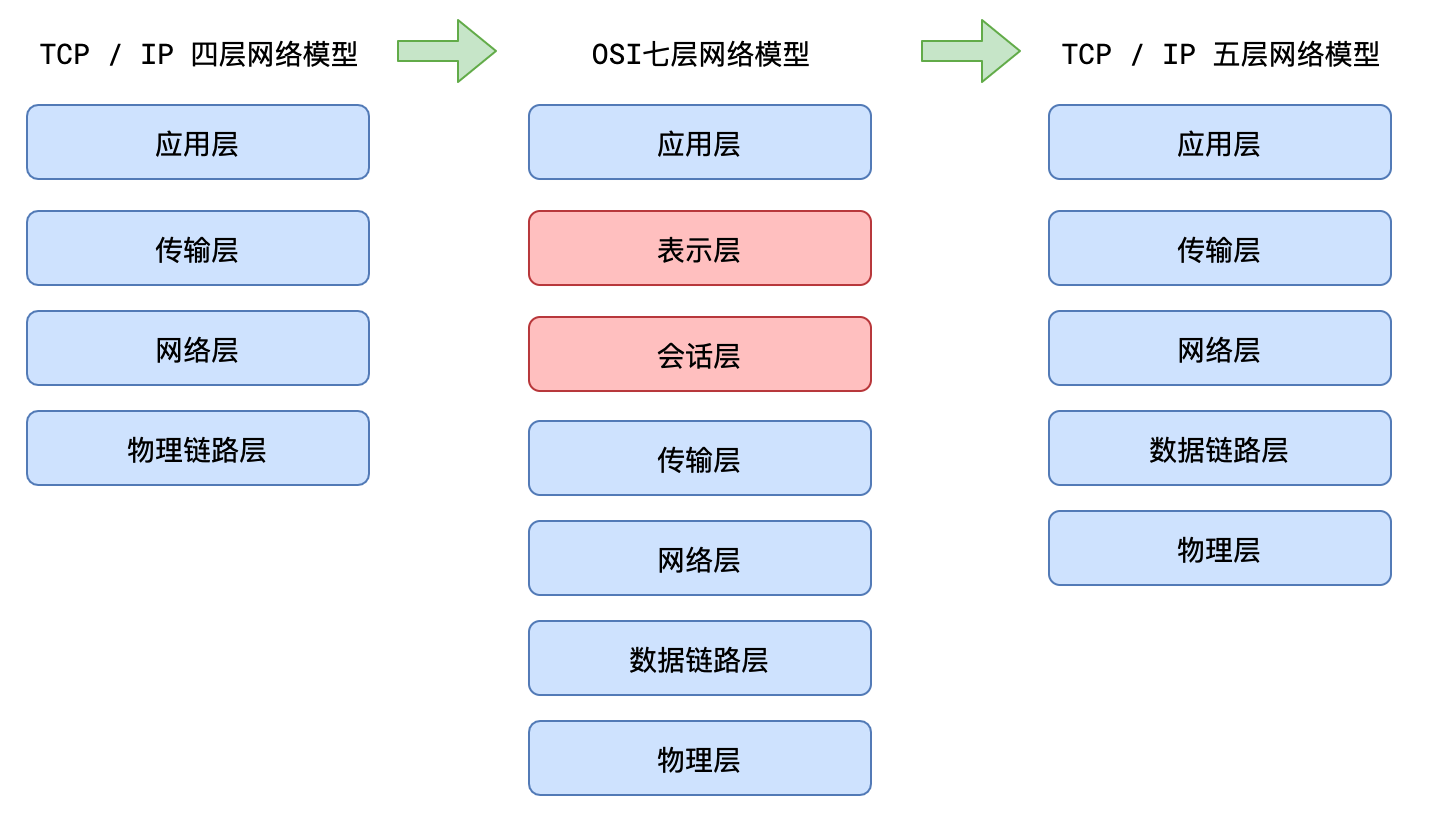
5.面试题
1)说说网络的五层模型(寺库)
从上到下分别为:应用层、传输层、网络层、数据链路层、物理层。在发送消息时,消息从上到下进行打包,每一层会在上一层基础上加包,而接受消息时,从下到上进行解包,最终得到原始信息
- 应用层主要面向互联网中的应用场景,比如网页、邮件、文件中心等等,它的代表协议有 http、smtp、pop3、ftp、DNS 等等
- 传输层主要面向传输过程,比如 TCP 协议是为了保证可靠的传输,而 UDP 协议则是一种无连接的广播,它们提供了不同的传输方式
- 网络层主要解决如何定位目标以及如何寻找最优路径的问题,比如 IP 等等
- 数据链路层的作用是将数据在一个子网(广播域)内有效传输,MAC 地址、交换机都是属于该层的
- 物理层是要解决二进制数据到信号之间的互转问题,集线器、双绞线、同轴电缆等都是属于该层的设备
(二)常见请求方法
<form action="https://study.duyiedu.com/api/user/login" method="POST">
<h1>用POST方法提交</h1>
<div>
账号:
<input name="loginId" type="text" />
</div>
<div>
密码:
<input name="loginPwd" type="password" />
</div>
<button>提交</button>
</form>
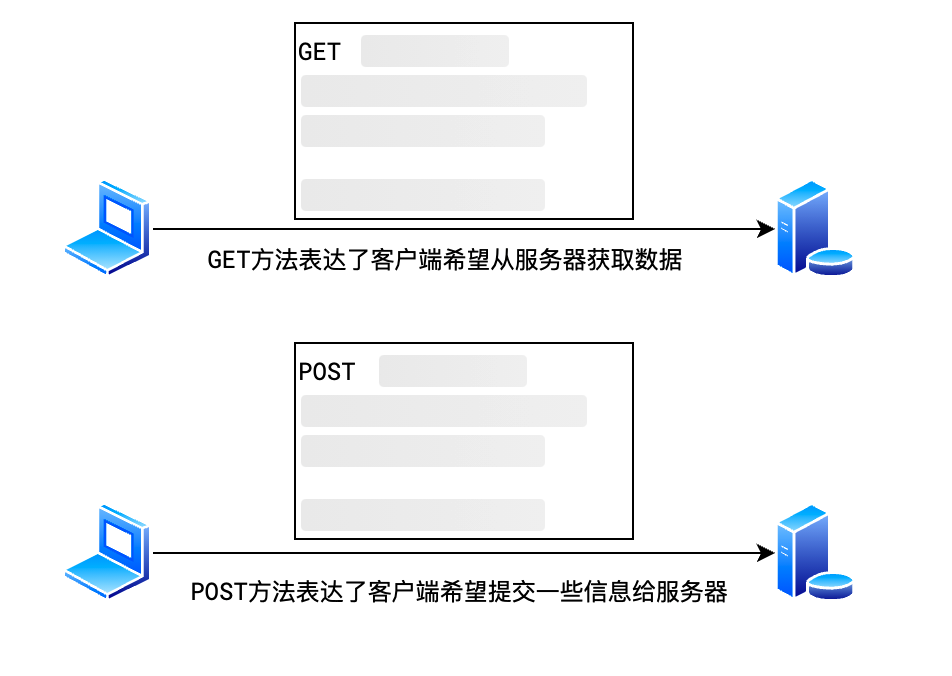
1.请求方法的本质
- 请求方法是请求行中的第一个单词
- 向服务器描述了客户端发出请求的动作类型
- 在 HTTP 协议中,不同的请求方法只是包含了不同的语义,但服务器和浏览器的一些约定俗成的行为造成了它们具体的区别
fetch("https://www.baidu.com", {
method: "heiheihei", // 告诉百度,我这次请求是来嘿嘿嘿的
});
使用了自定义方法
heiheihei,虽然百度服务器无法理解这样的请求是在干什么,但这样的请求也是可以正常发送到百度服务器的
- 在实践中,客户端和服务器慢慢的形成了一个共识
- 约定俗成地规定了一些常见的请求方法
| 请求方法 | 含义 |
|---|---|
| GET | 表示向服务器获取资源 业务数据在请求行中,无须请求体 |
| POST | 表示向服务器提交信息,通常用于产生新的数据,如:注册 业务数据在请求体中 |
| PUT | 表示希望修改服务器的数据,通常用于修改 业务数据在请求体中 |
| DELETE | 表示希望删除服务器的数据 业务数据在请求行中,无须请求体 |
| OPTIONS | 发生在跨域的预检请求中 表示客户端向服务器申请跨域提交 |
| TRACE | 回显服务器收到的请求 主要用于测试和诊断 |
| CONNECT | 用于建立连接管道,通常在代理场景中使用 网页中很少用到 |
2.GET 和 POST 的区别
由于浏览器和服务器约定俗称的规则,造成了 GET 和 POST 请求在 web 中的区别
- 浏览器在发送 GET 请求时,不会附带请求体
- GET 请求的传递信息量有限,适合传递少量数据;POST 请求的传递信息量是没有限制的,适合传输大量数据
- GET 请求只能传递 ASCII 数据,遇到非 ASCII 数据需要进行编码;POST 请求没有限制
- 大部分 GET 请求传递的数据都附带在 path 参数中,能够通过分享地址完整的重现页面,但同时也暴露了数据,若有敏感数据传递,不应该使用 GET 请求,至少不应该放到 path 中
- 刷新页面时,若当前的页面是通过 POST 请求得到的,则浏览器会提示用户是否重新提交。若是 GET 请求得到的页面则没有提示
- GET 请求的地址可以被保存为浏览器书签,POST 不可以
3.面试题
1)http 常见请求方法有哪些?
- GET,表示向服务器获取资源
- POST,表示向服务器提交信息,通常用于产生新的数据,比如注册
- PUT,表示希望修改服务器的数据,通常用于修改
- DELETE,表示希望删除服务器的数据
- OPTIONS,发生在跨域的预检请求中,表示客户端向服务器申请跨域提交
- TRACE,回显服务器收到的请求,主要用于测试和诊断
- CONNECT,用于建立连接管道,通常在代理场景中使用,网页中很少用到
2)GET 和 POST 的区别(流利说)
从 HTTP 协议的角度来说,GET 和 POST 它们都只是请求行中的第一个单词,除了语义不同,其实没有本质的区别
之所以在实际开发中会产生各种区别,主要是因为浏览器的默认行为造成的
受浏览器的影响,在实际开发中,GET 和 POST 有以下区别:
- 浏览器在发送 GET 请求时,不会附带请求体
- GET 请求的传递信息量有限,适合传递少量数据;POST 请求的传递信息量是没有限制的,适合传输大量数据
- GET 请求只能传递 ASCII 数据,遇到非 ASCII 数据需要进行编码;POST 请求没有限制
- 大部分 GET 请求传递的数据都附带在 path 参数中,能够通过分享地址完整的重现页面,但同时也暴露了数据,若有敏感数据传递,不应该使用 GET 请求,至少不应该放到 path 中
- 刷新页面时,若当前的页面是通过 POST 请求得到的,则浏览器会提示用户是否重新提交。若是 GET 请求得到的页面则没有提示
- GET 请求的地址可以被保存为浏览器书签,POST 不可以
(三)Cookie
1.cookie 的组成
cookie 是浏览器中特有的一个概念,管理各个网站的身份信息
每个 cookie 就相当于是属于某个网站的一个卡片,记录了下面的信息
1)key
- 键
- 如:身份编号
2)value
- 值
- 如:袁小进的身份编号 14563D1550F2F76D69ECBF4DD54ABC95
- 可以是任何信息
3)domain
- 域
- 表达这个 cookie 是属于哪个网站的
- 如:
yuanjin.tech表示这个 cookie 是属于yuanjin.tech这个网站的
4)path
- 路径
- 表达这个 cookie 是属于该网站的哪个基路径的
- 如:同一家公司不同部门会颁发不同的出入证
- 如:
/news表示这个 cookie 属于/news这个路径
5)secure
- 是否使用安全传输
6)expire
- 过期时间
- 表示该 cookie 在什么时候过期
2.cookie 的条件
当浏览器向服务器发送一个请求的时候,会判断哪些 cookie 适合附带给服务器
如果一个 cookie 同时满足 以下条件,则这个 cookie 会被附带到请求中
1)cookie 没有过期
2)cookie 中的域和这次请求的域是匹配的
- 如:cookie 中的域是
yuanjin.tech,则可以匹配的请求域是yuanjin.tech、www.yuanjin.tech、blogs.yuanjin.tech等等 - 如:cookie 中的域是
www.yuanjin.tech,则只能匹配www.yuanjin.tech这样的请求域 - cookie 是不在乎端口的,只要域匹配即可
3)cookie 中的 path 和这次请求的 path 是匹配的
- 如:cookie 中的 path 是
/news,则可以匹配的请求路径可以是/news、/news/detail、/news/a/b/c等等,但不能匹配/blogs - 如果 cookie 的 path 是
/,可以想象,能够匹配所有的路径
4)验证 cookie 的安全传输
- 如果 cookie 的 secure 属性是 true,则请求协议必须是
https,否则不会发送该 cookie - 如果 cookie 的 secure 属性是 false,则请求协议可以是
http,也可以是https
5)加入请求的方式
- 如果一个 cookie 满足了上述的所有条件,则浏览器会把它自动加入到这次请求中
- 浏览器会将符合条件的 cookie,自动放置到请求头中
- 格式是
键=值; 键=值; 键=值; ...- 每一个键值对就是一个符合条件的 cookie
cookie 中包含了重要的身份信息,永远不要把你的 cookie 泄露给别人
否则,他人就拿到了你的证件,有了证件,就具备了为所欲为的可能性
3.设置 cookie
cookie 是保存在浏览器端的,同时,很多证件又是服务器颁发的
所以,cookie 的设置有两种模式
1)服务器响应
- 这种模式非常普遍
- 当服务器决定给客户端颁发一个证件时,会在响应的消息中包含 cookie,浏览器会自动的把 cookie 保存到卡包中
2)客户端自行设置
- 这种模式少见一些,不过也有可能会发生
- 如:用户关闭了某个广告,并选择了【以后不要再弹出】,此时就可以把这种小信息直接通过浏览器的 JS 代码保存到 cookie 中
- 后续请求服务器时,服务器会看到客户端不想要再次弹出广告的 cookie,于是就不会再发送广告过来了
4.服务器端设置 cookie
- 服务器可以通过设置响应头,来告诉浏览器应该如何设置 cookie
1)响应头的格式
set-cookie: cookie1
set-cookie: cookie2
set-cookie: cookie3
# ...
2)每个 cookie 的格式
键=值; path=?; domain=?; expire=?; max-age=?; secure; httponly
- 每个 cookie 除了键值对是必须要设置的,其他的属性都是可选的,并且顺序不限
- 当这样的响应头到达客户端后,
- 浏览器会自动的将 cookie 保存到卡包中
- 如果卡包中已经存在一模一样的卡片(其他 path、domain 相同),则会自动的覆盖之前的设置
3)cookie 属性值
a)path
- 设置 cookie 的路径
- 如果不设置,浏览器会将其自动设置为 当前请求的路径
- 如:浏览器请求的地址是
/login,服务器响应了一个set-cookie: a=1- 浏览器会将该 cookie 的 path 设置为请求的路径
/login
- 浏览器会将该 cookie 的 path 设置为请求的路径
b)domain
- 设置 cookie 的域
- 如果不设置,浏览器会自动将其设置为当前的请求域
- 如:浏览器请求的地址是
http://www.yuanjin.tech,服务器响应了一个set-cookie: a=1- 浏览器会将该 cookie 的 domain 设置为请求的域
www.yuanjin.tech
- 浏览器会将该 cookie 的 domain 设置为请求的域
- 这里值得注意的是,如果服务器响应了一个无效的域,浏览器是不认的
- 无效的域,响应的域连根域都不一样
- 如:浏览器请求的域是
yuanjin.tech,服务器响应的 cookie 是set-cookie: a=1; domain=baidu.com,这样的域浏览器是不认的 - 如果浏览器连这样的情况都允许,就意味着张三的服务器,有权利给用户一个 cookie,用于访问李四的服务器,这会造成很多安全性的问题
- 如:浏览器请求的域是
c)expire
- 设置 cookie 的过期时间
- 必须是一个有效的 GMT 时间,即格林威治标准时间字符串
- 如
Fri, 17 Apr 2020 09:35:59 GMT - 表示格林威治时间的
2020-04-17 09:35:59 - 即北京时间的
2020-04-17 17:35:59
- 如
- 当客户端的时间达到这个时间点后,会自动销毁该 cookie
d)max-age
- 设置 cookie 的相对有效期
- expire 和 max-age 通常仅设置一个即可
- 如:设置
max-age为1000,浏览器在添加 cookie 时,会自动设置它的expire为当前时间加上 1000 秒,作为过期时间
注意
- 如果不设置 expire,又没有设置 max-age,则表示会话结束后过期
- 对于大部分浏览器而言,关闭所有浏览器窗口意味着会话结束
e)secure
- 设置 cookie 是否是安全连接
- 如果设置了该值,则表示该 cookie 后续只能随着
https请求发送 - 如果不设置,则表示该 cookie 会随着所有请求发送
f)httponly
- 设置 cookie 是否仅能用于传输
- 如果设置了该值,表示该 cookie 仅能用于传输,而不允许在客户端通过 JS 获取
- 这对防止跨站脚本攻击(XSS)会很有用
4)设置示例
- 客户端通过
post请求服务器http://yuanjin.tech/login,并在消息体中给予了账号和密码 - 服务器验证登录成功后,在响应头中加入了以下内容
set-cookie: token=123456; path=/; max-age=3600; httponly
- 当该响应到达浏览器后,浏览器会创建下面的 cookie
key: token
value: 123456
domain: yuanjin.tech
path: /
expire: 2020-04-17 18:55:00 # 假设当前时间是2020-04-17 17:55:00
secure: false # 任何请求都可以附带这个cookie,只要满足其他要求
httponly: true # 不允许JS获取该cookie
- 随着浏览器后续对服务器的请求,只要满足要求,这个 cookie 就会被附带到请求头中传给服务器
cookie: token=123456; 其他cookie...
5)删除浏览器的 cookie
- 只需要让服务器响应一个同样的域、同样的路径、同样的 key,只是时间过期的 cookie 即可
- 删除 cookie 其实就是 修改 cookie
set-cookie: token=; domain=yuanjin.tech; path=/; max-age=-1
- 浏览器按照要求修改了 cookie 后,会发现 cookie 已经过期,于是自然就会删除了
无论是修改还是删除,都要注意 cookie 的域和路径,因为完全可能存在域或路径不同,但 key 相同的 cookie
因此无法仅通过 key 确定是哪一个 cookie
5.客户端设置 cookie
- 浏览器向 JS 公开了接口,让其可以设置 cookie
document.cookie = "键=值; path=?; domain=?; expire=?; max-age=?; secure";
- 在客户端设置 cookie,和服务器设置 cookie 的格式一样,只是有下面的不同
1)没有 httponly
- 因为 httponly 本来就是为了限制在客户端访问的
- 既然是在客户端配置,自然失去了限制的意义
2)path 的默认值
- 在服务器端设置 cookie 时,如果没有写 path,使用的是 请求的 path
- 而在客户端设置 cookie 时,也许根本没有请求发生
- 因此,path 在客户端设置时的默认值是 当前网页的 path
3)domain 的默认值
- 和 path 同理,客户端设置时的默认值是 当前网页的 domain
4)其他
- 和服务器设置时一样
5)删除 cookie
- 和服务器设置时一样,修改 cookie 的过期时间即可
6.总结
- Cookie 用于登录场景的流程
1)登录请求
- 浏览器发送请求到服务器,附带账号密码
- 服务器验证账号密码是否正确,如果不正确,响应错误,如果正确,在响应头中设置 cookie,附带登录认证信息(至于登录认证信息是设么样的,如何设计,要考虑哪些问题,就是另一个话题了,可以百度 jwt)
- 客户端收到 cookie,浏览器自动记录下来
2)后续请求
- 浏览器发送请求到服务器,希望添加一个管理员,并将 cookie 自动附带到请求中
- 服务器先获取 cookie,验证 cookie 中的信息是否正确,如果不正确,不予以操作,如果正确,完成正常的业务流程
(四)Cookie 和 Storage 的区别
1.面试题
1)cookie/sessionStorage/localStorage 的区别
cookie、sessionStorage、localStorage 都是保存本地数据的方式
- cookie 兼容性较好,所有浏览器均支持
- 浏览器针对 cookie 会有一些默认行为
- 如:当响应头中出现
set-cookie字段时,浏览器会自动保存 cookie 的值- 如:浏览器发送请求时,会附带匹配的 cookie 到请求头中
- 这些默认行为,使得 cookie 长期以来担任着维持登录状态的责任
- 与此同时,也正是因为浏览器的默认行为,给了恶意攻击者可乘之机,CSRF 攻击就是一个典型的利用 cookie 的攻击方式
- 虽然 cookie 不断的改进,但前端仍然需要另一种更加安全的保存数据的方式
- HTML5 新增了 sessionStorage 和 localStorage
- 前者用于保存会话级别的数据,后者用于更持久的保存数据
- 浏览器针对它们 没有任何默认行为 ,这样一来,就把保存数据、读取数据的工作交给了前端开发者,这就让恶意攻击者难以针对登录状态进行攻击
- cookie 的大小是有限制的,一般浏览器会限制同一个域下的 cookie 总量为 4M,而针对同一个域名,其下的 sessionStorage 和 localStorage 只有总量限制(官方为 5M,不同浏览器有差异)
- cookie 会与 domain、path 关联,而 sessionStorage 和 localStorage 只与 domain 关联
(五)加密算法
1.密钥
- 是一种参数,在明文转换为密文或将密文转换为明文的算法中输入的参数
- 密钥分为对称密钥与非对称密钥,分别应用在对称加密和非对称加密上
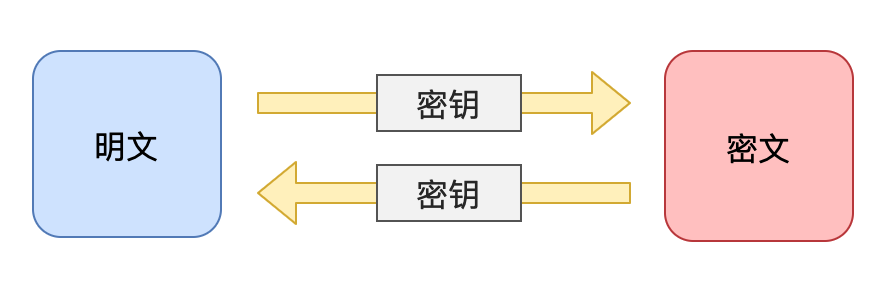
2.对称加密
- 又叫私钥加密
- 信息的发送方和接收方使用 同一个密钥 加密和解密数据
- 如果一方的密钥遭泄露,那么整个通信就会被破解
1)常见算法
- DES
- 3DES
- TDEA
- Blowfish
- RC5
- IDEA
2)优点
- 加密、解密速度快
- 适合对大数据量进行加密
3)缺点
- 在网络中需要分发密钥
- 增加了密钥被窃取的风险
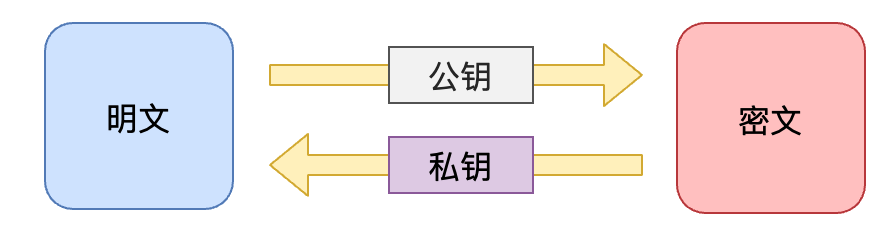
3.非对称加密
- 又叫公钥加密
- 使用一对密钥,即公钥和私钥,且二者成对出现
- 私钥被自己保存,不能对外泄露
- 公钥指的是公共的密钥,任何人都可以获得该密钥
- 用公钥或私钥中的任何一个进行加密,用另一个进行解密
1)常见算法
- RSA
- Rabin
- DSA
- ECC
- Elgamal
- D-H
2)优点
- 安全性更好
- 私钥仅被一方保存,不用于网络传输
3)缺点
- 仅能一方进行解密
4.摘要/哈希/散列
- 通过一个函数,把任意长度的数据转换为一个长度固定的数据串
- 通常用 16 进制的字符串表示

const md5 = require("md5");
const origin =
"sdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfdsdfasdfasdfasfd";
const result = md5(origin);
console.log(result);
1)常见算法
- MD4
- MD5
- SHA1
2)优点
- 密文占用空间小(定长的短字符串)
- 难以被破解
3)缺点
- 无法解密(算法不可逆)
5.面试题
1)请解释一下对称加密,非对称加密,摘要的概念
- 密钥
密钥是一种参数,它是在明文转换为密文或将密文转换为明文的算法中输入的参数。密钥分为对称密钥与非对称密钥,分别应用在对称加密和非对称加密上
- 对称加密
对称加密又叫做私钥加密,即信息的发送方和接收方使用同一个密钥去加密和解密数据。对称加密的特点是算法公开、加密和解密速度快,适合于对大数据量进行加密,常见的对称加密算法有 DES、3DES、TDEA、Blowfish、RC5 和 IDEA
- 非对称加密
非对称加密也叫做公钥加密。非对称加密与对称加密相比,其安全性更好。对称加密的通信双方使用相同的密钥,如果一方的密钥遭泄露,那么整个通信就会被破解。而非对称加密使用一对密钥,即公钥和私钥,且二者成对出现。私钥被自己保存,不能对外泄露。公钥指的是公共的密钥,任何人都可以获得该密钥。用公钥或私钥中的任何一个进行加密,用另一个进行解密
- 摘要
摘要算法又称哈希/散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用 16 进制的字符串表示)。算法不可逆
(六)JWT
1.概述
- JWT,Json Web Token,本质就是一个字符串
- 在互联网环境中,提供 统一的、安全的 令牌格式
- 可以存储到 cookie,也可以存储到 localStorage,没有任何限制
- 可以使用任何传输方式来传输 JWT
- 一般会使用 消息头 来传输它
1)服务器响应 JWT
- 当登录成功后,服务器可以给客户端响应一个 JWT
HTTP/1.1 200 OK
---
set-cookie:token=jwt令牌
authentication:jwt令牌
---
{ ..., token:jwt令牌 }
- JWT 令牌可以出现在响应的任何一个地方,客户端和服务器自行约定即可
- 也可以出现在响应的多个地方
- 如:为了充分利用浏览器的 cookie,同时为了照顾其他设备
- 可以让 JWT 出现在
set-cookie和authorization或body中 - 尽管这会增加额外的传输量
2)客户端存储 JWT
- 可以存储到任何位置
- 如:手机文件、PC 文件、localStorage、cookie
- 当后续请求发生时,只需要将它作为请求的一部分发送到服务器即可
- 虽然 JWT 没有明确要求应该如何附带到请求中,但通常会使用如下的格式
GET /api/resources HTTP/1.1
---
authorization: bearer jwt令牌
- 服务器收到令牌后,通过对令牌的验证,即可知道该令牌是否有效
3)完整交互流程
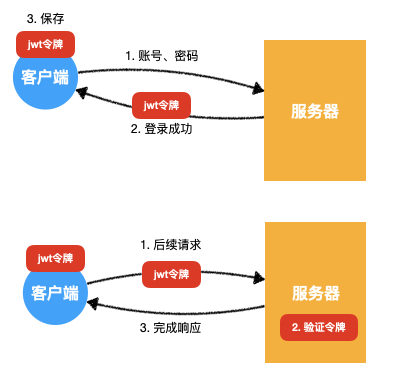
2.令牌的组成
为了保证令牌的安全性,JWT 令牌由三个部分组成
| 组成 | 说明 |
|---|---|
| header | 令牌头部,记录了整个令牌的类型和签名算法 |
| payload | 令牌负荷,记录了保存的主体信息 如:用户信息 |
| signature | 令牌签名,按照头部固定的签名算法对整个令牌进行签名 该签名的作用是:保证令牌不被伪造和篡改 |
- 完整格式:
header.payload.signature
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9.BCwUy3jnUQ_E6TqCayc7rCHkx-vxxdagUwPOWqwYCFc
- 各个部分的值
- header:
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9 - payload:
eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9 - signature:
BCwUy3jnUQ_E6TqCayc7rCHkx-vxxdagUwPOWqwYCFc
- header:
1)header
- 令牌头部,记录了整个令牌的类型和签名算法
- 格式是一个 json 对象
{
"alg": "HS256",
"typ": "JWT"
}
a)alg
- signature 部分使用的签名算法,通常可以取两个值
- HS256
- 一种对称加密算法
- 使用同一个秘钥对 signature 加密解密
- RS256
- 一种非对称加密算法
- 使用私钥签名,公钥验证
b)typ
- 整个令牌的类型
- 固定写
JWT即可
c)生成 header
- 将 header 部分使用
base64 url编码即可
base64 url不是一个加密算法,而是一种编码方式是在
base64算法的基础上对+、=、/三个字符做出特殊处理的算法而
base64是使用 64 个可打印字符来表示一个二进制数据具体的做法参考 百度百科
- 浏览器提供了
btoa函数编码
window.btoa(
JSON.stringify({
alg: "HS256",
typ: "JWT",
}),
);
// 得到字符串:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9
- 浏览器提供了
atob函数解码
window.atob("eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9");
// 得到字符串:{"alg":"HS256","typ":"JWT"}
nodejs 中没有提供这两个函数,可以安装第三方库
atob和btoa搞定或者,手动搞定
2)payload
- 是 JWT 的主体信息
- 仍然是一个 JSON 对象
- 可以包含以下内容
{
"ss":"发行者",
"iat":"发布时间",
"exp":"到期时间",
"sub":"主题",
"aud":"听众",
"nbf":"在此之前不可用",
"jti":"JWT ID"
}
以上属性可以全写,也可以一个都不写,只是一个规范
就算写了,也需要在将来验证这个 JWT 令牌时手动处理才能发挥作用
| 属性 | 含义 |
|---|---|
| ss | 发行该 jwt 的是谁 可以写公司名字,也可以写服务名称 |
| iat | 该 jwt 的发放时间 通常写当前时间的时间戳 |
| exp | 该 jwt 的到期时间 通常写时间戳 |
| sub | 该 jwt 是用于干嘛的 |
| aud | 该 jwt 是发放给哪个终端的 可以是终端类型,也可以是用户名称 |
| nbf | 一个时间点 在该时间点到达之前,这个令牌是不可用的 |
| jti | jwt 的唯一编号 设置此项的目的是为了防止重放攻击 |
重放攻击是在某些场景下,用户使用之前的令牌发送到服务器,被服务器正确的识别,从而导致不可预期的行为发生
- 可以向 payload 对象中加入任何想要加入的信息
{
"foo": "bar",
"iat": 1587548215
}
- 最终需要通过
base64 url编码
window.btoa(
JSON.stringify({
foo: "bar",
iat: 1587548215,
}),
);
// 得到字符串:eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9
3)signature
- JWT 的签名,保证了整个 JWT 不被篡改
- 这部分的生成,是 对前面两个部分的编码结果,按照头部指定的方式进行加密
- 指定一个秘钥,如:
shhhhh
HS256(`eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9`, "shhhhh");
// 得到:BCwUy3jnUQ_E6TqCayc7rCHkx-vxxdagUwPOWqwYCFc
4)组合
- 将三部分组合在一起,就得到了完整的 jwt
- 由于签名使用的秘钥保存在服务器,客户端就无法伪造出签名,因为拿不到秘钥
- 而前面两部分并没有加密,只是一个编码结果而已,可以认为几乎是明文传输
这不会造成太大的问题,因为既然用户登陆成功了,当然有权力查看自己的用户信息
甚至在某些网站,用户的基本信息可以被任何人查看
要保证的是不要把敏感的信息存放到 JWT 中,如:密码
3.令牌的验证
- 服务器要验证令牌是否被篡改过
- 就是对
header + payload用同样的秘钥和加密算法进行重新加密
- 就是对
- 然后把加密的结果和传入 JWT 的
signature进行对比- 如果完全相同,则表示前面两部分没有动过,就是自己颁发的
- 如果不同,肯定是被篡改过了
传入的header.传入的payload.传入的signature
新的signature = header中的加密算法(传入的header.传入的payload, 秘钥)
# 验证:新的signature == 传入的signature
- 当令牌验证为没有被篡改后,服务器可以进行其他验证
- 如:是否过期、听众是否满足要求等等
这些验证都需要服务器手动完成,没有哪个服务器会自动验证
当然,可以借助第三方库来完成
const jwt = require("jsonwebtoken");
const key = "yuanjinhenshuai";
// const token = jwt.sign({ a: 1, b: 2 }, key);
// console.log(token);
const token = "eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ7.eyJhIjoxLCJiIjoyLCJpYXQiOjE2MzQ4MDg1Mzh9.EH6KLP-yegEN5H5As7JUzziOenlT5kuHM1Pxj6cJ9C8";
const result = jwt.verify(token, key);
console.log(result);
4.JWT 的特点
- JWT 本质上是一种令牌格式
- 和终端设备、服务器、如何传输无关
- 只是规范了令牌的格式而已
- JWT 由三部分组成
- header、payload、signature
- 主体信息在 payload
- JWT 难以被篡改和伪造
- 因为有第三部分签名的存在
5.面试题
1)请阐述 JWT 的令牌格式
token 分为三段,分别是 header、payload、signature
- header 标识签名算法和令牌类型
- payload 标识主体信息,包含令牌过期时间、发布时间、发行者、主体内容等
- signature 是使用特定的算法对前面两部分进行加密,得到的加密结果
token 有防篡改的特点,如果攻击者改动了前面两个部分,就会导致和第三部分对应不上,使得 token 失效,而攻击者不知道加密秘钥,因此又无法修改第三部分的值
所以,在秘钥不被泄露的前提下,一个验证通过的 token 是值得被信任的
(七)同源策略
1.概述
- 浏览器特有的一个重要的安全策略
- 源 = 协议 + 主机 + 端口
- 同源:两个源相同
- 跨源/跨域:两个源不同
| 源 1 | 源 2 | 是否同源 |
|---|---|---|
| http://www.baidu.com | http://www.baidu.com/news | ✅ |
| https://www.baidu.com | http://www.baidu.com | ❌ |
| http://localhost:5000 | http://localhost:7000 | ❌ |
| http://localhost:5000 | http://127.0.0.1:5000 | ❌ |
| http://www.baidu.com | http://baidu.com | ❌ |
- 同源策略是指,若页面的源和页面运行过程中加载的源不一致时,出于安全考虑,浏览器会对跨域的资源访问进行一些限制

2.跨域限制对象
- 同源策略对 ajax 的跨域限制的最为凶狠
- 默认情况下,不允许 ajax 访问跨域资源
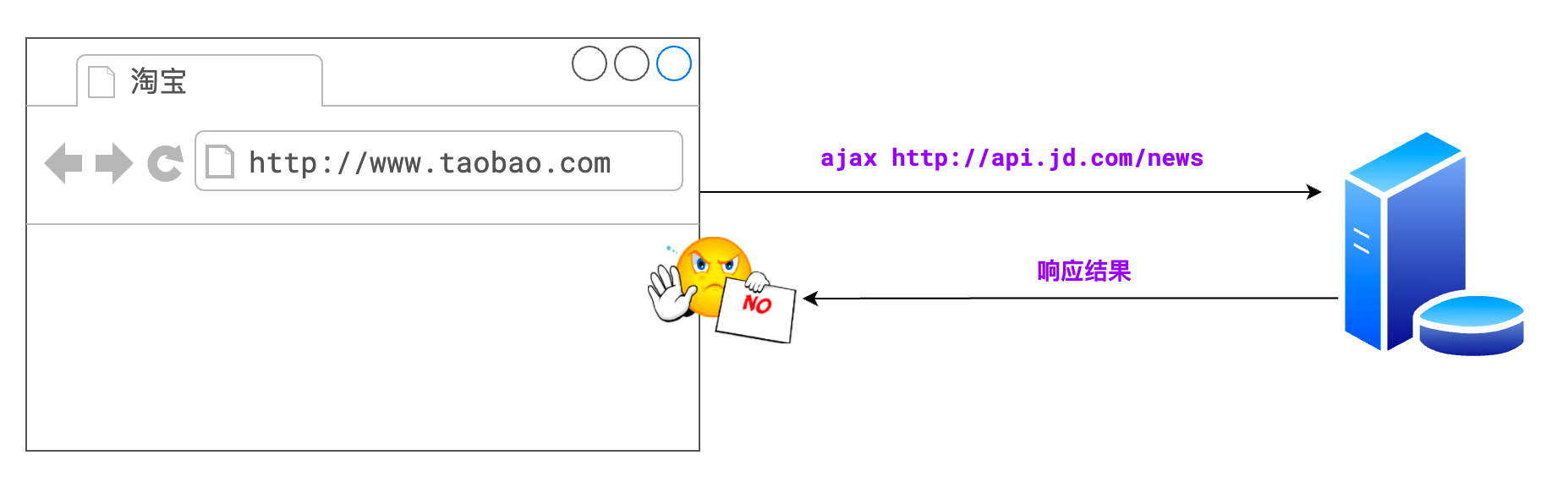
通常所说的跨域问题,就是同源策略对 ajax 产生的影响
3.解决跨域问题
- 代理【常用】
- CORS【常用】
- JSONP
无论使用哪一种方式,都是要让浏览器知道,这次跨域请求的是自己人,就不要拦截了
(八)跨域 —— 代理
- 对于前端开发而言,大部分的跨域问题,都是通过 代理 解决的
1.代理适用的场景
- 生产环境不发生跨域,开发环境发生跨域
- 只需要在开发环境使用代理解决跨域即可,这种代理又称为开发代理
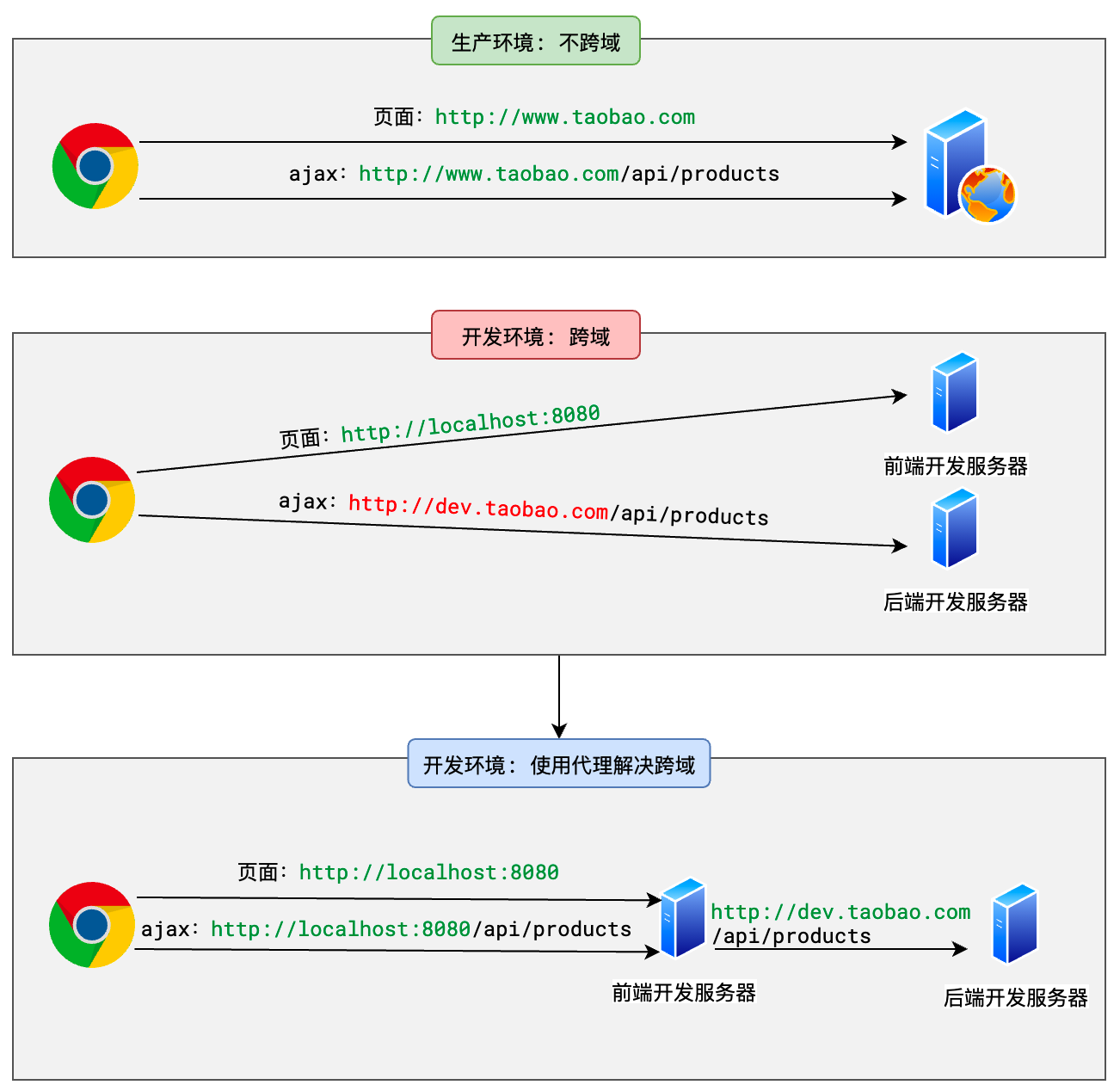
2.配置开发代理
- 在实际开发中,只需要对开发服务器稍加配置即可
// vue 的开发服务器代理配置
// vue.config.js
module.exports = {
devServer: {
// 配置开发服务器
proxy: {
// 配置代理
"/api": {
// 若请求路径以 /api 开头
target: "http://dev.taobao.com", // 将其转发到 http://dev.taobao.com
},
},
},
};
(九)跨域 —— CORS
1.概述
- CORS,Cross-Origin Resource Sharing,跨域资源共享
- 是基于 HTTP1.1 的一种跨域解决方案
- 总体思路是:如果浏览器要跨域访问服务器的资源,需要获得服务器的允许
- 一个请求可以附带很多信息,从而会对服务器造成不同程度的影响
- 有的请求只是获取一些新闻
- 有的请求会改动服务器的数据
- 针对不同的请求,CORS 规定了三种不同的交互模式
- 简单请求
- 需要预检的请求
- 附带身份凭证的请求
- 这三种模式从上到下层层递进,请求可以做的事越来越多,要求也越来越严格
2.简单请求
- 当浏览器端运行了一段 ajax 代码
- 无论是使用 XMLHttpRequest 还是 fetch api
- 浏览器会首先判断它属于哪一种请求模式
1)简单请求的判定
- 当请求 同时满足 以下条件时,浏览器会认为是一个简单请求
a)请求方法属于下面的一种
- get
- post
- head
b)请求头仅包含安全的字段
- 常见的安全字段
- Accept
- Accept-Language
- Content-Language
- Content-Type
- DPR
- Downlink
- Save-Data
- Viewport-Width
- Width
c)请求头如果包含 Content-Type ,仅限下面的值之一
- text/plain
- multipart/form-data
- application/x-www-form-urlencoded(默认)
d)示例
// 简单请求
fetch("http://crossdomain.com/api/news");
// 请求方法不满足要求,不是简单请求
fetch("http://crossdomain.com/api/news", {
method: "PUT",
});
// 加入了额外的请求头,不是简单请求
fetch("http://crossdomain.com/api/news", {
headers: {
a: 1,
},
});
// 简单请求
fetch("http://crossdomain.com/api/news", {
method: "post",
});
// content-type不满足要求,不是简单请求
fetch("http://crossdomain.com/api/news", {
method: "post",
headers: {
"content-type": "application/json",
},
});
2)简单请求的交互规范
- 当浏览器判定某个 ajax 跨域请求 是简单请求时
a)请求头中会自动添加 Origin 字段
- 如:在页面
http://my.com/index.html中有以下代码造成了跨域
// 简单请求
fetch("http://crossdomain.com/api/news");
- 请求发出后,请求头会是下面的格式
GET /api/news/ HTTP/1.1
Host: crossdomain.com
Connection: keep-alive
...
Referer: http://my.com/index.html
Origin: http://my.com
- 最后一行
Origin字段会告诉服务器,是哪个源地址在跨域请求
b)服务器响应头中应包含 Access-Control-Allow-Origin
- 当服务器收到请求后,如果允许该请求跨域访问,需要在响应头中添加
Access-Control-Allow-Origin字段 - 该字段的值可以是
*:表示我很开放,什么人我都允许访问- 具体的源:如:
http://my.com,表示就允许该源访问
实际上,这两个值对于客户端
http://my.com而言都一样,因为客户端才不会管其他源服务器允不允许,就关心自己是否被允许当然,服务器也可以维护一个可被允许的源列表,如果请求的
Origin命中该列表,才响应*或具体的源为了避免后续的麻烦,强烈推荐响应具体的源
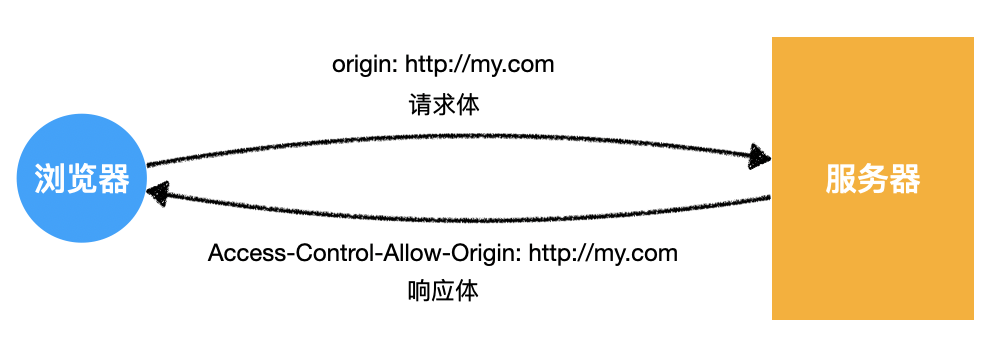
3.需要预检的请求
简单的请求对服务器的威胁不大,所以允许使用上述的简单交互即可完成
但是,如果浏览器不认为这是一种简单请求,就会按照下面的流程进行
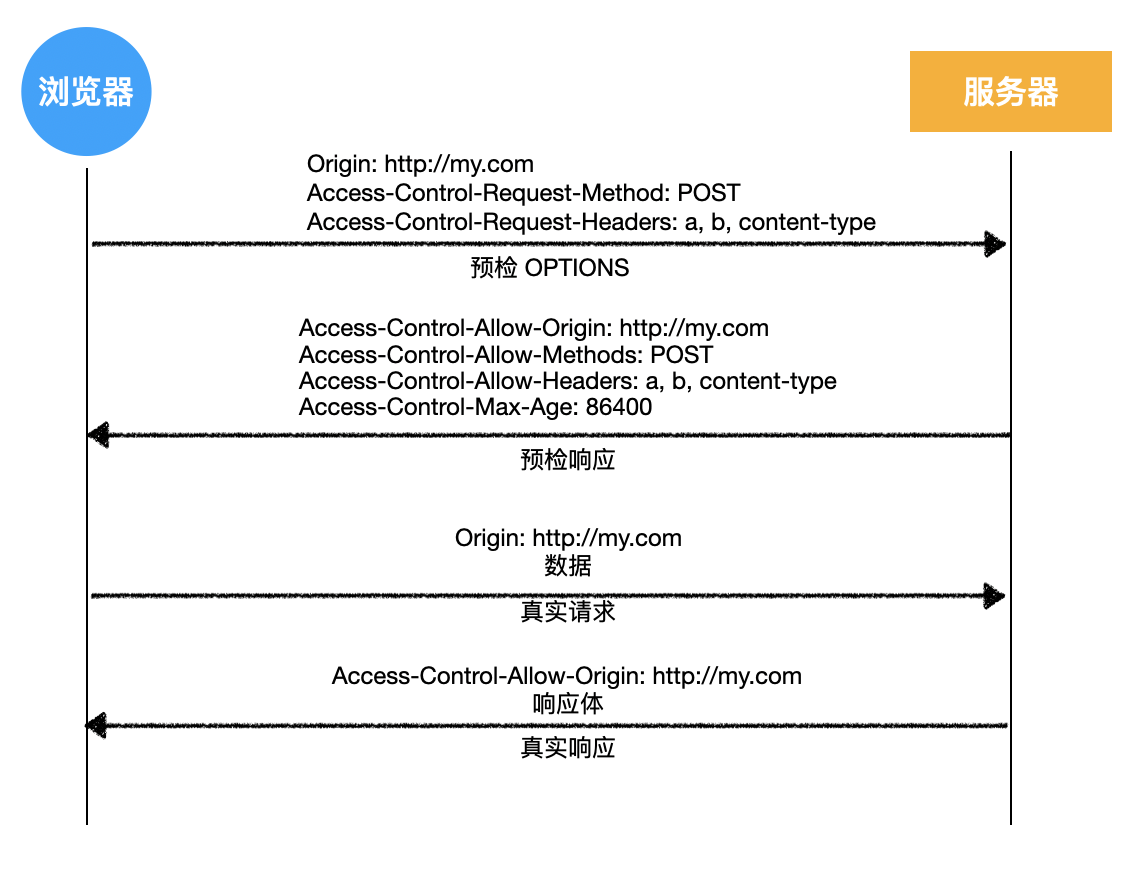
- 浏览器发送预检请求,询问服务器是否允许
- 服务器允许
- 浏览器发送真实请求
- 服务器完成真实的响应
// 需要预检的请求
fetch("http://crossdomain.com/api/user", {
method: "POST", // post 请求
headers: {
// 设置请求头
a: 1,
b: 2,
"content-type": "application/json",
},
body: JSON.stringify({ name: "袁小进", age: 18 }), // 设置请求体
});
- 浏览器发现它不是一个简单请求,则会按照下面的流程与服务器交互
1)浏览器发送预检请求,询问服务器是否允许
OPTIONS /api/user HTTP/1.1
Host: crossdomain.com
...
Origin: http://my.com
Access-Control-Request-Method: POST
Access-Control-Request-Headers: a, b, content-type
- 这并非想要发出的真实请求,请求中不包含请求头,也没有消息体
- 这是一个预检请求,目的是询问服务器,是否允许后续的真实请求
- 预检请求 没有请求体 ,包含了后续真实请求要做的事情
- 预检请求有以下特征
a)请求方法为 OPTIONS
b)没有请求体
c)请求头中包含
Origin:请求的源,和简单请求的含义一致Access-Control-Request-Method:后续的真实请求将使用的请求方法Access-Control-Request-Headers:后续的真实请求会改动的请求头
2)服务器允许
- 服务器收到预检请求后,可以检查预检请求中包含的信息
- 如果允许这样的请求,需要响应下面的消息格式
HTTP/1.1 200 OK
Date: Tue, 21 Apr 2020 08:03:35 GMT
...
Access-Control-Allow-Origin: http://my.com
Access-Control-Allow-Methods: POST
Access-Control-Allow-Headers: a, b, content-type
Access-Control-Max-Age: 86400
...
- 对于预检请求,不需要响应任何的消息体,只需要在响应头中添加
Access-Control-Allow-Origin:和简单请求一样,表示允许的源Access-Control-Allow-Methods:表示允许的后续真实的请求方法Access-Control-Allow-Headers:表示允许改动的请求头Access-Control-Max-Age:告诉浏览器,多少秒内,对于同样的请求源、方法、头,都不需要再发送预检请求了
3)浏览器发送真实请求
- 预检被服务器允许后,浏览器就会发送真实请求
POST /api/user HTTP/1.1
Host: crossdomain.com
Connection: keep-alive
...
Referer: http://my.com/index.html
Origin: http://my.com
{"name": "袁小进", "age": 18 }
4)服务器响应真实请求
HTTP/1.1 200 OK
Date: Tue, 21 Apr 2020 08:03:35 GMT
...
Access-Control-Allow-Origin: http://my.com
...
添加用户成功
- 完成预检后,后续的处理与简单请求相同
4.附带身份凭证的请求
- 默认情况下,ajax 的跨域请求并不会附带 cookie,某些需要权限的操作就无法进行
- 可以通过简单的配置实现附带 cookie
// xhr
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
// fetch api
fetch(url, {
credentials: "include",
});
- 该跨域的 ajax 请求就是一个附带身份凭证的请求
- 当一个请求需要附带 cookie 时,无论它是简单请求,还是预检请求,都会在请求头中添加
cookie字段 - 而服务器响应时,需要明确告知客户端:服务器允许这样的凭据
- 只需要在响应头中添加:
Access-Control-Allow-Credentials: true
- 只需要在响应头中添加:
- 对于一个附带身份凭证的请求,若服务器没有明确告知,浏览器仍然视为跨域被拒绝
- 对于附带身份凭证的请求,服务器不得设置
Access-Control-Allow-Origin的值为*- 这就是为什么不推荐使用
*的原因
- 这就是为什么不推荐使用
5.JS 访问指定的响应头
- 在跨域访问时,JS 只能拿到一些最基本的响应头
- 如:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma
- 如果要访问其他头,则需要服务器设置本响应头
Access-Control-Expose-Headers头让服务器把允许浏览器访问的头放入白名单
Access-Control-Expose-Headers: authorization, a, b
(十)跨域 —— JSONP
在 CORS 出现之前,人们想了一种奇妙的办法来实现跨域,这就是 JSONP
要实现 JSONP,需要浏览器和服务器来一个天衣无缝的绝妙配合
- 当需要跨域请求时,不使用 AJAX,转而生成一个 script 元素去请求服务器
- 由于浏览器并不阻止 script 元素的请求,这样请求可以到达服务器
- 服务器拿到请求后,响应一段 JS 代码,这段代码实际上是一个函数调用
- 调用的是客户端预先生成好的函数,并把浏览器需要的数据作为参数传递到函数中
- 从而间接的把数据传递给客户端
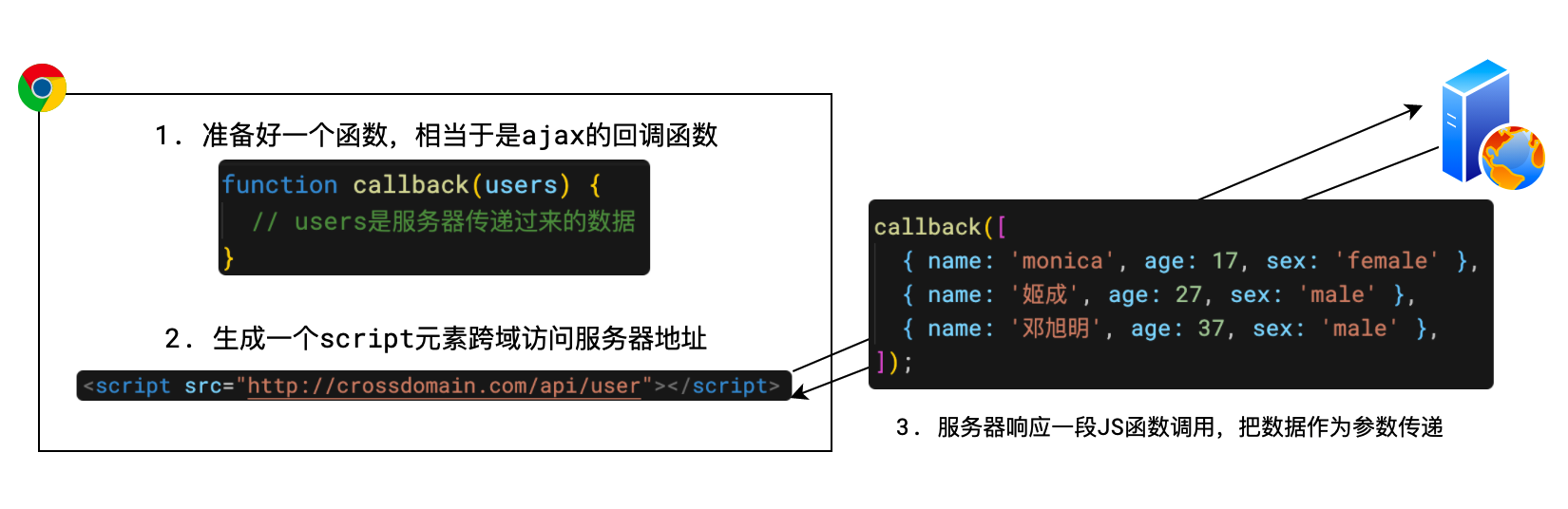
- JSONP 有着明显的缺点,只能支持 GET 请求
<button>点击获取用户</button>
<script>
function callback(resp) {
console.log(resp);
}
function request(url) {
const script = document.createElement("script");
script.src = url;
script.onload = function () {
script.remove();
};
document.body.appendChild(script);
}
document.querySelector("button").onclick = function () {
request("http://localhost:8000/api/user");
};
</script>
const express = require("express");
const app = express();
const path = "/api/user";
const users = [
{ name: "monica", age: 17, sex: "female" },
{ name: "姬成", age: 27, sex: "male" },
{ name: "邓旭明", age: 37, sex: "male" },
];
app.get(path, (req, res) => {
res.setHeader("content-type", "text/javascript");
res.send(`callback(${JSON.stringify(users)})`);
});
const port = 8000;
app.listen(port, () => {
console.log(`server listen on ${port}`);
console.log(`request for users: http://localhost:${port}${path}`);
});
(十一)文件上传
1.文件上传的消息格式
- 文件上传的本质仍然是一个数据提交,无非就是数据量大一些而已
在实践中,人们逐渐的形成了一种共识
自行规定,文件上传默认使用下面的请求格式
POST 上传地址 HTTP/1.1
其他请求头
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW
----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="avatar"; filename="小仙女.jpg"
Content-Type: image/jpeg
(文件二进制数据)
----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="username"
admin
----WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="password"
123123
----WebKitFormBoundary7MA4YWxkTrZu0gW
- 除非接口文档特别说明,文件上传一般使用 POST 请求
- 接口文档中会规定上传地址,一般 一个站点会有一个统一的上传地址
- 除非接口文档特别说明,一般设置
content-type: multipart/form-data- 浏览器会自动分配一个定界符
boundary
- 浏览器会自动分配一个定界符
- 请求体的格式是一个被定界符
boundary分割的消息,每个分割区域本质就是 一个键值对 - 除了键值对外,
multipart/form-data允许添加其他额外信息- 如:文件数据区域
- 一般会把 文件在本地的名称 和 文件 MIME 类型 告诉服务器
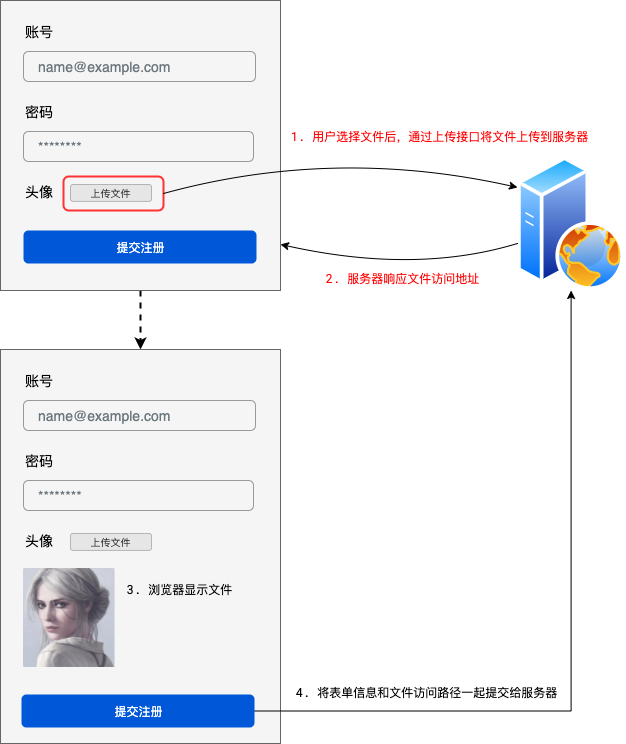
2.实现文件上传
- 在现代的网页交互中,带表单的文件上传通常使用下面的方式实现
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>文件上传</title>
<style>
* {
box-sizing: border-box;
}
.form-container {
width: 400px;
margin: 0 auto;
background: #eee;
border-radius: 5px;
border: 1px solid #ccc;
padding: 30px;
}
.form-item {
margin: 1.5em 0;
}
.title {
height: 30px;
line-height: 30px;
}
input {
width: 100%;
height: 30px;
font-size: inherit;
}
img {
max-width: 200px;
max-height: 250px;
margin-top: 1em;
border-radius: 5px;
}
.submit {
width: 100%;
background: #0057d8;
color: #fff;
border: 1px solid #0141a0;
border-radius: 5px;
height: 40px;
font-size: inherit;
transition: 0.2s;
}
.submit:hover {
background: #0061f3;
border: 1px solid #0057d8;
}
</style>
</head>
<body>
<div class="form-container">
<div class="form-item">
<div class="title">账号</div>
<input id="username" type="text" />
</div>
<div class="form-item">
<div class="title">密码</div>
<input id="password" type="password" />
</div>
<div class="form-item">
<div class="title">
头像
<button id="btnupload">上传文件</button>
<input id="fileUploader" type="file" style="display: none" />
</div>
<img id="avatar" src="" alt="" />
</div>
<div class="form-item">
<button class="submit">提交注册</button>
</div>
</div>
<script>
const doms = {
username: document.querySelector("#username"),
password: document.querySelector("#password"),
btnUpload: document.querySelector("#btnupload"),
fileUploader: document.querySelector("#fileUploader"),
submit: document.querySelector(".submit"),
avatar: document.querySelector("#avatar"),
};
doms.btnUpload.onclick = function () {
doms.fileUploader.click();
};
doms.fileUploader.onchange = async function () {
// 一般先会在这里对文件进行验证
// console.log(doms.fileUploader.files);
// 上传文件
const formData = new FormData();
formData.append("file", doms.fileUploader.files[0]); // 添加一个键值对
const resp = await fetch("http://localhost:8000/api/upload", {
method: "POST",
body: formData,
}).then((resp) => resp.json());
doms.avatar.src = resp.data;
};
doms.submit.onclick = async function () {
const resp = await fetch("http://localhost:8000/api/user/reg", {
method: "POST",
headers: {
"content-type": "application/json",
},
body: JSON.stringify({
username: doms.username.value,
password: doms.password.value,
avatar: doms.avatar.src,
}),
}).then((resp) => resp.json());
console.log(resp);
};
</script>
</body>
</html>
3.统一上传接口
1)接口文档
| 参数 | 取值 |
|---|---|
| 请求路径 | /api/upload |
| 请求方法 | POST |
| 字段名 | file |
| 尺寸限制 | 1M |
| 支持的文件后缀 | .jpg, .jpeg, .gif, .png, .bmp, .webp |
- 上传成功的响应
{
"code": 0,
"msg": "",
"data": "http://localhost:8000/upload/a32d18.jpg" // 访问路径
}
- 可能发生的失败响应
{
"code": 403,
"msg": "文件超过了限制",
"data": null
}
{
"code": 403,
"msg": "无效的文件类型",
"data": null
}
2)实现
const express = require("express");
const router = express.Router();
const path = require("path");
const config = {
fieldName: "file",
sizeLimit: 1 * 1024 * 1024,
extends: [".jpg", ".jpeg", ".gif", ".png", ".bmp", ".webp"],
saveDir: path.resolve(__dirname, "./public/upload"),
createFilename(ext) {
if (!ext.startsWith(".")) {
ext = "." + ext;
}
const rad = Math.random().toString(36).substr(2);
const time = new Date().getTime().toString(36);
return rad + time + ext;
},
};
const multer = require("multer");
const storage = multer.diskStorage({
destination: function (req, file, cb) {
cb(null, config.saveDir);
},
filename: function (req, file, cb) {
const ext = path.extname(file.originalname);
cb(null, config.createFilename(ext));
},
});
class ExtendNameError extends Error {}
const upload = multer({
storage,
fileFilter(req, file, cb) {
const ext = path.extname(file.originalname);
if (config.extends.includes(ext)) {
cb(null, true);
} else {
cb(new ExtendNameError("无效的文件类型"));
}
},
limits: {
fileSize: config.sizeLimit,
},
}).single(config.fieldName);
router.post("/", (req, res) => {
upload(req, res, function (err) {
if (err) {
let msg;
switch (err.message) {
case "File too large":
msg = "文件大小超过了限制";
break;
case "Unexpected field":
msg = `无法找到${fieldName}字段`;
break;
}
if (err instanceof ExtendNameError) {
msg = err.message;
}
res.send({
code: 403,
msg,
data: null,
});
} else {
res.send({
code: 0,
msg: "",
data: `${req.protocol}://${req.hostname}:${require("./config").port}/upload/${req.file.filename}`,
});
}
});
});
module.exports = router;
4.用户注册接口
1)接口文档
| 参数 | 取值 |
|---|---|
| 请求路径 | /api/user/reg |
| 请求方法 | POST |
| 支持的消息类型 | x-www-form-urlencoded json |
- 字段
| 字段名 | 含义 | 是否必须 |
|---|---|---|
| username | 账号 | 是 |
| password | 密码 | 是 |
| avatar | 头像 | 是 |
- 注册成功的响应
{
"code": 0,
"msg": "",
"data": {
"username": "monica",
"avatar": "http://localhost:8000/upload/a234wq1.jpg"
}
}
2)实现
const express = require("express");
const router = express.Router();
const users = [];
router.post("/reg", (req, res) => {
users.push(req.body);
res.send({
code: 0,
msg: "",
data: {
username: req.body.username,
avatar: req.body.avatar,
},
});
});
module.exports = router;
(十二)输入 URL 地址后
1.面试题
1)在浏览器地址栏输入地址,并按下回车键后,发生了哪些事情?
- 浏览器自动补全协议、端口
- 浏览器自动完成 url 编码
- 浏览器根据 url 地址查找本地缓存,根据缓存规则看是否命中缓存,若命中缓存则直接使用缓存,不再发出请求
- 通过 DNS 解析找到服务器的 IP 地址
- 浏览器向服务器发出建立 TCP 连接的申请,完成三次握手后,连接通道建立
- 若使用了 HTTPS 协议,则还会进行 SSL 握手,建立加密信道。使用 SSL 握手时,会确定是否使用 HTTP2
- 浏览器决定要附带哪些 cookie 到请求头中
- 浏览器自动设置好请求头、协议版本、cookie,发出 GET 请求
- 服务器处理请求,进入后端处理流程。完成处理后,服务器响应一个 HTTP 报文给浏览器
- 浏览器根据使用的协议版本,以及 Connection 字段的约定,决定是否要保留 TCP 连接
- 浏览器根据响应状态码决定如何处理这一次响应
- 浏览器根据响应头中的 Content-Type 字段识别响应类型,如果是 text/html,则对响应体的内容进行 HTML 解析,否则做其他处理
- 浏览器根据响应头的其他内容完成缓存、cookie 的设置
- 浏览器开始从上到下解析 HTML,若遇到外部资源链接,则进一步请求资源
- 解析过程中生成 DOM 树、CSSOM 树,然后一边生成,一边把二者合并为渲染树(rendering tree),随后对渲染树中的每个节点计算位置和大小(reflow),最后把每个节点利用 GPU 绘制到屏幕(repaint)
- 在解析过程中还会触发一系列的事件,当 DOM 树完成后会触发 DOMContentLoaded 事件,当所有资源加载完毕后会触发 load 事件
(十三)文件下载
1.文件下载的消息格式
- 服务器触发浏览器的下载功能,只需要在响应头中加入
Content-Disposition: attachment; filename="xxx"
1)attachment
- 表示附件
- 浏览器看到此字段,触发下载行为
- 不同的浏览器下载行为有所区别
2)filename="xxx"
- 告诉浏览器,保存文件时使用的默认文件名
2.启用迅雷下载
用户可能安装了某些下载工具,这些下载工具在安装时,都会自动安装相应的浏览器插件
只要对下载地址稍作修改,就会触发浏览器使用插件进行下载
不同插件的地址规则不同
- 迅雷的下载地址规则为
thunder://base64(AA地址ZZ)
<a data-res="thunder" href="http://localhost:8000/download/Wallpaper1.jpg">下载桌面壁纸1</a>
<a data-res="thunder" href="http://localhost:8000/download/Wallpaper2.jpg">下载桌面壁纸2</a>
<script>
const links = document.querySelectorAll("[data-res=thunder]");
for (const link of links) {
const base64 = btoa(`AA${link.href}ZZ`);
const href = `thunder://${base64}`;
link.href = href;
}
</script>
3.服务器下载接口
const express = require("express");
const path = require("path");
const app = express();
const port = 8000;
app.get("/download/:filename", (req, res) => {
const filename = path.join(__dirname, "./res", req.params.filename);
res.download(filename, req.params.filename);
});
app.listen(port, () => {
console.log(`server listen on ${port}`);
});
(十四)session
1.cookie 的缺陷
- cookie 是保存在客户端的,虽然为服务器减少了很多压力,但某些情况下,会出现麻烦
- 如:验证码
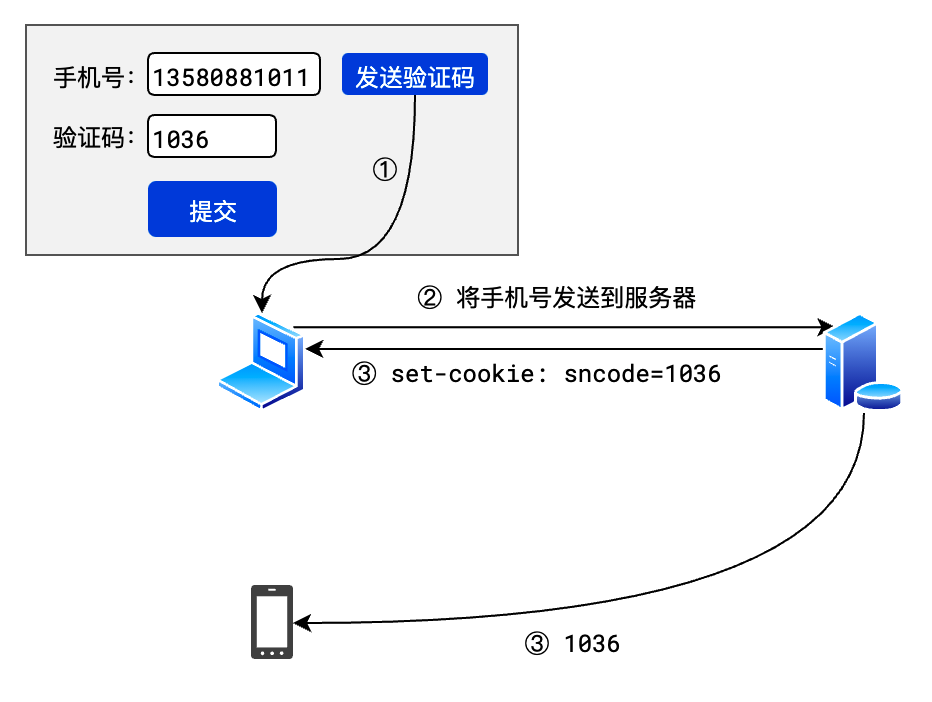
如果这样做,客户端可以随便填写一个别人的手机号
然后从 cookie 中获取到验证码,从而绕开整个验证
因此,有些敏感数据是万万不能发送给客户端的
2.session 流程
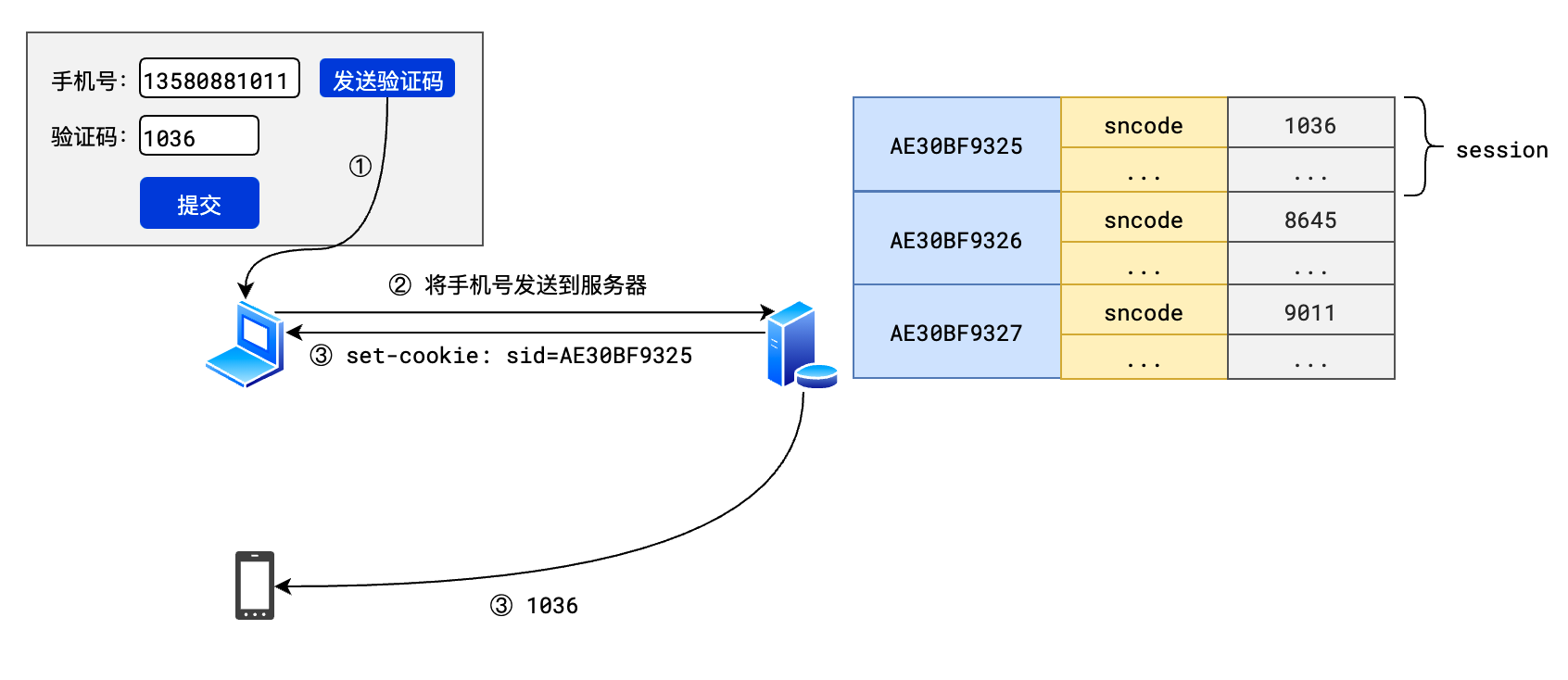
- session 也是键值对
- 保存在服务器端,通过 sessionid 和客户端关联
3.面试题
1)cookie 和 session 的区别是什么?
- cookie 的数据保存在浏览器端;session 的数据保存在服务器
- cookie 的存储空间有限;session 的存储空间不限
- cookie 只能保存字符串;session 可以保存任何类型的数据
- cookie 中的数据容易被获取;session 中的数据难以获取
2)如何消除 session
- 过期时间
当客户端长时间没有传递 sessionid 过来时,服务器可以在过期时间之后自动清除 session
- 客户端主动通知
可以使用 JS 监听客户端页面关闭或其他退出操作,然后通知服务器清除 session
(十五)HTTP 缓存协议
1.缓存的基本原理
- 在一个 C/S 结构中,最基本的缓存分为两种
- 客户端缓存
- 服务器缓存
1)客户端缓存
- 将某一次的响应结果保存在客户端(如:浏览器)中
- 而后续的请求仅需要从缓存中读取即可
- 极大的降低了服务器的处理压力
2)客户端缓存的原理
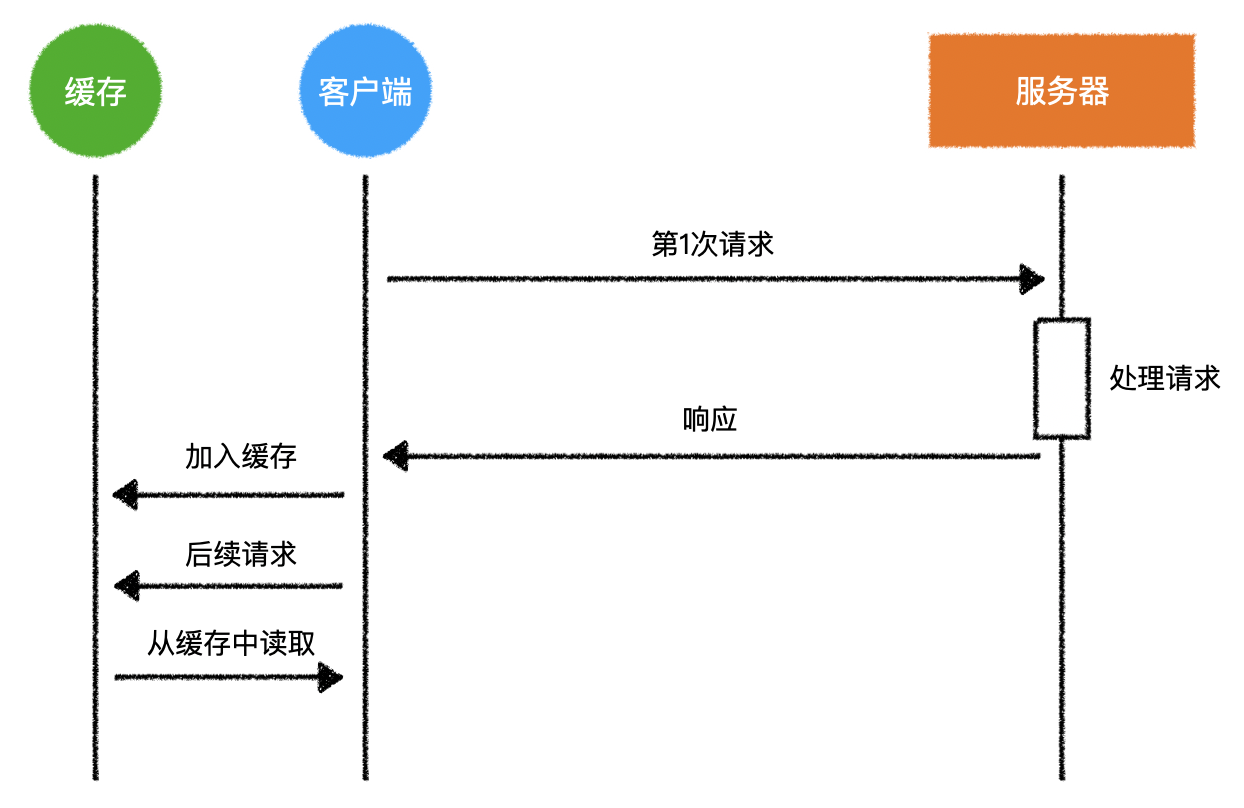
3)缓存策略的问题
- 哪些资源需要加入到缓存,哪些不需要?
- 缓存的时间是多久呢?
- 如果服务器的资源有改动,客户端如何更新缓存呢?
- 如果缓存过期了,可是服务器上的资源并没有发生变动,又该如何处理呢?
- .......
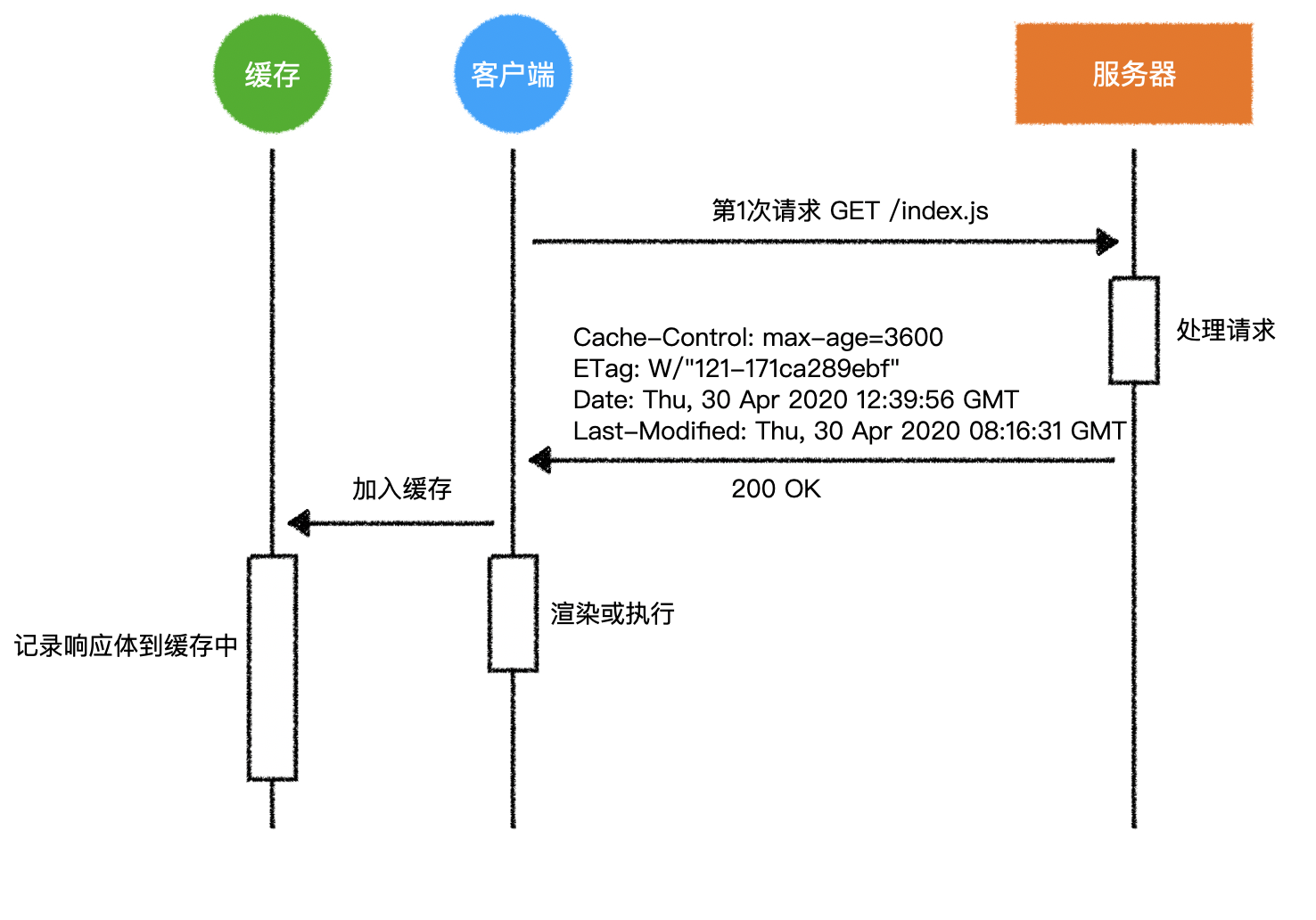
2.来自服务器的缓存指令
3.来自客户端的缓存指令
客户端会到缓存中去寻找是否有缓存的资源
寻找的过程如下
- 缓存中是否有匹配的请求方法和路径?
- 如果有,该缓存资源是否还有效呢?
以上两个验证会导致浏览器产生不同的行为
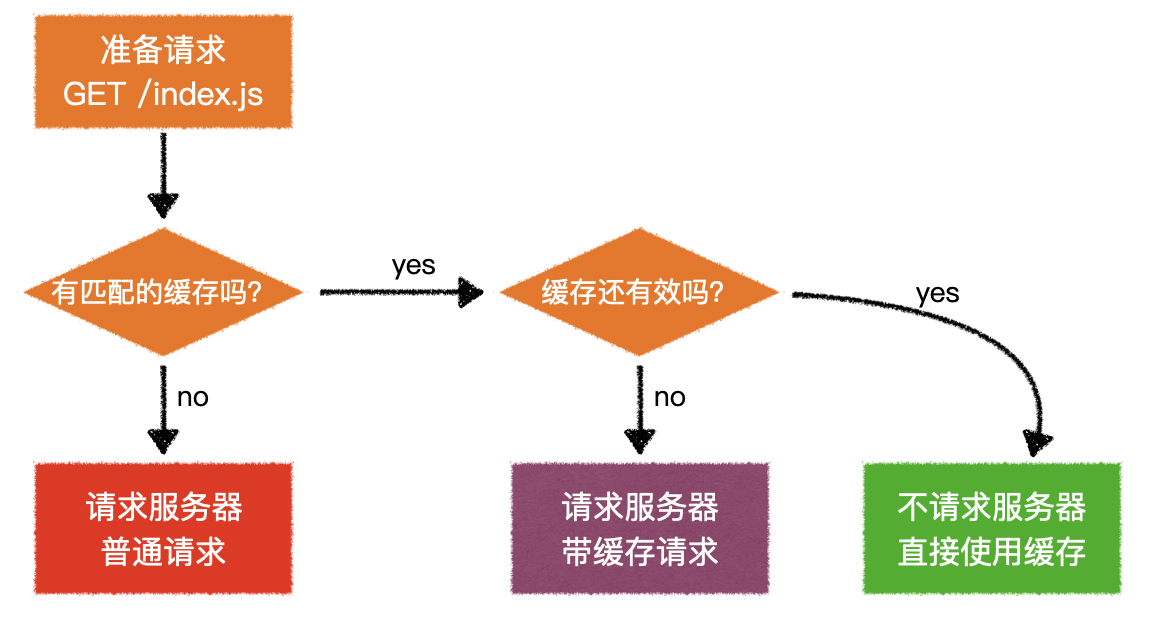
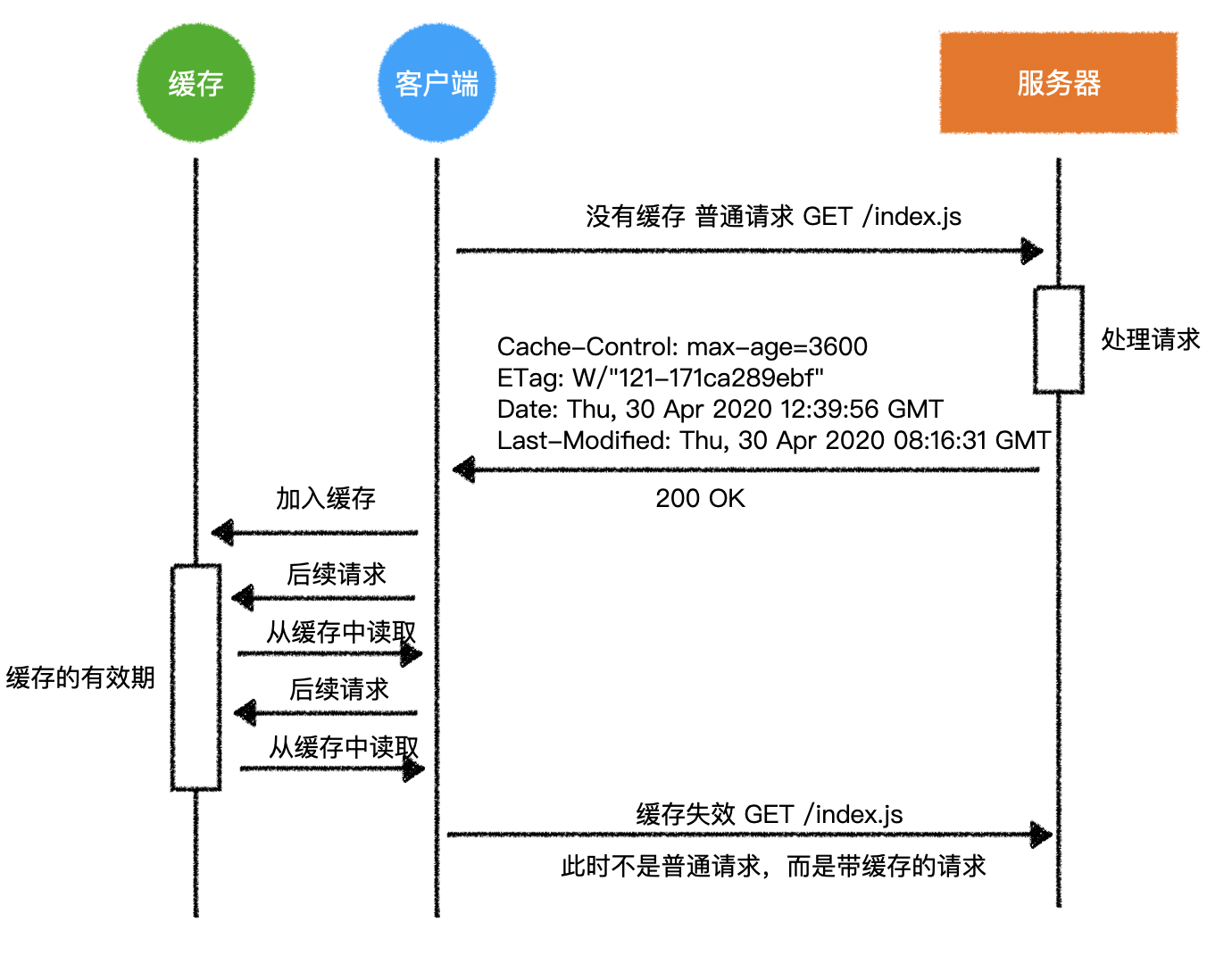
1)验证是否有匹配的缓存
- 只需要验证当前的请求方法
GET和当前的请求路径/index.js是否有对应的缓存存在即可 - 如果没有,就直接请求服务器
2)验证缓存是否有效
max-age + Date,得到一个过期时间- 看看这个过期时间是否大于当前时间
- 如果是,则表示缓存还没有过期,仍然有效
- 如果不是,则表示缓存失效
3)缓存有效
- 当浏览器发现缓存有效时,完全不会请求服务器,直接使用缓存即可得到结果
此时,如果断开网络,会发现资源仍然可用
- 这种情况会极大的降低服务器压力
- 但当服务器更改了资源后,浏览器是不知道的
- 只要缓存有效,就会直接使用缓存
4)缓存无效
- 当浏览器发现缓存已经过期,并不会简单的把缓存删除
- 而是向服务器发出了一个 带缓存的请求,又称为 协商缓存
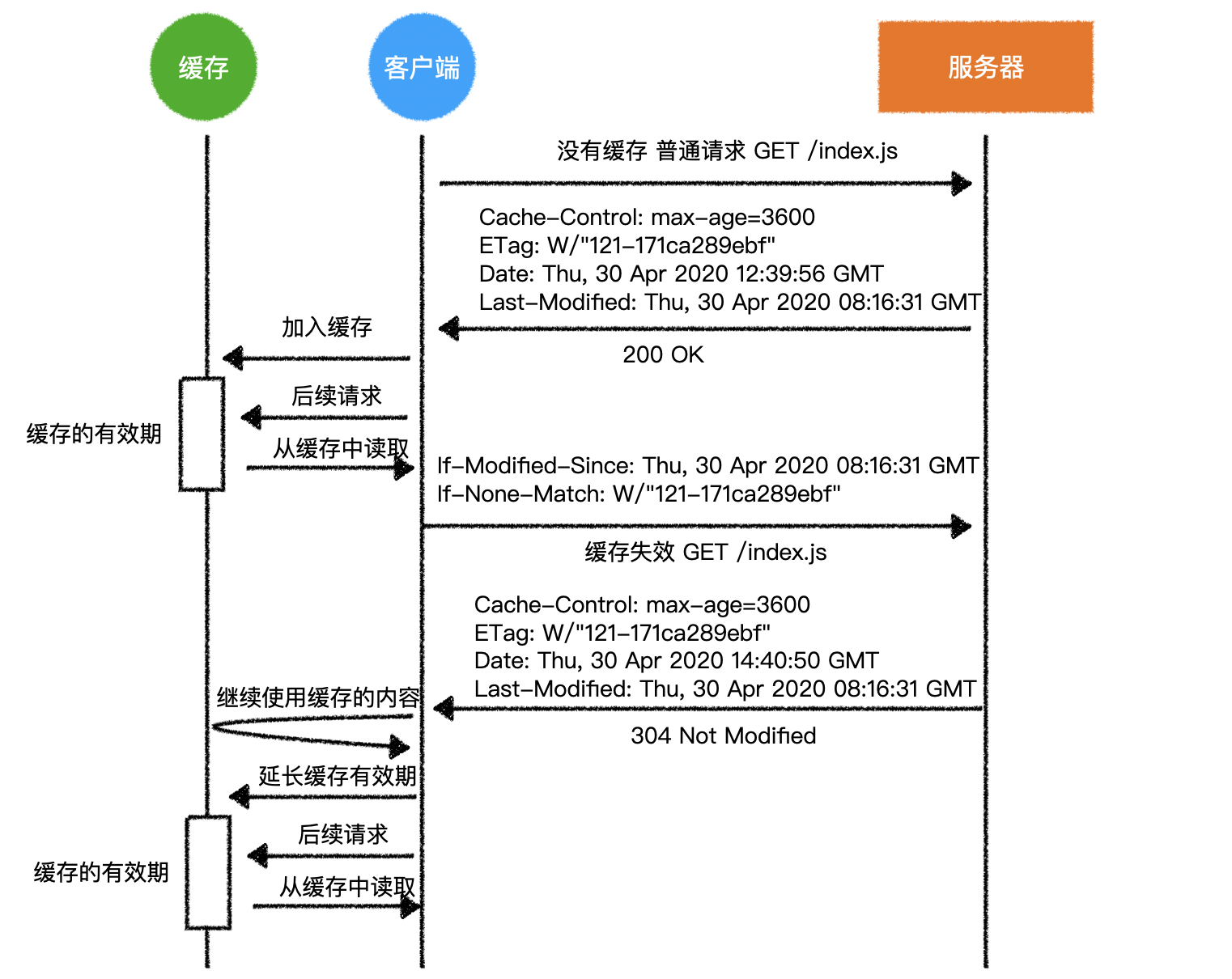
- 就是加入了以下的请求头
If-Modified-Since: Thu, 30 Apr 2020 08:16:31 GMT
If-None-Match: W/"121-171ca289ebf"
之所以要发两个信息,是为了兼容不同的服务器
因为有些服务器只认
If-Modified-Since,有些服务器只认If-None-Match,有些服务器两个都认目前的很多服务器,只要发现
If-None-Match存在,就不会去看If-Modified-Since
If-Modified-Since是 http1.0 版本的规范,If-None-Match是 http1.1 的规范
- 服务器可能会产生两个情况
a)缓存已经失效
- 服务器再次给予一个正常的响应(响应码 200,带响应体)
- 同时可以附带上新的缓存指令
- 客户端重新缓存新的内容
这就回到了上一节——来自服务器的缓存指令
b)缓存仍然有效
- 响应码为
304 Not Modified,无响应体 - 响应头带上新的缓存指令
- 客户端继续使用缓存
可以最大程度的减少网络传输,因为如果资源还有效,服务器就不会传输消息体
- 完整的交互过程
4.Cache-Control
- Cache-Control 是服务器向客户端响应的一个消息头,提供了一个
max-age用于指定缓存时间 - Cache-Control 还可以设置下面一个或多个值
1)public
- 指示服务器资源是公开的
有一个页面资源,所有人看到的都是一样的。这个值对于浏览器而言没有什么意义,但可能在某些场景可能有用。本着「我告知,你随意」的原则,http 协议中很多时候都是客户端或服务器告诉另一端详细的信息,至于另一端用不用,完全看它自己
2)private
- 指示服务器资源是私有的
有一个页面资源,每个用户看到的都不一样。这个值对于浏览器而言没有什么意义,但可能在某些场景可能有用。本着「我告知,你随意」的原则,http 协议中很多时候都是客户端或服务器告诉另一端详细的信息,至于另一端用不用,完全看它自己
3)no-cache
- 告知客户端可以缓存这个资源,但是不要 直接 使用
- 缓存之后,后续的每一次请求都需要附带缓存指令,让服务器验证这个资源有没有过期
4)no-store
- 告知客户端不要对这个资源做任何的缓存,之后的每一次请求都按照正常的普通请求进行
- 若设置了这个值,浏览器将不会对该资源做出任何的缓存处理
5)max-age
5.Expires
- 在 http1.0 版本中,是通过 Expires 响应头来指定过期时间点的
Expires: Thu, 30 Apr 2020 23:38:38 GMT
- 到了 http1.1 版本,已更改为通过 Cache-Control 的 max-age 来记录
6.记录缓存时的有效期
- 浏览器会按照服务器响应头的要求,自动记录缓存到本地文件,并设置各种相关信息
- 在这些信息中, 有效期 尤为关键,决定了这个缓存可以使用多久
- 浏览器会根据服务器不同的响应情况,设置不同的有效期
- 具体的有效期设置,按照下面的流程进行
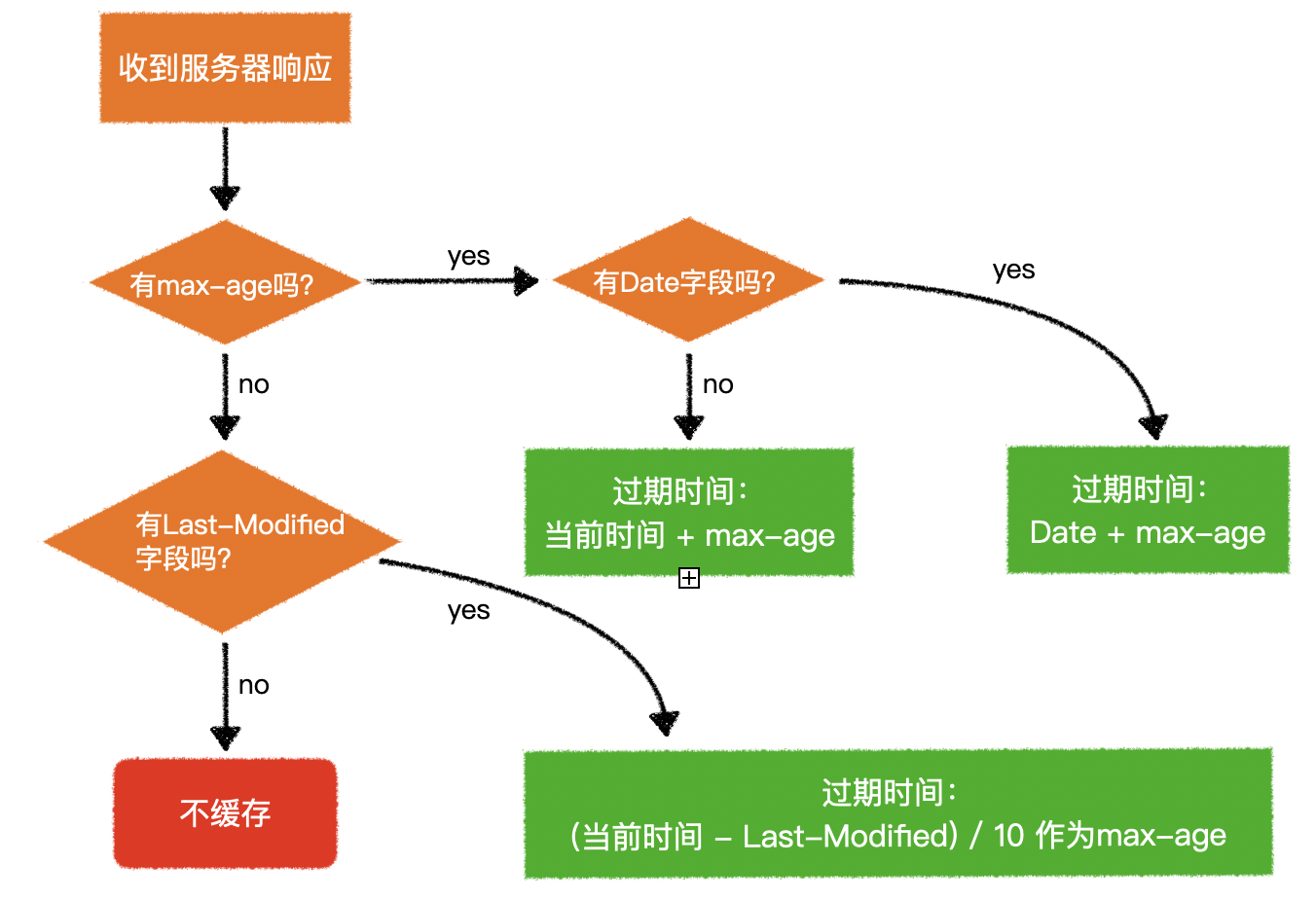
- 如:当
max-age设置为 0 时,缓存立即过期 - 虽然立即过期,但缓存仍然被记录下来
- 后续的请求通过缓存指令发送到服务器,来确认资源是否被更改
- 因此,
Cache-Control: max-age=0类似于Cache-Control: no-cache
7.Pragma
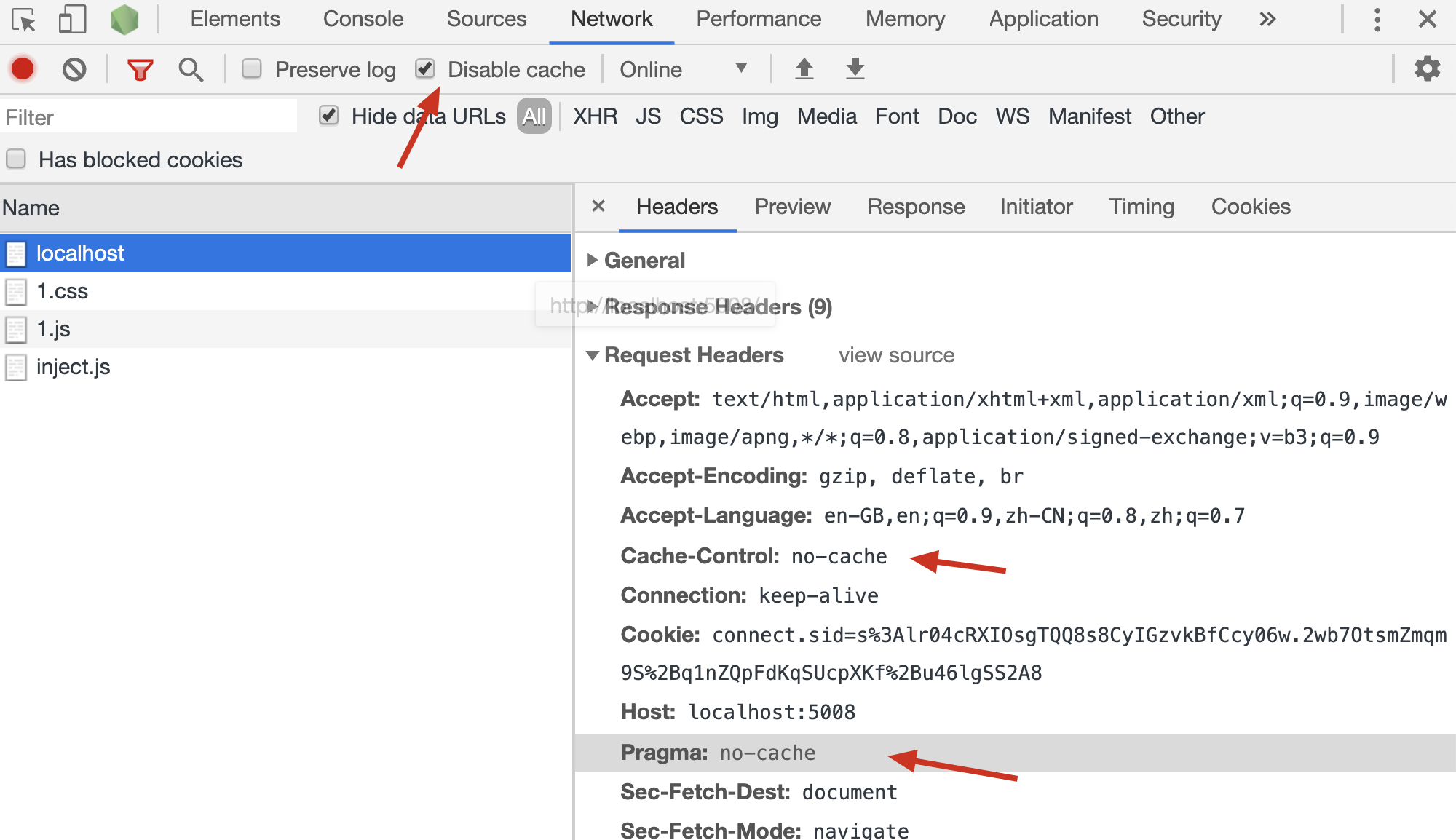
- 这是 http1.0 版本的消息头
- 当该消息头出现在请求中时,是向服务器表达:不要考虑任何缓存,返回一个正常的结果
- 在 http1.1 版本中,可以在 请求头 中加入
Cache-Control: no-cache实现同样的含义
在 Chrome 浏览器中调试时,如果勾选了
Disable cache,则发送的请求中会附带该信息
8.Vary
- 是否有缓存,不仅仅是判断请求方法和请求路径是否匹配,可能还要判断头部信息是否匹配
- 可以使用
Vary字段来 指定要区分的消息头 - 如:当使用
GET /personal.html请求服务器时,请求头中 cookie 的值不一样,得到的页面也不一样- 如果仅仅匹配请求方法和请求路径,一旦 cookie 变动,得到的仍然是之前的页面
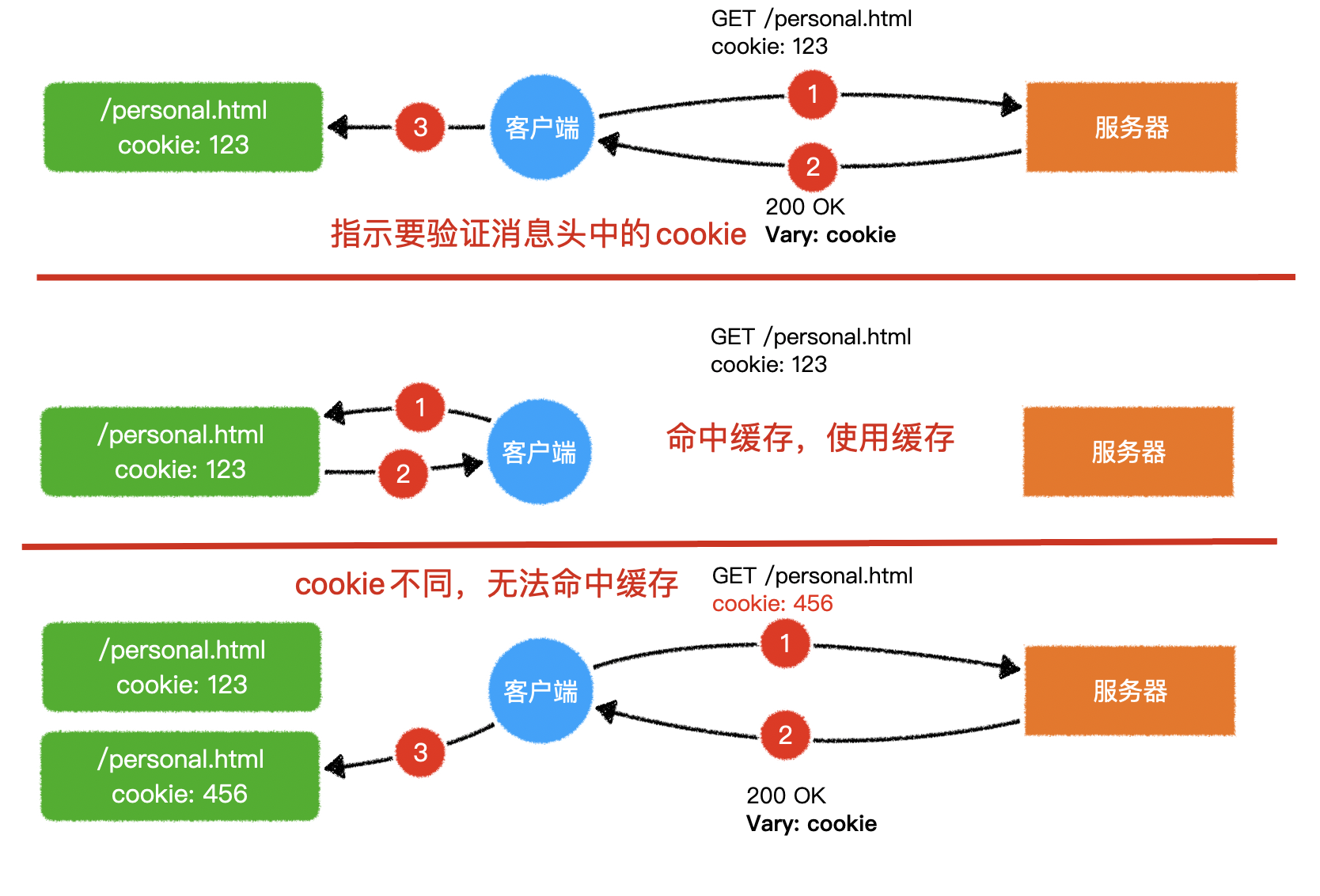
9.使用版本号或 hash
- vue 或其他基于 webpack 搭建的工程打包的结果中很多文件名
app.68297cd8.css- 文件的中间部分使用了
hash值
- 文件的中间部分使用了
- 可以让客户端大胆的、长时间的缓存该文件,减轻服务器的压力
- 当文件改动后,文件 hash 值也会随之而变,如:变成了
app.446fccb8.css - 客户端要请求新的文件时,就会发现路径从
/app.68297cd8.css变成了app.446fccb8.css - 由于之前的缓存路径无法匹配到,因此就会发送新的请求来获取新资源了
- 当文件改动后,文件 hash 值也会随之而变,如:变成了
- 还没有构建工具出现时,人们使用的办法是 在资源路径后面加入版本号 来获取新版本的文件
- 如:页面中引入了一个 css 资源
app.css
<link href="/app.css?v=1.0.0" />
- 缓存的路径是
/app.css?v=1.0.0 - 当服务器的版本发生变化时,可以给予新的版本号,让 html 中的路径发生变动
<link href="/app.css?v=1.0.1" />
- 由于新的路径无法命中缓存,于是浏览器就会发送新的普通请求来获取这个资源
10.总结
1)服务器视角
- 服务器无法知道客户端到底有没有像浏览器那样缓存文件
- 只管根据请求的情况来决定如何响应
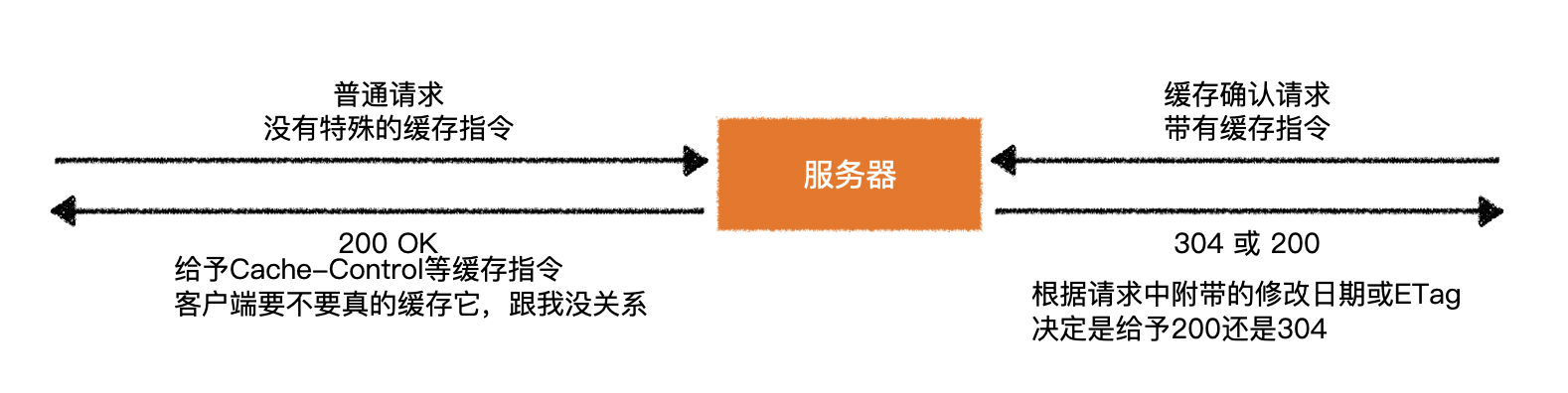
- 很多后端语言搭建的服务器都会自带自己的默认缓存规则,当然也支持不同程度的修改
2)浏览器视角
- 浏览器在发出请求时会判断要不要使用缓存
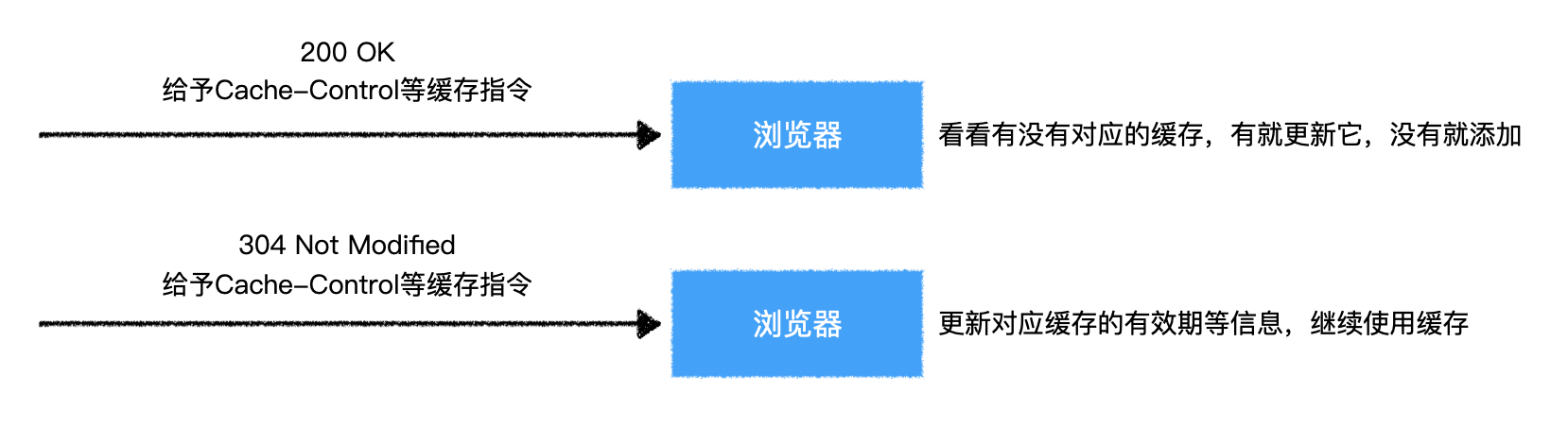
- 当收到服务器响应时,会自动根据缓存指令进行处理
(十六)TCP 协议
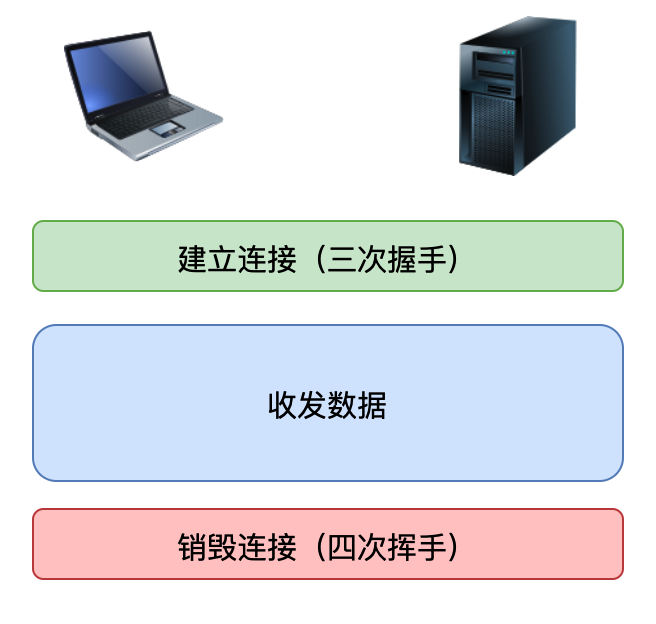
1.TCP 收发数据流程
2.TCP 如何收发数据
1)分段发送
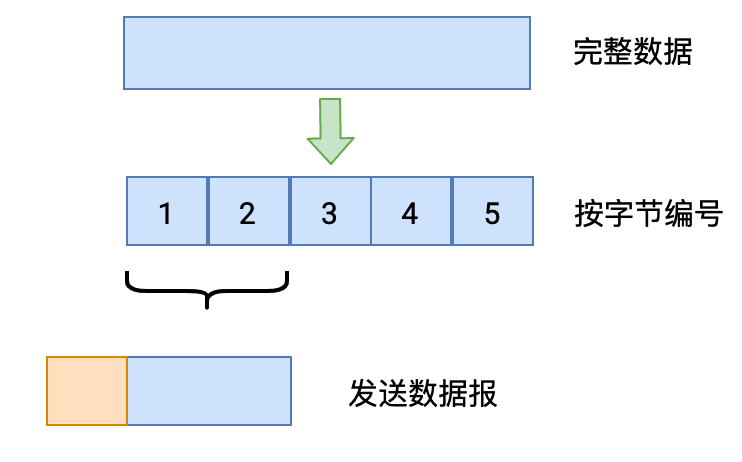
2)可靠传输
- 在 TCP 协议中,任何时候、任何一方都可以主动发送数据给另一方
- 为了解决数据报丢失、数据报错乱等问题 TCP 协议要求:接收方收到数据报后,必须对数据报进行确认
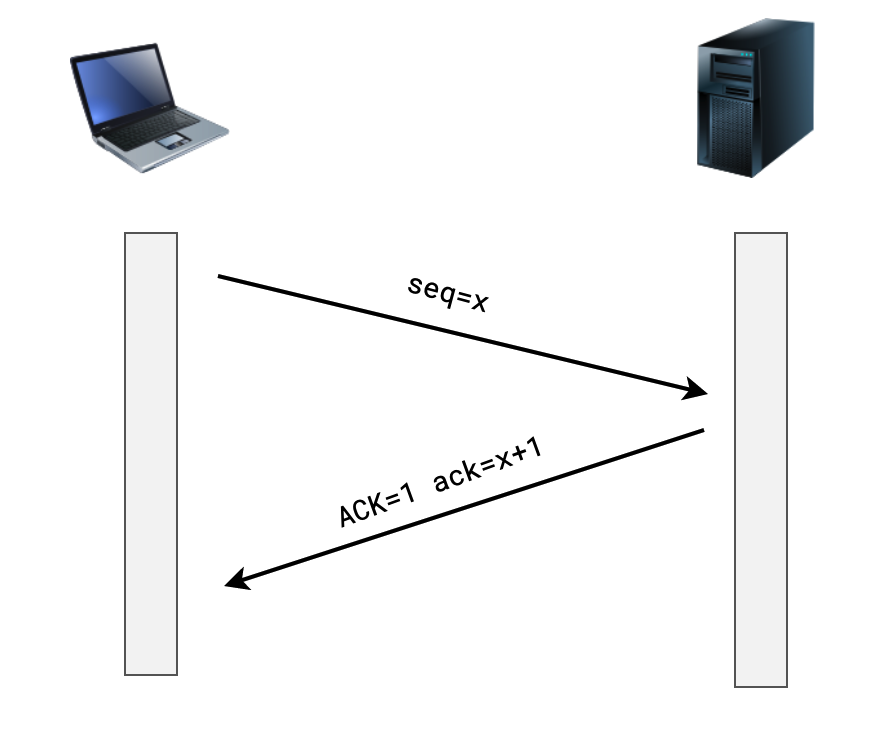
- seq:表示这次数据报的序号
- ACK:表示这次数据报是一个确认数据报
- ack:表示期望下一次接收的数据报序号
- 发送方如果长时间没有收到确认数据报(ACK=1)
- 则会判定丢失或者是错误,然后重发
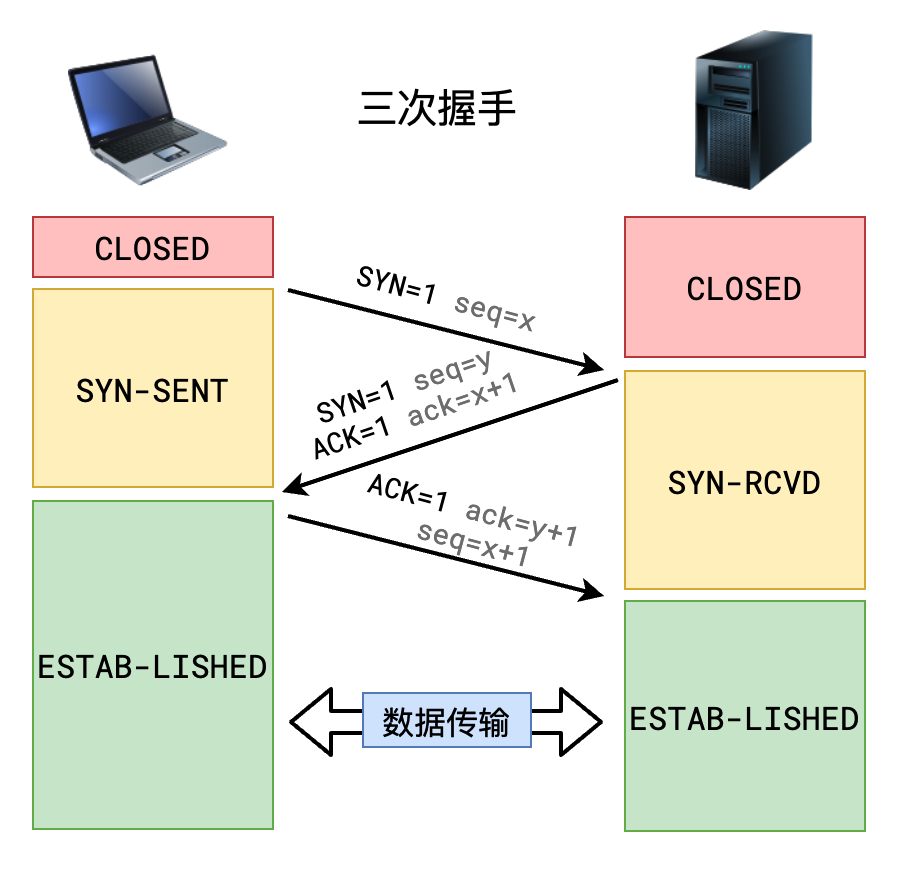
3.连接的建立(三次握手)
- TCP 协议要实现数据的收发,必须要先建立连接
- 连接的本质其实就是双方各自开辟的一块儿内存空间,空间中主要是数据缓冲区和一些变量
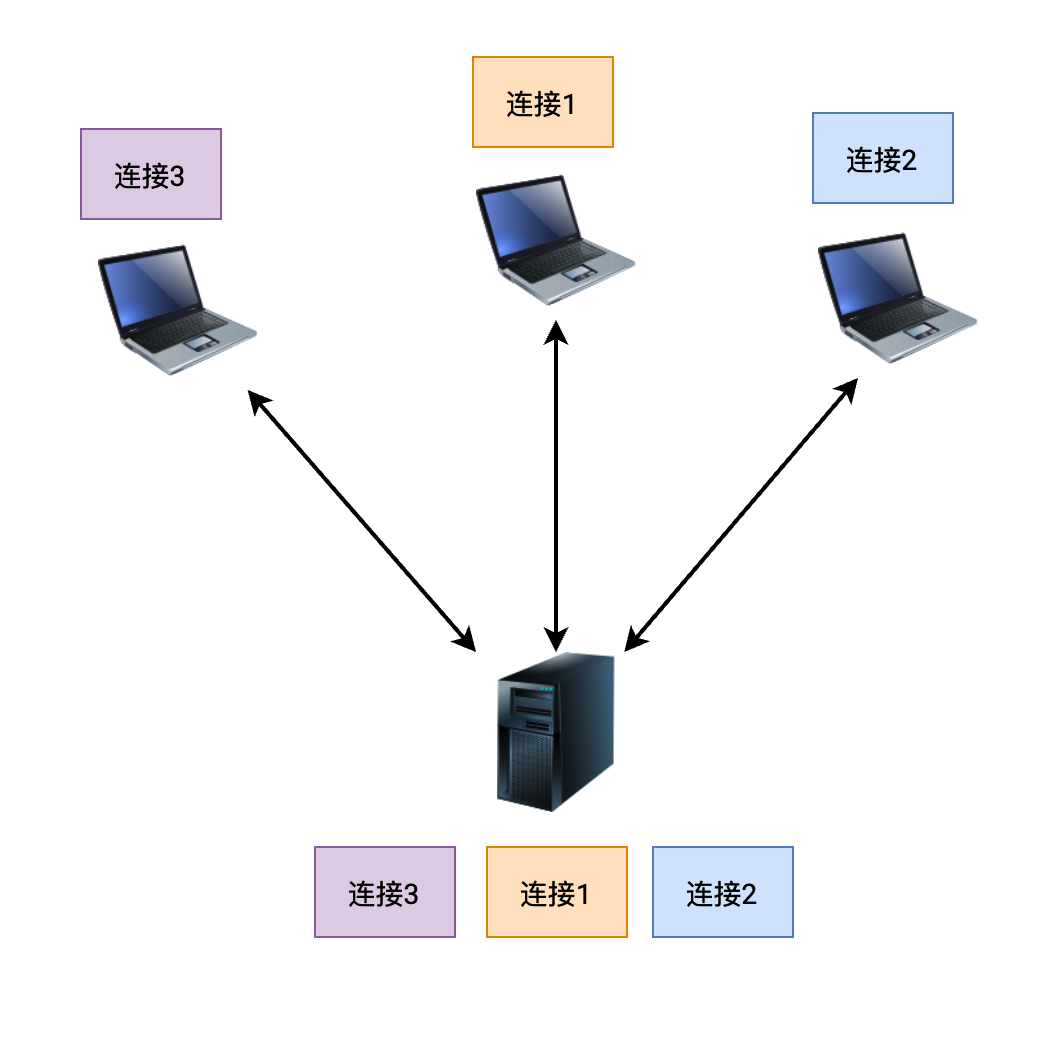
- 连接建立的过程需要经过三次数据报传输,因此称为三次握手
开始
客户端:我说话能听见吗?
服务器:能听见,我说话能听见吗?
客户端:能听见
结束
4.连接的销毁(四次挥手)
开始
客户端:我说完了,挂了?
服务器:我明白你说完了,但别忙挂,我还有话要说。
服务器继续说......
服务器:我也说完了,挂了?
客户端:好的!
结束
5.HTTP 和 TCP 的关系

- HTTP 协议是对内容格式的规定,使用 了 TCP 协议完成消息的可靠传输
- 在具体使用 TCP 协议时
- 客户端发消息给服务器叫做请求,服务器发消息给客户端叫做响应
- 使用 HTTP 协议的服务器不会主动发消息给客户端(尽管 TCP 可以),只对请求进行响应
- 每一个 HTTP 请求-响应,都要先建立 TCP 连接(三次握手),然后完成请求-响应后,再销毁连接(四次挥手)
- 这就导致每次请求-响应都是相互独立的,无法保持状态
6.面试题
1)简述 TCP 连接的过程(淘系)
TCP 协议通过三次握手建立可靠的点对点连接,具体过程是:
- 首先服务器进入监听状态,然后即可处理连接
- 第一次握手:建立连接时,客户端发送 syn 包到服务器,并进入 SYN_SENT 状态,等待服务器确认。在发送的包中还会包含一个初始序列号 seq。此次握手的含义是客户端希望与服务器建立连接
- 第二次握手:服务器收到 syn 包,然后回应给客户端一个 SYN+ACK 包,此时服务器进入 SYN_RCVD 状态。此次握手的含义是服务端回应客户端,表示已收到并同意客户端的连接请求
- 第三次握手:客户端收到服务器的 SYN 包后,向服务器再次发送 ACK 包,并进入 ESTAB_LISHED 状态
- 最后,服务端收到客户端的 ACK 包,于是也进入 ESTAB_LISHED 状态,至此,连接建立完成
2)谈谈你对 TCP 三次握手和四次挥手的理解
TCP 协议通过三次握手建立可靠的点对点连接,具体过程是:
- 首先服务器进入监听状态,然后即可处理连接
- 第一次握手:建立连接时,客户端发送 syn 包到服务器,并进入 SYN_SENT 状态,等待服务器确认。在发送的包中还会包含一个初始序列号 seq。此次握手的含义是客户端希望与服务器建立连接
- 第二次握手:服务器收到 syn 包,然后回应给客户端一个 SYN+ACK 包,此时服务器进入 SYN_RCVD 状态。此次握手的含义是服务端回应客户端,表示已收到并同意客户端的连接请求
- 第三次握手:客户端收到服务器的 SYN 包后,向服务器再次发送 ACK 包,并进入 ESTAB_LISHED 状态
- 最后,服务端收到客户端的 ACK 包,于是也进入 ESTAB_LISHED 状态,至此,连接建立完成
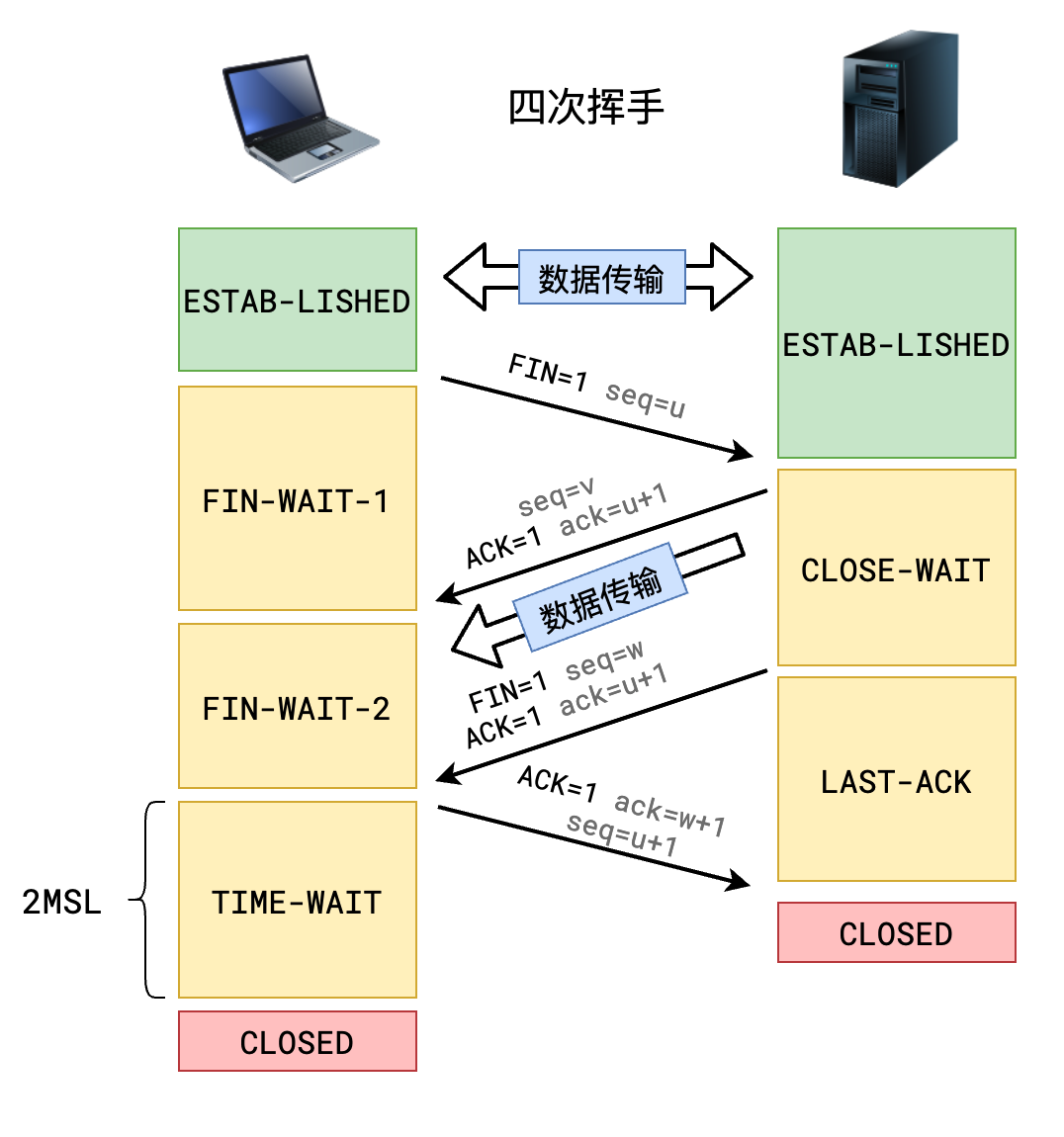
当需要关闭连接时,需要进行四次挥手才能关闭
- Client 向 Server 发送 FIN 包,表示 Client 主动要关闭连接,然后进入 FIN_WAIT_1 状态,等待 Server 返回 ACK 包。此后 Client 不能再向 Server 发送数据,但能读取数据
- Server 收到 FIN 包后向 Client 发送 ACK 包,然后进入 CLOSE_WAIT 状态,此后 Server 不能再读取数据,但可以继续向 Client 发送数据
- Client 收到 Server 返回的 ACK 包后进入 FIN_WAIT_2 状态,等待 Server 发送 FIN 包
- Server 完成数据的发送后,将 FIN 包发送给 Client,然后进入 LAST_ACK 状态,等待 Client 返回 ACK 包,此后 Server 既不能读取数据,也不能发送数据
- Client 收到 FIN 包后向 Server 发送 ACK 包,然后进入 TIME_WAIT 状态,接着等待足够长的时间(2MSL)以确保 Server 接收到 ACK 包,最后回到 CLOSED 状态,释放网络资源
- Server 收到 Client 返回的 ACK 包后便回到 CLOSED 状态,释放网络资源
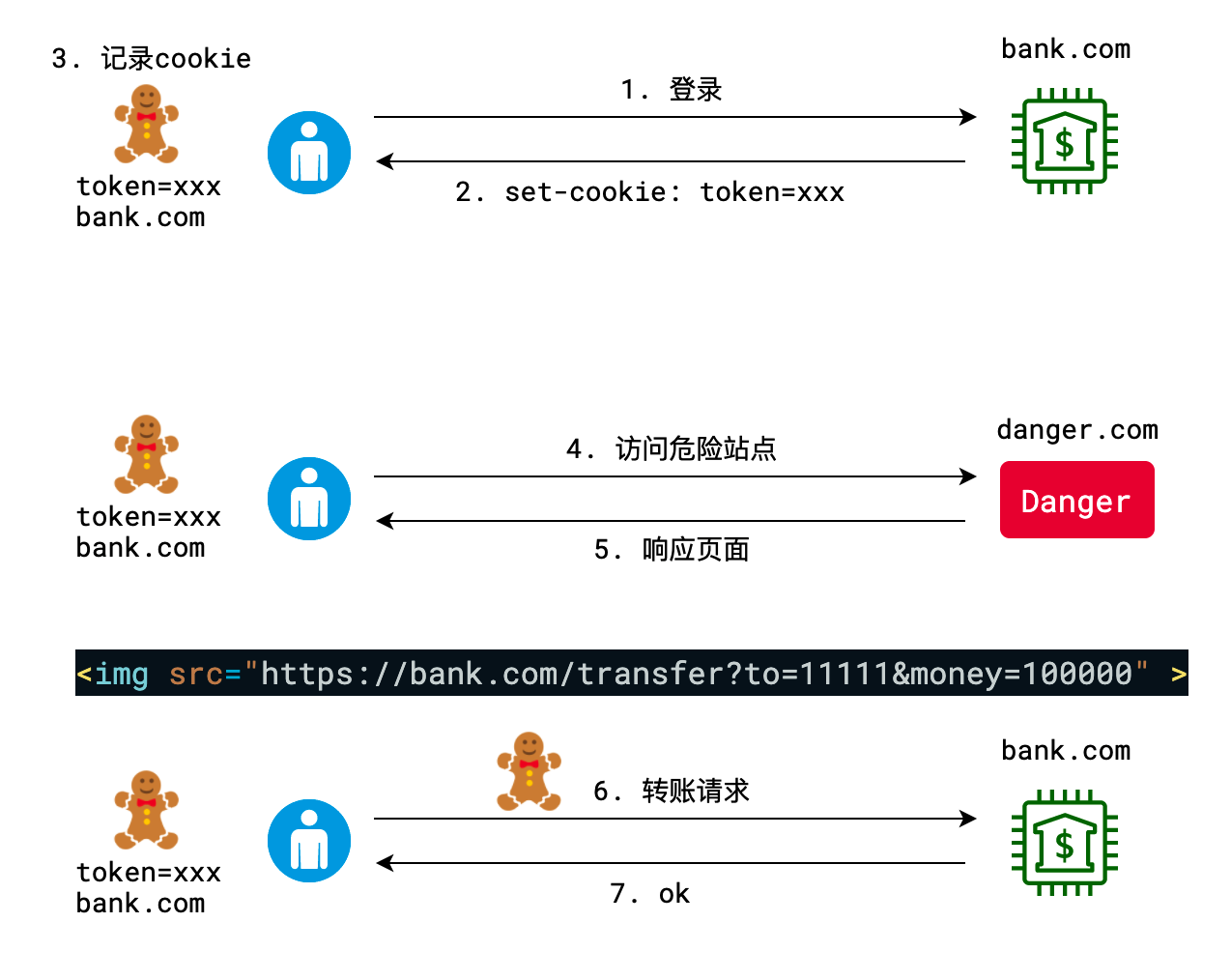
(十七)CSRF 攻击
- CSRF,Cross-Site Request Forgery,跨站请求伪造
- 指攻击者利用用户的身份信息,执行了用户非本意的操作
1.防御方式
| 防御手段 | 防御力 | 问题 |
|---|---|---|
| 不使用 cookie | ⭐️⭐️⭐️⭐️⭐️ | 兼容性略差 ssr 会遇到困难,但可解决 |
| 使用 SameSite | ⭐️⭐️⭐️⭐️ | 兼容性差 容易挡住自己人 |
| 使用 csrf token | ⭐️⭐️⭐️⭐️⭐️ | 获取到 token 后未进行操作仍然会被攻击 |
| 使用 referer 防护 | ⭐️⭐️ | 过去很常用,现在已经发现漏洞 |
2.面试题
1)介绍 csrf 攻击
CSRF 是跨站请求伪造,是一种挟制用户在当前已登录的 Web 应用上执行非本意的操作的攻击方法
首先引导用户访问一个危险网站,当用户访问网站后,网站会发送请求到被攻击的站点,这次请求会携带用户的 cookie 发送,因此就利用了用户的身份信息完成攻击
防御 CSRF 攻击有多种手段:
- 不使用 cookie
- 为表单添加校验的 token 校验
- cookie 中使用 sameSite 字段
- 服务器检查 referer 字段
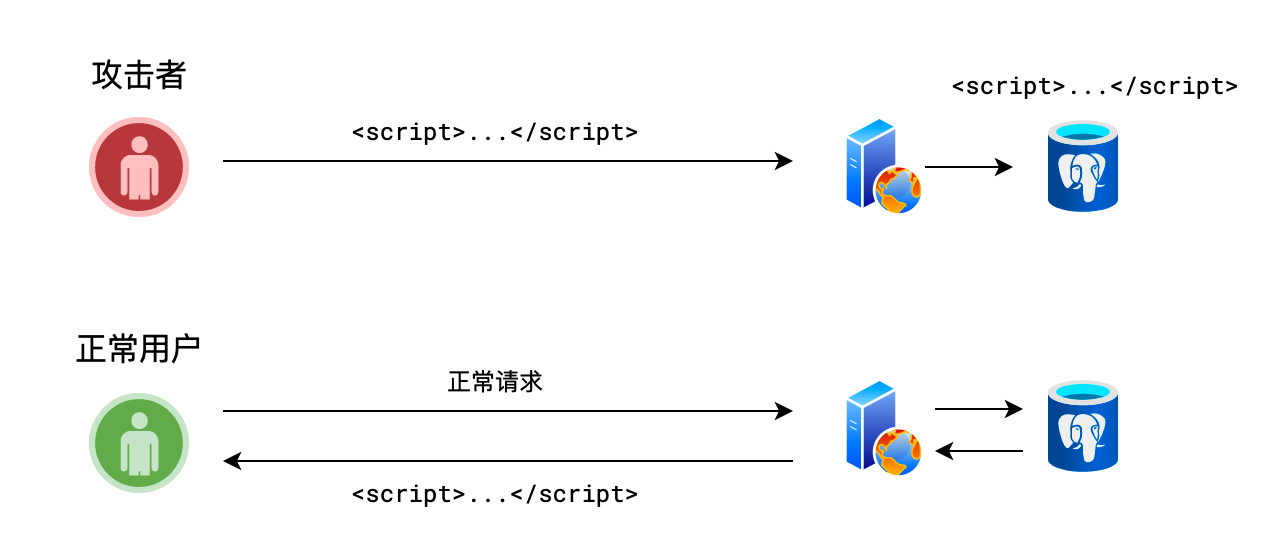
(十八)XSS 攻击
- XSS,Cross Site Scripting,跨站脚本攻击
- 指攻击者利用站点的漏洞,提交表单时在表单内容中加入一些恶意脚本
- 当其他正常用户浏览页面,而页面中刚好出现攻击者的恶意脚本时,脚本被执行,从而使得页面遭到破坏,或者用户信息被窃取
1.防御方式
- 服务器端对用户提交的内容进行过滤或编码
- 过滤:去掉一些危险的标签,去掉一些危险的属性
- 编码:对危险的标签进行 HTML 实体编码
2.面试题
1)介绍 XSS 攻击
XSS 是指跨站脚本攻击。攻击者利用站点的漏洞,在表单提交时,在表单内容中加入一些恶意脚本,当其他正常用户浏览页面,而页面中刚好出现攻击者的恶意脚本时,脚本被执行,从而使得页面遭到破坏,或者用户信息被窃取
要防范 XSS 攻击,需要在服务器端过滤脚本代码,将一些危险的元素和属性去掉或对元素进行 HTML 实体编码
(十九)网络性能优化
1.面试题
1)列举优化网络性能方法
- 优化打包体积
利用一些工具压缩、混淆最终打包代码,减少包体积
- 多目标打包
利用一些打包插件,针对不同的浏览器打包出不同的兼容性版本,这样一来,每个版本中的兼容性代码就会大大减少,从而减少包体积
- 压缩
现代浏览器普遍支持压缩格式,因此服务端的各种文件可以压缩后再响应给客户端,只要解压时间小于优化的传输时间,压缩就是可行的
- CDN
利用 CDN 可以大幅缩减静态资源的访问时间,特别是对于公共库的访问,可以使用知名的 CDN 资源,这样可以实现跨越站点的缓存
- 缓存
对于除 HTML 外的所有静态资源均可以开启协商缓存,利用构建工具打包产生的文件 hash 值来置换缓存
- HTTP2
开启 HTTP2 后,利用其多路复用、头部压缩等特点,充分利用带宽传递大量的文件数据
- 雪碧图
对于不使用 HTTP2 的场景,可以将多个图片合并为雪碧图,以达到减少文件的目的
- defer、async
通过 defer 和 async 属性,可以让页面尽早加载 js 文件
- prefetch、preload
通过 prefetch 属性,可以让页面在空闲时预先下载其他页面可能要用到的资源
通过 preload 属性,可以让页面预先下载本页面可能要用到的资源
- 多个静态资源域
对于不使用 HTTP2 的场景,将相对独立的静态资源分到多个域中保存,可以让浏览器同时开启多个 TCP 连接,并行下载
(二十)断点续传
1.实现下载时的断点续传
1)服务器在响应头中加入下面的字段
Accept-Ranges: bytes
- 是向客户端表明:这个文件可以支持传输部分数据,只需要传递需要的是哪一部分的数据即可,单位是字节
- 此时,某些支持断点续传的客户端,如:迅雷,就可以在请求时,告诉服务器需要的数据范围
2)客户端在请求头中加入下面的字段
range: bytes=0-5000
- 告诉服务器:请传递 0-5000 字节范围内的数据即可,无须传输全部数据
- Web 无法保存临时文件到用户系统上,所以通常桌面应用才需要实现断点下载
3)完整流程
2.实现上传时的断点续传
- 主要思路就是把要上传的文件切分为多个小的数据块然后进行上传【分片上传】
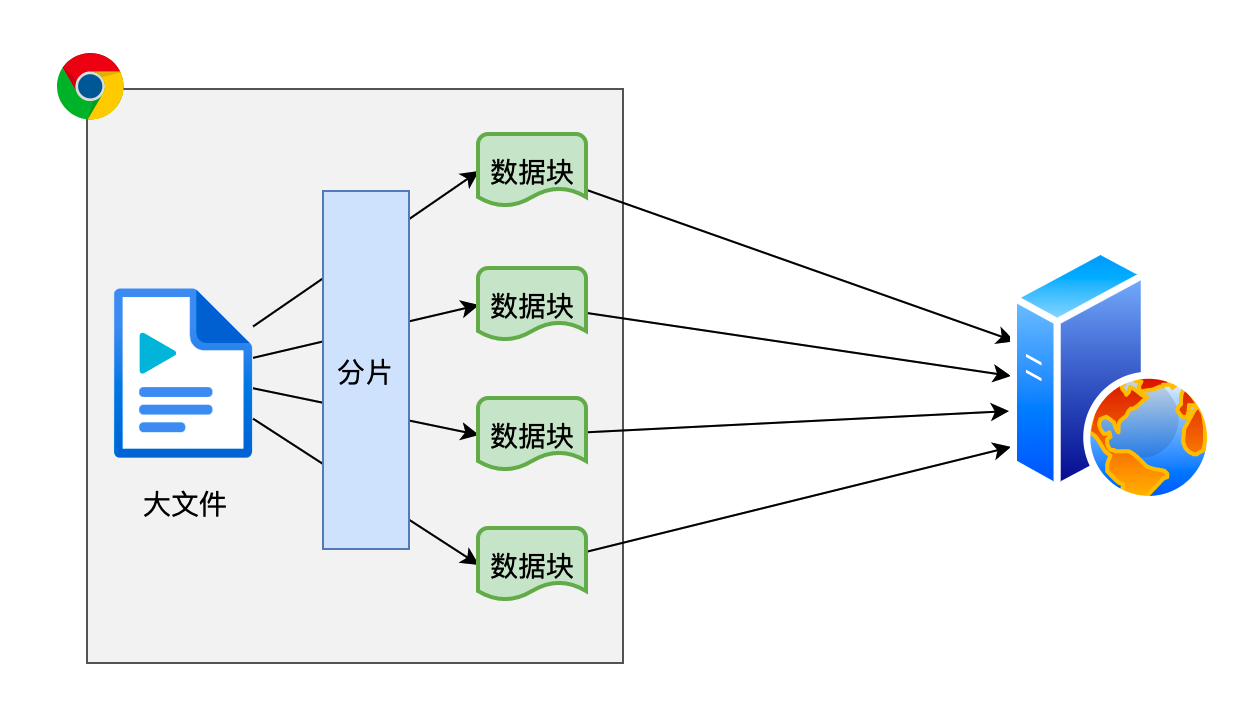
- 虽然整体思路一致,但没有一个统一的、具体的标准,因此需要根据具体的业务场景制定自己的标准
- 由于标准的不同,分片上传需要自行编写代码实现
- 下面用一种极其简易的流程实现分片上传
3.下载断点续传示例(服务器)
const express = require("express");
const path = require("path");
const app = express();
const cors = require("cors");
const port = require("./config").port;
app.use(cors());
app.use("/upload", express.static(path.join(__dirname, "./file")));
app.use(express.urlencoded({ extended: true }));
app.use(express.json());
app.get("/download/:filename", (req, res) => {
const filename = path.join(__dirname, "./res", req.params.filename);
res.download(filename, req.params.filename);
});
app.use("/api/upload", require("./uploader"));
app.listen(port, () => {
console.log(`server listen on ${port}`);
});
4.分片上传示例
1)接口文档
a)文件信息协商
- 请求路径:/api/upload/handshake
- 请求方法:POST
| 字段名 | 含义 | 是否必须 |
|---|---|---|
| fileId | 文件的 MD5 编码 | 是 |
| ext | 文件的后缀,例如:.jpg | 是 |
| chunkIds | 文件分片的编号数组,每个编号是一个 MD5 编码 | 是 |
- 可能的响应
{
"code": 0,
"msg": "",
"data": "http://localhost:8000/upload/a32d18.jpg" // 服务器已有该文件,无需上传
}
{
"code": 0,
"msg": "",
"data": ["md5-1", "md5-2", "md5-5"] // 服务器还需要上传的分片
}
- 可能发生的失败响应
{
code: 403,
msg: '请携带文件编号',
data: null
}
b)分片上传
- 请求路径:/api/upload
- 请求方法:POST
| 字段名 | 含义 | 是否必须 |
|---|---|---|
| file | 分片的二进制数据 | 是 |
| chunkId | 分片的 MD5 编码 | 是 |
| fileId | 分片所属文件的 MD5 编码 | 是 |
- 上传成功的响应
{
"code": 0,
"msg": "",
"data": ["md5-2", "md5-5"] // 服务器还需要上传的分片
}
- 可能发生的失败响应
{
"code": 403,
"msg": "请携带文件编号",
"data": null
}
2)客户端
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta http-equiv="X-UA-Compatible" content="IE=edge" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>断点续传-示例</title>
<link rel="stylesheet" href="./upload.css" />
</head>
<body>
<div class="container">
<div class="item">
<button class="btn choose">选择文件</button>
<input id="file" type="file" style="display: none" />
<div class="progress" style="display: none">
<div class="wrapper">
<div class="inner">
<span>0%</span>
</div>
</div>
</div>
<button data-status="unchoose" class="btn control" style="display: none">开始上传</button>
</div>
<div id="link" class="item" style="display: none">
<span>文件访问地址:</span>
<p>
<a href=""></a>
</p>
</div>
</div>
<div class="modal" style="display: none">
<div class="center">处理中, 请稍后...</div>
</div>
<script src="https://cdn.bootcdn.net/ajax/libs/spark-md5/3.0.0/spark-md5.js"></script>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.0/jquery.js"></script>
<script src="./upload.js"></script>
</body>
</html>
* {
margin: 0;
padding: 0;
box-sizing: border-box;
word-break: break-all;
}
.container {
width: 400px;
margin: 0 auto;
background: #eee;
padding: 20px;
margin-top: 20px;
}
.btn {
border: none;
outline: none;
font-size: inherit;
display: block;
margin-bottom: 1em;
white-space: nowrap;
cursor: pointer;
border: -5px solid #dcdfe6;
text-align: center;
box-sizing: border-box;
outline: none;
transition: 0.1s;
font-weight: 500;
width: 100%;
border: 1px solid;
border-radius: 5px;
height: 40px;
}
.btn.choose {
color: #606266;
background: #fff;
border-color: #dcdfe6;
}
.btn.choose:hover {
color: #409eff;
border-color: #c6e2ff;
background-color: #ecf5ff;
}
.btn.control {
color: #fff;
background-color: #409eff;
border-color: #409eff;
}
.btn.control:hover {
background: #66b1ff;
border-color: #66b1ff;
color: #fff;
}
.progress {
width: 100%;
height: 60px;
background: #ccc;
border-radius: 20px;
margin-bottom: 1em;
display: flex;
align-items: center;
padding: 0 20px;
}
.progress .wrapper {
position: relative;
width: 100%;
height: 5px;
}
.progress .wrapper::before {
content: "";
width: 100%;
background: #eee;
height: 5px;
border-radius: 3px;
display: block;
}
.inner {
position: absolute;
width: 0%;
background: #7ebf50;
height: 5px;
transition: 0.1s;
border-radius: 3px;
left: 0;
top: 0;
}
.inner span {
position: absolute;
right: 0;
top: 10px;
transform: translateX(50%);
font-size: 12px;
background: #333;
color: #fff;
padding: 0 3px;
}
.inner span::before {
content: "";
position: absolute;
border: 5px solid #333;
left: 50%;
top: 0;
transform: translate(-50%, -100%);
border-left-color: transparent;
border-top-color: transparent;
border-right-color: transparent;
}
.item {
margin-bottom: 1em;
}
.modal {
position: fixed;
left: 0;
top: 0;
width: 100%;
height: 100%;
display: flex;
justify-content: center;
align-items: center;
background: #00000080;
color: #fff;
}
var domControls = {
/**
* 设置进度条区域
* @param {number} percent 百分比 0-100
*/
setProgress(percent) {
const inner = $(".progress").show().find(".inner");
inner[0].clientHeight; // force reflow
inner.css("width", `${percent}%`);
inner.find("span").text(`${percent}%`);
},
/**
* 设置上传按钮状态
*/
setStatus() {
const btn = $(".btn.control");
const status = btn[0].dataset.status;
switch (status) {
case "unchoose": // 未选择文件
btn.hide();
break;
case "choose": // 刚刚选择了文件
btn.show();
btn.text("开始上传");
break;
case "uploading": // 上传中
btn.show();
btn.text("暂停");
break;
case "pause": // 暂停中
btn.show();
btn.text("继续");
break;
case "finish": // 已完成
btn.hide();
break;
}
},
/**
* 设置文件链接
*/
setLink(link) {
$("#link").show().find("a").prop("href", link).text(link);
},
};
/**
* 文件分片
* @param {File} file
* @returns
*/
async function splitFile(file) {
return new Promise((resolve) => {
// 分片尺寸(1M)
const chunkSize = 1024 * 1024;
// 分片数量
const chunkCount = Math.ceil(file.size / chunkSize);
// 当前chunk的下标
let chunkIndex = 0;
// 使用ArrayBuffer完成文件MD5编码
const spark = new SparkMD5.ArrayBuffer();
const fileReader = new FileReader(); // 文件读取器
const chunks = []; // 分片信息数组
// 读取一个分片后的回调
fileReader.onload = function (e) {
spark.append(e.target.result); // 分片数据追加到MD5编码器中
// 当前分片单独的MD5
const chunkMD5 = SparkMD5.ArrayBuffer.hash(e.target.result) + chunkIndex;
chunkIndex++;
chunks.push({
id: chunkMD5,
content: new Blob([e.target.result]),
});
if (chunkIndex < chunkCount) {
loadNext(); // 继续读取下一个分片
} else {
// 读取完成
const fileId = spark.end();
resolve({
fileId,
ext: extname(file.name),
chunks,
});
}
};
// 读取下一个分片
function loadNext() {
const start = chunkIndex * chunkSize,
end = start + chunkSize >= file.size ? file.size : start + chunkSize;
fileReader.readAsArrayBuffer(file.slice(start, end));
}
/**
* 获取文件的后缀名
* @param {string} filename 文件完整名称
*/
function extname(filename) {
const i = filename.lastIndexOf(".");
if (i < 0) {
return "";
}
return filename.substr(i);
}
loadNext();
});
}
// 选择文件
$(".btn.choose").click(function () {
$("#file").click();
});
let fileInfo;
let needs;
function setProgress() {
const total = fileInfo.chunks.length;
let percent = ((total - needs.length) / total) * 100;
percent = Math.ceil(percent);
domControls.setProgress(percent);
}
$("#file").change(async function () {
$(".modal").show();
fileInfo = await splitFile(this.files[0]);
const resp = await fetch("http://localhost:8000/api/upload/handshake", {
method: "POST",
headers: {
"content-type": "application/json",
},
body: JSON.stringify({
fileId: fileInfo.fileId,
ext: fileInfo.ext,
chunkIds: fileInfo.chunks.map((it) => it.id),
}),
}).then((resp) => resp.json());
$(".modal").hide();
if (Array.isArray(resp.data)) {
needs = resp.data;
setProgress();
$(".btn.control")[0].dataset.status = "choose";
domControls.setStatus();
} else {
needs = [];
setProgress();
$(".btn.control")[0].dataset.status = "finish";
domControls.setStatus();
domControls.setLink(resp.data);
}
});
$(".btn.control").click(function () {
const status = this.dataset.status;
switch (status) {
case "unchoose":
case "finish":
return;
case "uploading":
this.dataset.status = "pause";
domControls.setStatus();
break;
case "choose":
case "pause":
this.dataset.status = "uploading";
uploadPiece();
domControls.setStatus();
break;
}
});
async function uploadPiece() {
if (!needs) {
return;
}
if (needs.length === 0) {
// 上传完成
setProgress();
$(".btn.control")[0].dataset.status = "finish";
domControls.setStatus();
domControls.setLink(`http://localhost:8000/upload/${fileInfo.fileId}${fileInfo.ext}`);
return;
}
const status = $(".btn.control")[0].dataset.status;
if (status !== "uploading") {
return;
}
const nextChunkId = needs[0];
const file = fileInfo.chunks.find((it) => it.id === nextChunkId).content;
const formData = new FormData();
formData.append("file", file);
formData.append("chunkId", nextChunkId);
formData.append("fileId", fileInfo.fileId);
const resp = await fetch("http://localhost:8000/api/upload", {
method: "POST",
body: formData,
}).then((resp) => resp.json());
needs = resp.data;
setProgress();
uploadPiece();
}
3)服务器
const fs = require("fs");
const path = require("path");
const chunkDir = path.join(__dirname, "./chunktemp");
const fileInfoDir = path.join(__dirname, "./filetemp");
const fileDir = path.join(__dirname, "./file");
async function exists(path) {
try {
await fs.promises.stat(path);
return true;
} catch {
return false;
}
}
function existsSync(path) {
try {
fs.statSync(path);
return true;
} catch {
return false;
}
}
function createDir() {
function _createDir(path) {
if (!existsSync(path)) {
fs.mkdirSync(path);
}
}
_createDir(chunkDir);
_createDir(fileInfoDir);
_createDir(fileDir);
}
createDir();
async function createFileChunk(id, buffer) {
const absPath = path.join(chunkDir, id);
if (!(await exists(absPath))) {
await fs.promises.writeFile(absPath, buffer); // 写入文件
}
return {
id,
filename: id,
path: absPath,
};
}
async function writeFileInfo(id, ext, chunkIds, needs = chunkIds) {
const absPath = path.join(fileInfoDir, id);
let info = {
id,
ext,
chunkIds,
needs,
};
await fs.promises.writeFile(absPath, JSON.stringify(info), "utf-8");
return info;
}
async function getFileInfo(id) {
const absPath = path.join(fileInfoDir, id);
if (!(await exists(absPath))) {
return null;
}
const json = await fs.promises.readFile(absPath, "utf-8");
return JSON.parse(json);
}
/**
* 添加chunk
*/
async function addChunkToFileInfo(chunkId, fileId) {
const fileInfo = await getFileInfo(fileId);
if (!fileInfo) {
return null;
}
fileInfo.needs = fileInfo.needs.filter((it) => it !== chunkId);
return await writeFileInfo(fileId, fileInfo.ext, fileInfo.chunkIds, fileInfo.needs);
}
async function combine(fileInfo) {
//1. 将该文件的所有分片依次合并
const target = path.join(fileDir, fileInfo.id) + fileInfo.ext;
async function _move(chunkId) {
const chunkPath = path.join(chunkDir, chunkId);
const buffer = await fs.promises.readFile(chunkPath);
await fs.promises.appendFile(target, buffer);
fs.promises.rm(chunkPath);
}
for (const chunkId of fileInfo.chunkIds) {
await _move(chunkId);
}
//2. 删除文件信息
fs.promises.rm(path.join(fileInfoDir, fileInfo.id));
}
/**
* return:
* null: 没有此文件,也没有文件信息
* true: 有此文件,无须重新上传
* object:没有此文件,但有该文件的信息
*/
exports.getFileInfo = async function (id, ext) {
const absPath = path.join(fileDir, id) + ext;
if (await exists(absPath)) {
return true;
}
return await getFileInfo(id);
};
exports.createFileInfo = async function (id, ext, chunkIds) {
return await writeFileInfo(id, ext, chunkIds);
};
exports.handleChunk = async function (chunkId, fileId, chunkBuffer) {
let fileInfo = await getFileInfo(fileId);
if (!fileInfo) {
throw new Error("请先提交文件分片信息");
}
if (!fileInfo.chunkIds.includes(chunkId)) {
throw new Error("该文件没有此分片信息");
}
if (!fileInfo.needs.includes(chunkId)) {
// 此分片已经上传
return fileInfo.needs;
}
// 处理分片
await createFileChunk(chunkId, chunkBuffer);
// 添加分片信息到文件信息
fileInfo = await addChunkToFileInfo(chunkId, fileId);
// 还有需要的分片吗?
if (fileInfo.needs.length > 0) {
return fileInfo.needs;
} else {
// 全部传完了
await combine(fileInfo);
return [];
}
};
(二十一)域名和 DNS
1.域名
1)作用
- 帮助人类记忆网站地址,有了域名,就不用去记 IP 地址了
2)类型
- 根域名:
. - 顶级域名:
.cn、.com、.net、.us、.uk、.org、... - 二级域名:
.com、.gov、.org、.edu、自定义、baidu、jd、taobao、... - 三级域名:
自定义、www.baidu.com、www.jd.com、www.taobao.com - 四级域名:
自定义、www.pku.edu.cn、mail.internal.jd.com
一般来说,购买二级域名后,三级、四级域名都是可以免费自定义的
2.DNS
- 域名虽然有助于记忆,但是网络传输和域名没有关系
1)网络传输必须依靠 IP
- DNS 服务器能够将域名转换成 IP 地址
- 翻译成 IP 地址的过程称为 域名解析
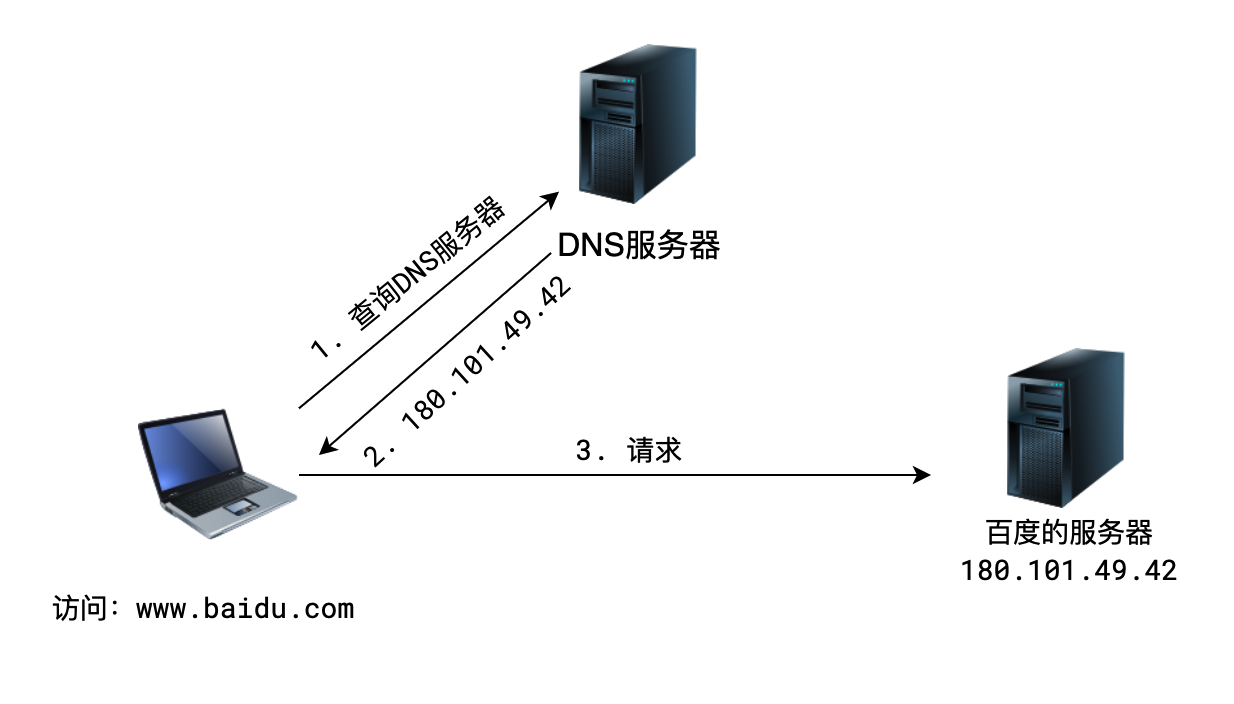
2)类型
- 全世界认可的 DNS 服务器一共有三种
- 外加一种局部使用的本地 DNS 服务器
- 一共四种
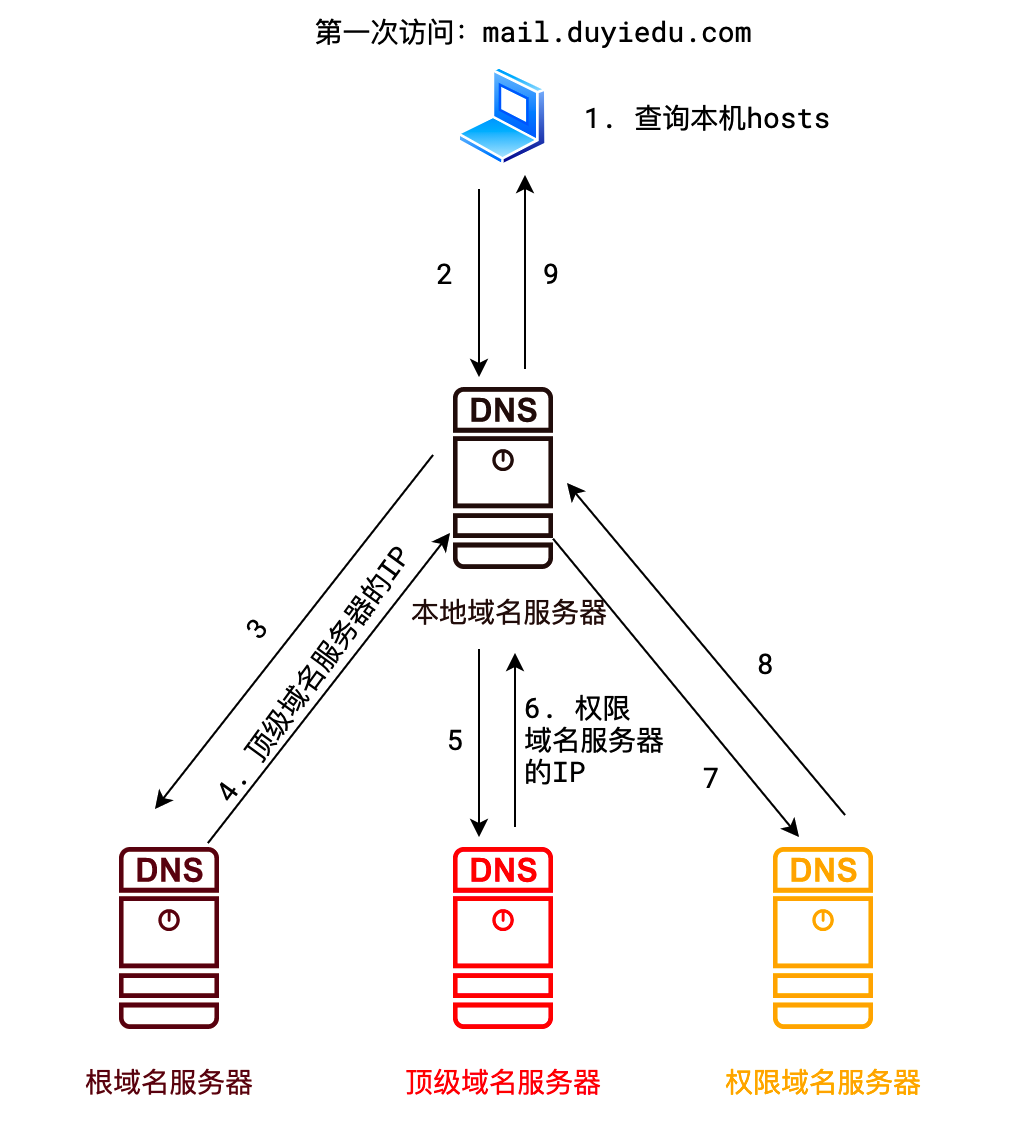
- 为了使得解析速度更快、查询的节点更少,上述每个节点都可能设置高速缓存来加速解析
3.面试题
1)请简述域名解析过程(百度)
- 查找本机 hosts 文件中是否有解析记录,如果有,直接使用
- 查找本地域名服务器中是否有解析记录,如果有,直接使用
- 查询根域名服务器,得到顶级域名服务器 ip
- 查询顶级域名服务器中是否有解析记录,如果有,直接使用
- 根据顶级域名服务器反馈的 ip,查询权限域名服务器,如果有解析记录,直接使用
- 如果以上都找不到,域名解析失败
本机和域名服务器一般都会有高速缓存,为了减少查询次数和时间
(二十二)SSL、TLS、HTTPS
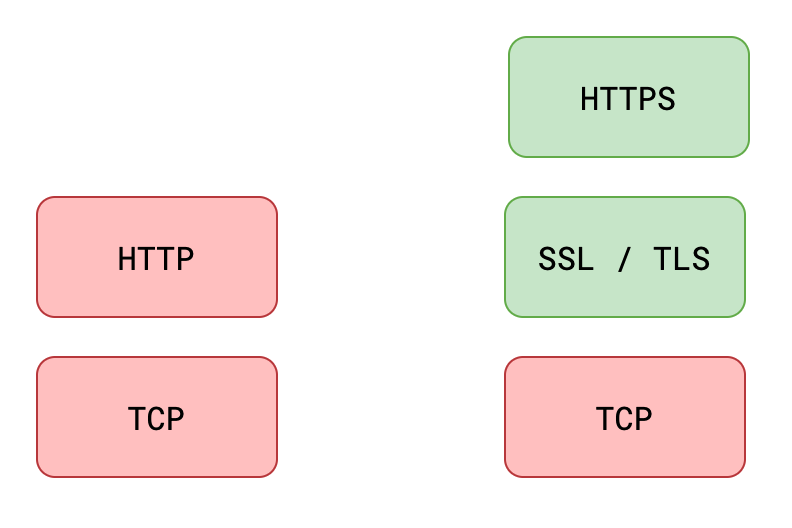
1.三者关系
- SSL,Secure Sockets Layer,安全套接字协议
- TLS,Transport Layer Security,传输层安全性协议
- HTTPS,Hyper Text Transfer Protocol over SecureSocket Layer,建立在 SSL 协议之上的 HTTP 协议
- TLS 是 SSL 的升级版,两者几乎一样
2.面试题
1)介绍下 HTTPS 中间人攻击
针对 HTTPS 攻击主要有 SSL 劫持攻击和 SSL 剥离攻击两种
- SSL 劫持攻击
- 指攻击者劫持了客户端和服务器之间的连接,将服务器的合法证书替换为伪造的证书,从而获取客户端和服务器之间传递的信息
- 这种方式一般容易被用户发现,浏览器会明确的提示证书错误,但某些用户安全意识不强,可能会点击继续浏览,从而达到攻击目的
- SSL 剥离攻击
- 指攻击者劫持了客户端和服务器之间的连接,攻击者保持自己和服务器之间的 HTTPS 连接,但发送给客户端普通的 HTTP 连接
- 由于 HTTP 连接是明文传输的,即可获取客户端传输的所有明文数据
2)介绍 HTTPS 握手过程
- 客户端请求服务器,并告诉服务器自身支持的加密算法以及密钥长度等信息
- 服务器响应公钥和服务器证书
- 客户端验证证书是否合法,然后生成一个会话密钥,并用服务器的公钥加密密钥,把加密的结果通过请求发送给服务器
- 服务器使用私钥解密被加密的会话密钥并保存起来,然后使用会话密钥加密消息响应给客户端,表示自己已经准备就绪
- 客户端使用会话密钥解密消息,知道了服务器已经准备就绪
- 后续客户端和服务器使用会话密钥加密信息传递消息
3)HTTPS 握手过程中,客户端如何验证证书的合法性
- 校验证书的颁发机构是否受客户端信任
- 通过 CRL 或 OCSP 的方式校验证书是否被吊销
- 对比系统时间,校验证书是否在有效期内
- 通过校验对方是否存在证书的私钥,判断证书的网站域名是否与证书颁发的域名一致
4)阐述 HTTPS 验证身份(TSL/SSL 身份验证)的过程
- 客户端请求服务器,并告诉服务器自身支持的加密算法以及密钥长度等信息
- 服务器响应公钥和服务器证书
- 客户端验证证书是否合法,然后生成一个会话密钥,并用服务器的公钥加密密钥,把加密的结果通过请求发送给服务器
- 服务器使用私钥解密被加密的会话密钥并保存起来,然后使用会话密钥加密消息响应给客户端,表示自己已经准备就绪
- 客户端使用会话密钥解密消息,知道了服务器已经准备就绪
- 后续客户端和服务器使用会话密钥加密信息传递消息
5)为什么需要 CA 机构对证书签名
主要是为了解决证书的可信问题
如果没有权威机构对证书进行签名,客户端就无法知晓证书是否是伪造的,从而增加了中间人攻击的风险,HTTPS 就变得毫无意义
6)如何劫持 HTTPS 的请求,提供思路
HTTPS 有防篡改的特点,只要浏览器证书验证过程是正确的,很难在用户不察觉的情况下进行攻击
但若能够更改浏览器的证书验证过程,便有机会实现 HTTPS 中间人攻击
所以,要劫持 HTTPS,首先要伪造一个证书,并且要想办法让用户信任这个证书,可以有多种方式,比如病毒、恶意软件、诱导等
一旦证书被信任后,就可以利用普通中间人攻击的方式,使用伪造的证书进行攻击
(二十三)HTTP 各版本的差异
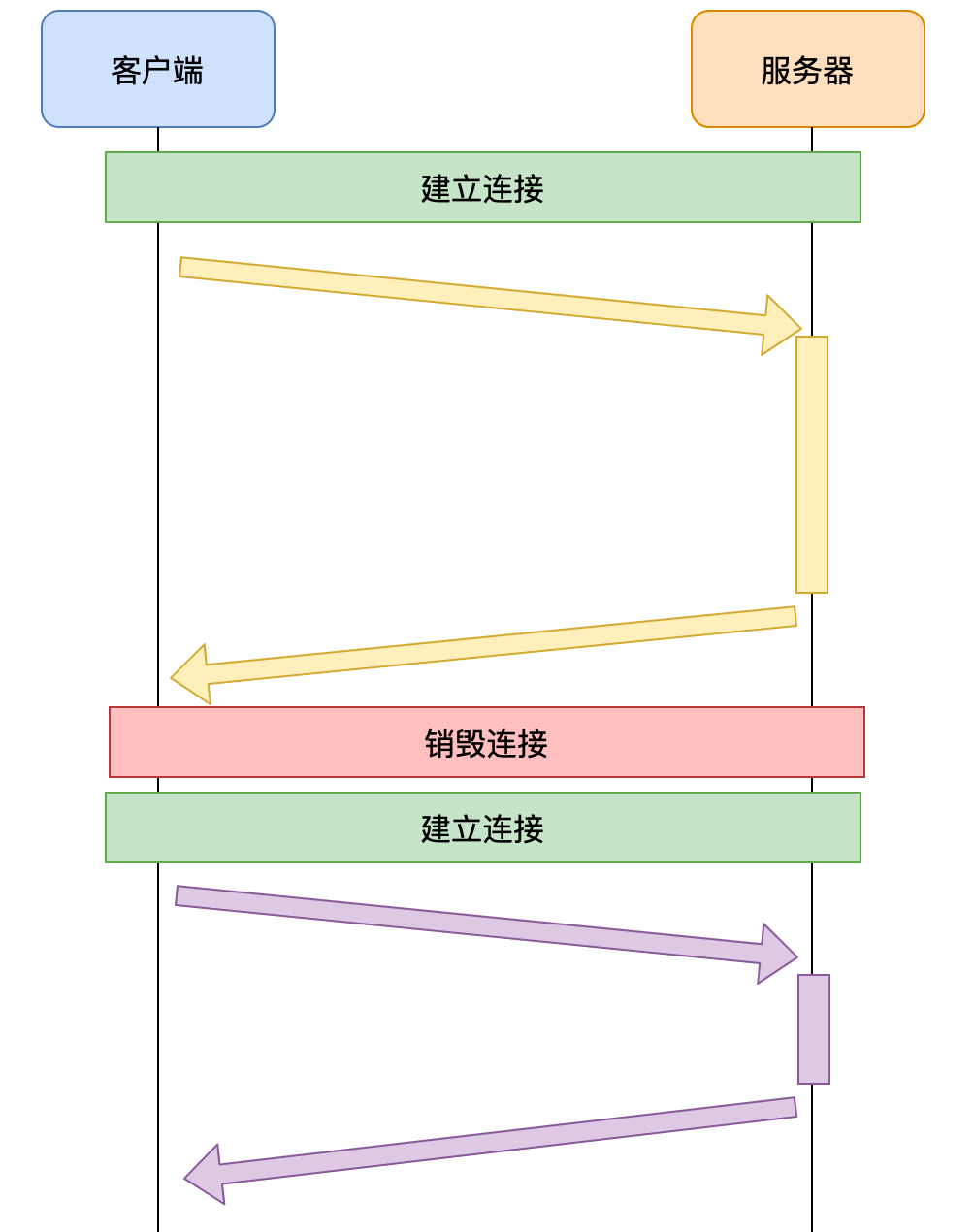
1.HTTP1.0
1)无法复用连接
- HTTP1.0 为每个请求单独新开一个 TCP 连接
- 由于每个请求都是独立的连接,因此会带来下面的问题
- 连接的建立和销毁都会占用服务器和客户端的资源,造成内存资源的浪费
- 连接的建立和销毁都会消耗时间,造成响应时间的浪费
- 无法充分利用带宽,造成带宽资源的浪费
TCP 协议的特点是 慢启动
即:一开始传输的数据量少,一段时间之后达到传输的峰值
而上面这种做法,会导致大量的请求在 TCP 达到传输峰值前就被销毁了
2)队头阻塞
2.HTTP1.1
1)长连接
- 为了解决 HTTP1.0 的问题,HTTP1.1 默认开启长连接
- 即:让同一个 TCP 连接服务于多个请求-响应
- 多次请求响应可以共享同一个 TCP 连接
- 不仅减少了 TCP 的握手和挥手时间
- 同时可以充分利用 TCP 慢启动的特点,有效的利用带宽
实际上,在 HTTP1.0 后期,虽然没有官方标准,但开发者们慢慢形成了一个共识:
只要请求头中包含 Connection:keep-alive,就表示客户端希望开启长连接,希望服务器响应后不要关闭 TCP 连接,如果服务器认可这一行为,即可保持 TCP 连接
- 当需要的时候,任何一方都可以关闭 TCP 连接
- 连接关闭的情况主要有三种
- 客户端在某一次请求中设置了
Connection:close,服务器收到此请求后,响应结束立即关闭 TCP - 在没有请求时,客户端会不断对服务器进行心跳检测(一般每隔 1 秒),一旦心跳检测停止,服务器立即关闭 TCP
- 当客户端长时间没有新的请求到达服务器,服务器会主动关闭 TCP,运维人员可以设置该时间
- 客户端在某一次请求中设置了
- 由于一个 TCP 连接可以承载多次请求响应,并在一段时间内不会断开,因此这种连接称为长连接
2)管道化和队头阻塞
- HTTP1.1 允许在响应到达之前发送下一个请求
- 可以大幅缩减带宽限制时间
- 会存在队头阻塞的问题
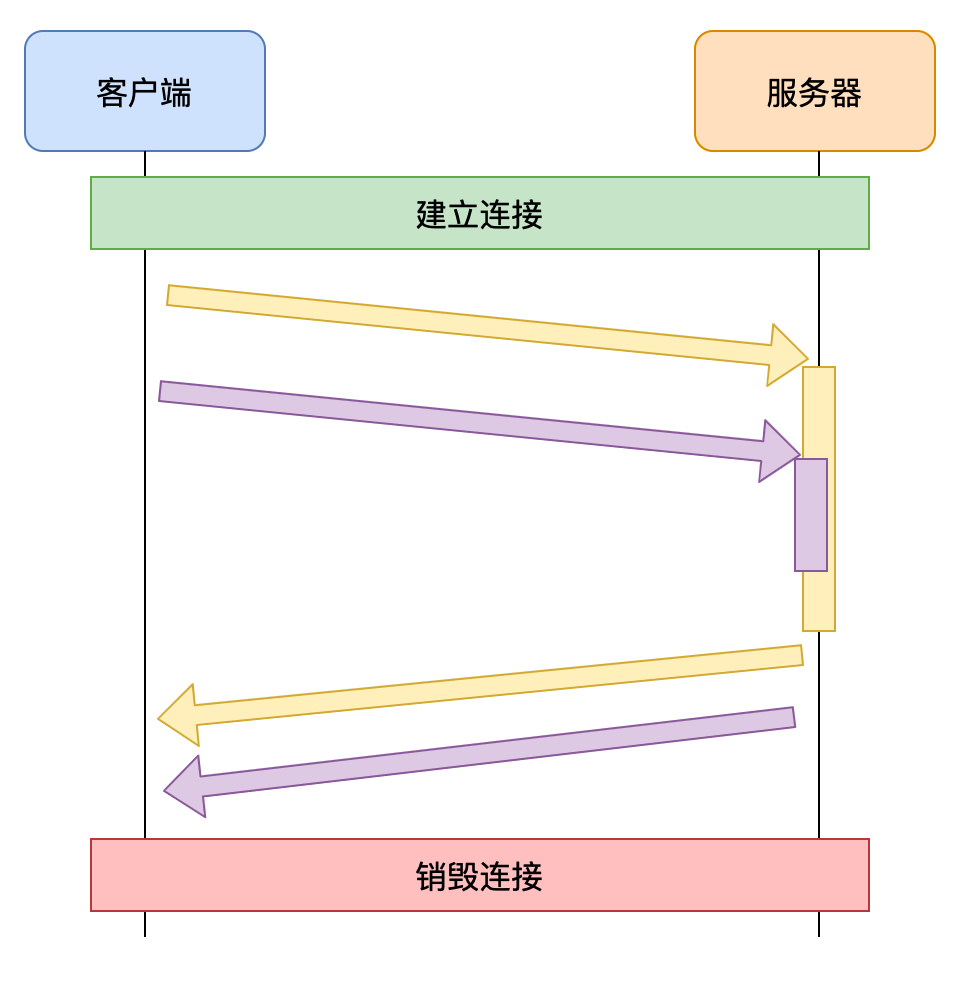
- 由于多个请求使用的是同一个 TCP 连接,服务器必须按照请求到达的顺序进行响应
- 导致一些后发出的请求,无法在处理完成后响应,产生了等待的时间
- 这段时间的带宽可能是空闲的,造成了带宽的浪费
- 队头阻塞虽然 发生在服务器
- 但问题的根源是 客户端无法知晓服务器的响应是针对哪个请求的
- 常常使用下面的手段进行优化
- 通过减少文件数量,从而减少队头阻塞的几率
- 通过开辟多个 TCP 连接,实现真正的、有缺陷的并行传输
浏览器会根据情况,为打开的页面自动开启 TCP 连接,对于同一个域名的连接最多 6 个
如果要突破这个限制,就需要把资源放到不同的域中
相关信息
管道化并非一个成功的模型,它带来的队头阻塞造成非常多的问题,所以现代浏览器默认是关闭这种模式的
3.HTTP2.0

1)二进制分帧
- HTTP2.0 可以允许以更小的单元传输数据
- 每个传输单元称为 帧
- 每一个请求或响应的完整数据称为 流
- 每个流有自己的编号,每个帧会记录所属的流
- 如:服务器连续接到了客户端的两个请求,一个请求 JS、一个请求 CSS,两个文件如下:
function a() {}
function b() {}
.container {
}
.list {
}
- 最终形成的帧可能如下
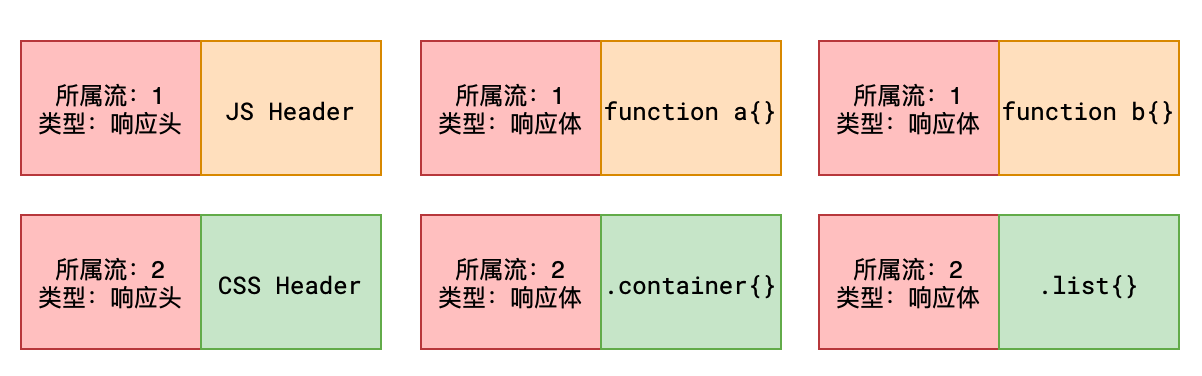
- 每个帧都带了一个头部,记录了流的 ID
- 就能够准确的知道这一帧数据是属于哪个流的
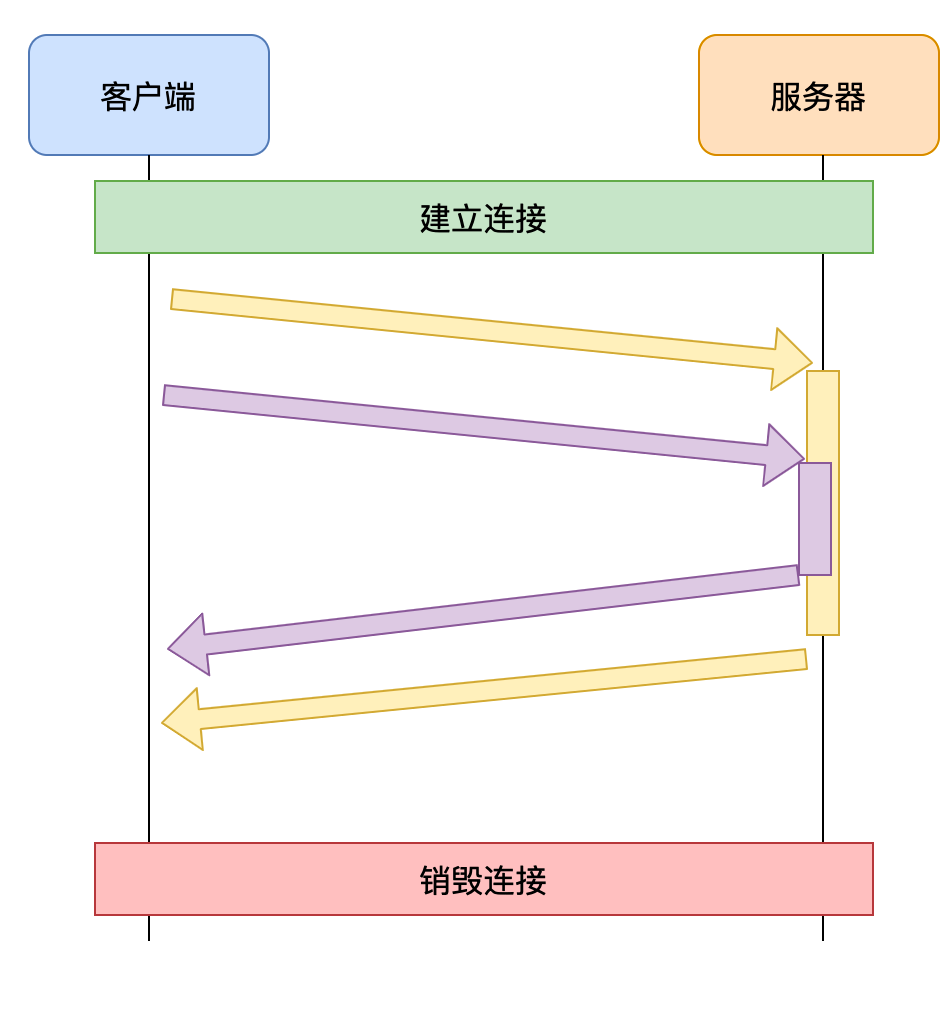
- 真正地解决了共享 TCP 连接时的队头阻塞问题,实现了真正的 多路复用
- 由于传输时是以帧为单元传输的,无论是响应还是请求,都可以实现并发处理
- 即:不同的传输可以交替进行
- 由于进行了分帧,还可以 设置传输优先级
2)头部压缩
- HTTP2.0 之前,所有的消息头都是以 字符 的形式完整传输的
- 实际上大部分头部信息都有很多的重复
- 为了解决这一问题,HTTP2.0 使用头部压缩来 减少消息头的体积
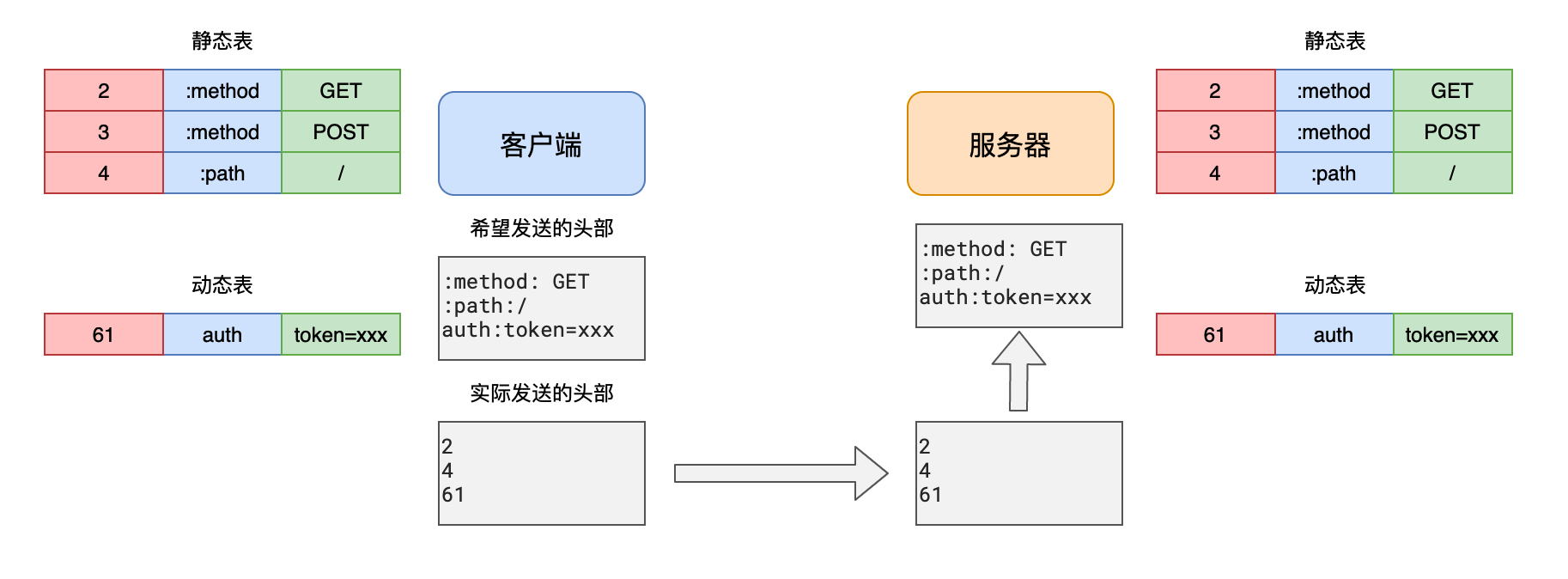
- 对于两张表都没有的头部,则使用 Huffman 编码压缩后进行传输,同时添加到动态表中
3)服务器推
- HTTP2.0 允许在客户端没有主动请求的情况下,服务器预先把资源推送给客户端
- 当客户端后续需要请求该资源时,则自动从之前推送的资源中寻找
4.面试题
1)介绍下 HTTP1.0、HTTP1.1、HTTP2.0 协议的区别?
首先说 HTTP1.0
特点是每次请求和响应完毕后都会销毁 TCP 连接,同时规定前一个响应完成后才能发送下一个请求。这样做有两个问题:
- 无法复用连接
每次请求都要创建新的 TCP 连接,完成三次握手和四次挥手,网络利用率低
- 队头阻塞
如果前一个请求被某种原因阻塞了,会导致后续请求无法发送
然后是 HTTP1.1
HTTP1.1 是 HTTP1.0 的改进版,做出了以下改进:
- 长连接
HTTP1.1 允许在请求时增加请求头
connection:keep-alive,这样便允许后续的客户端请求在一段时间内复用之前的 TCP 连接
- 管道化
基于长连接的基础,管道化可以不等第一个请求响应继续发送后面的请求,但响应的顺序还是按照请求的顺序返回
- 缓存处理
新增响应头 cache-control,用于实现客户端缓存
- 断点传输
在上传/下载资源时,如果资源过大,将其分割为多个部分,分别上传/下载,如果遇到网络故障,可以从已经上传/下载好的地方继续请求,不用从头开始,提高效率
最后是 HTTP2.0
HTTP2.0 进一步优化了传输效率,主要有以下改进:
- 二进制分帧
将传输的消息分为更小的二进制帧,每帧有自己的标识序号,即便被随意打乱也能在另一端正确组装
- 多路复用
基于二进制分帧,在同一域名下所有访问都是从同一个 TCP 连接中走,并且不再有队头阻塞问题,也无须遵守响应顺序
- 头部压缩
HTTP2.0 通过字典的形式,将头部中的常见信息替换为更少的字符,极大的减少了头部的数据量,从而实现更小的传输量
- 服务器推
HTTP2.0 允许服务器直接推送消息给客户端,无须客户端明确的请求
2)为什么 HTTP1.1 不能实现多路复用(腾讯)
- HTTP/1.1 的传输单元是整个响应文本,因此接收方必须按序接收完所有的内容后才能接收下一个传输单元,否则就会造成混乱
- 而 HTTP2.0 的传输单元更小,是一个二进制帧,而且每个帧有针对所属流的编号,这样即便是不同的流交替传输,也可以很容易区分出每个帧是属于哪个流的
3)简单讲解一下 HTTP2 的多路复用(网易)
在 HTTP/2 中,有两个非常重要的概念,分别是帧(frame)和流(stream)
- 帧代表着最小的数据单位,每个帧会标识出该帧属于哪个流,流也就是多个帧组成的数据流
- 多路复用,就是在一个 TCP 连接中可以存在多条流,也就是可以发送多个请求,对端可以通过帧中的标识知道属于哪个请求
- 通过这个技术,可以避免 HTTP 旧版本中的队头阻塞问题,极大的提高传输性能
4)HTTP1.1 是如何复用 TCP 连接的?(网易)
客户端请求服务器时,通过请求行告诉服务器使用的协议是 HTTP1.1,同时在请求头中附带
connection:keep-alive(为了保持兼容),告诉服务器这是一个长连接,后续请求可以重复使用这一次的 TCP 连接这样做的好处是减少了三次握手和四次挥手的次数,一定程度上提升了网络利用率。但由于 HTTP1.1 不支持多路复用,响应顺序必须按照请求顺序抵达客户端,不能真正实现并行传输,因此在 HTTP2.0 出现之前,实际项目中往往把静态资源,比如图片,分发到不同域名下的资源服务器,以便实现真正的并行传输
5)HTTP1.0、HTTP2.0、HTTP3.0 之间的区别
HTTP1.0
每次请求和响应完毕后都会销毁 TCP 连接,同时规定前一个响应完成后才能发送下一个请求。这样做有两个问题:
- 无法复用连接
每次请求都要创建新的 TCP 连接,完成三次握手和四次挥手,网络利用率低
- 队头阻塞
如果前一个请求被某种原因阻塞了,会导致后续请求无法发送
HTTP2.0
HTTP2.0 优化了传输效率,主要有以下改进:
- 二进制分帧
将传输的消息分为更小的二进制帧,每帧有自己的标识序号,即便被随意打乱也能在另一端正确组装
- 多路复用
基于二进制分帧,在同一域名下所有访问都是从同一个 TCP 连接中走,并且不再有队头阻塞问题,也无须遵守响应顺序
- 头部压缩
HTTP2.0 通过字典的形式,将头部中的常见信息替换为更少的字符,极大的减少了头部的数据量,从而实现更小的传输量
- 服务器推
HTTP2.0 允许服务器直接推送消息给客户端,无须客户端明确的请求
HTTP3.0
- HTTP3.0 目前还在草案阶段,完全抛弃了 TCP 协议,转而使用 UDP 协议,是为了进一步提升性能
- 虽然 HTTP2.0 进行了大量的优化,但无法摆脱 TCP 协议本身的问题,比如建立连接时间长、对头阻塞问题等等
- 为了保证传输的可靠性,HTTP3.0 使用了 QUIC 协议
(二十四)WebSocket
1.实时场景的旧处理方案
- 网页中的以下场景
- 股票 K 线图
- 聊天
- 警报、重要通知
- 余座
- 抢购页面的库存
- ......
- 有一个共同特点 —— 实时性
- 这种对实时性有要求的页面,会带来一些问题
- 如:下面的聊天场景
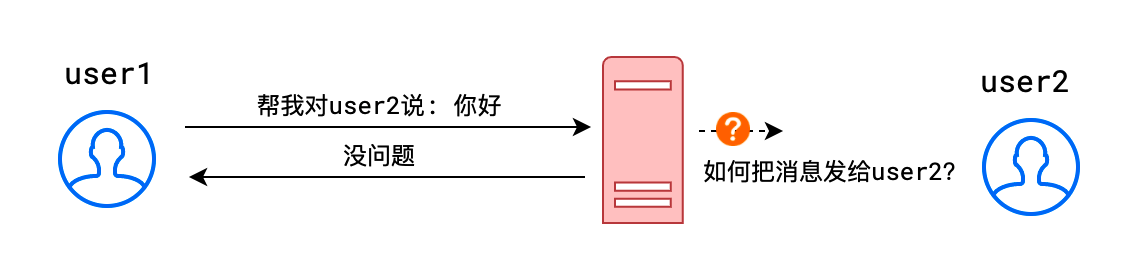
- 由于 HTTP 协议是请求-响应模式,请求必须在前,响应必须在后
- 导致服务器无法主动地把消息告诉客户端
2.短轮询 Short Polling
短轮询是一种话痨式的方式
- 客户端每隔一小段时间就向服务器请求一次,询问有没有新消息
1)实现
- 客户端只需要设置一个计时器不断发送请求即可
2)缺陷
- 会产生大量无意义的请求
- 会频繁打开关闭连接
- 实时性并不高
3.长轮询 Long Polling
- 有效的解决了话痨问题,让每一次请求和响应都是有意义的
1)缺陷
- 客户端长时间收不到响应会导致超时,从而主动断开和服务器的连接
这种情况是可以处理的:当 ajax 请求因为超时而结束时,立即重新发送请求到服务器
虽然这种做法会让之前的请求变得无意义,但毕竟比短轮询好多了
- 由于客户端可能过早地请求了服务器,服务器不得不挂起这个请求直到新消息的出现 ·- 这会让服务器长时间的占用资源却没什么实际的事情可做
4.WebSocket
- 随着 HTML5 出现的 WebSocket,从 协议 上赋予了服务器主动推送消息的能力
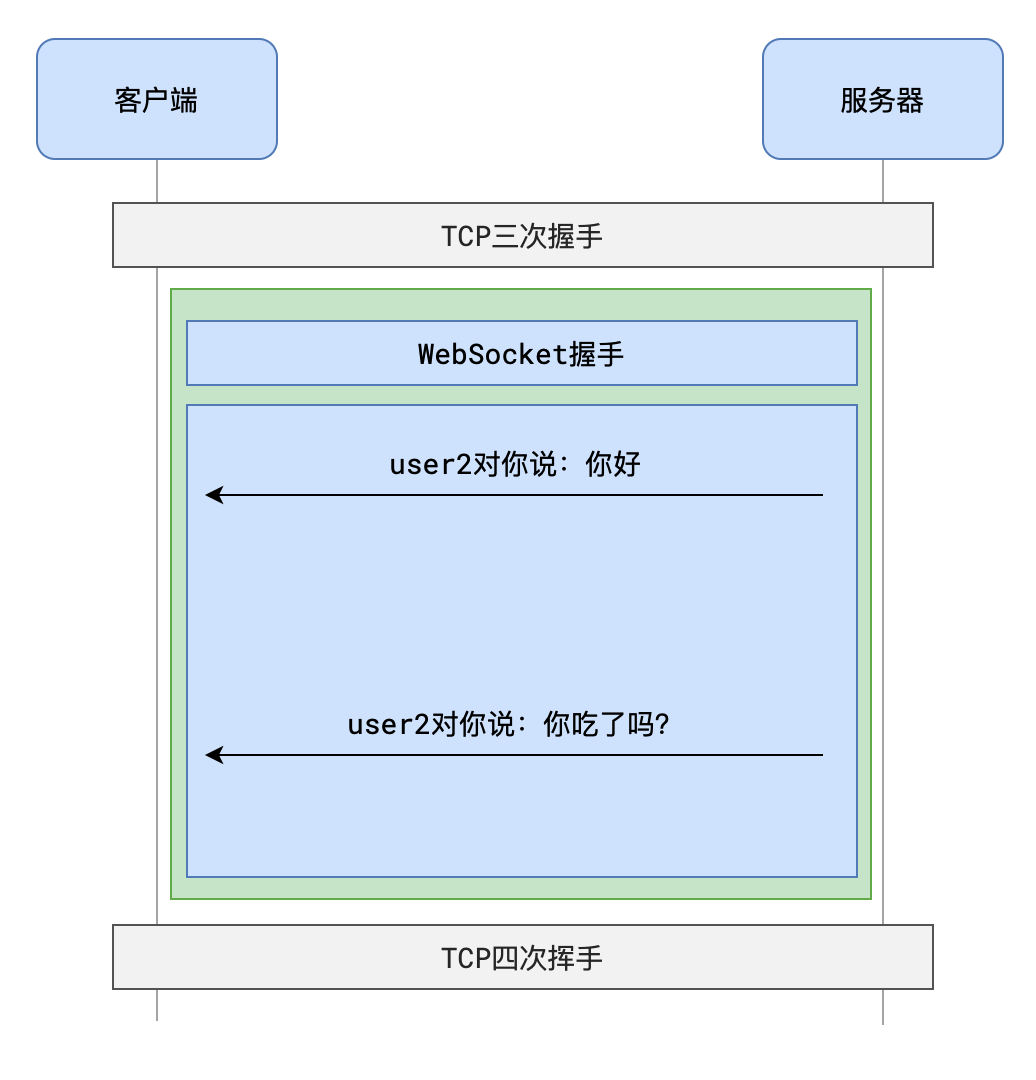
- WebSocket 也是建立在 TCP 协议之上的,利用的是 TCP 全双工通信 的能力
- 使用 WebSocket,会经历两个阶段:握手阶段、通信阶段
1)缺陷
- 兼容性
- WebSocket 是 HTML5 新增的内容,因此古董版本的浏览器并不支持
- 维持 TCP 连接需要耗费资源
- 对于那些消息量少的场景,维持 TCP 连接确实会造成资源的浪费
为了充分利用 TCP 连接的资源,在使用了 WebSocket 的页面,可以放弃 ajax,都用 WebSocket 进行通信
当然这会带来程序设计上的一些问题,需要权衡
2)握手协议
WebSocket 协议是一个高扩展性的协议,详细内容会比较复杂,这里仅讲解面试中会问到的握手协议
- 当客户端需要和服务器使用 WebSocket 进行通信时,首先会使用 HTTP 协议 完成一次特殊的请求-响应
- 这一次请求-响应就是 WebSocket 握手
- 在握手阶段,首先由客户端向服务器发送一个请求
- 请求地址格式
# 使用HTTP
ws://mysite.com/path
# 使用HTTPS
wss://mysite.com/path
- 请求头
Connection: Upgrade # 嘿,后续咱们别用HTTP了,升级吧
Upgrade: websocket # 我们把后续的协议升级为websocket
Sec-WebSocket-Version: 13 # websocket协议版本就用13好吗?
Sec-WebSocket-Key: YWJzZmFkZmFzZmRhYw== # 暗号:天王盖地虎
- 服务器如果同意,就应该响应下面的消息
HTTP/1.1 101 Switching Protocols # 换,马上换协议
Connection: Upgrade # 协议升级了
Upgrade: websocket # 升级到websocket
Sec-WebSocket-Accept: ZzIzMzQ1Z2V3NDUyMzIzNGVy # 暗号:小鸡炖蘑菇
- 握手完成,后续消息收发不再使用 HTTP,任何一方都可以主动发消息给对方
5.面试题
1)WebSocket 协议是什么,能简述一下吗?
WebSocket 协议 HTML5 带来的新协议,相对于 HTTP,它是一个持久连接的协议,利用 HTTP 协议完成握手,然后通过 TCP 连接通道发送消息,使用 WebSocket 协议可以实现服务器主动推送消息
- 首先,客户端若要发起 WebSocket 连接,首先必须向服务器发送 HTTP 请求以完成握手,请求行中的 path 需要使用
ws:开头的地址,请求头中要分别加入upgrade、connection、Sec-WebSocket-Key、Sec-WebSocket-Version标记- 然后,服务器收到请求后,发现这是一个 WebSocket 协议的握手请求,于是响应行中包含
Switching Protocols,同时响应头中包含upgrade、connection、Sec-WebSocket-Accept标记- 当客户端收到响应后即可完成握手,随后使用建立的 TCP 连接直接发送和接收消息
2)WebSocket 与传统的 HTTP 相比有什么优势
当页面中需要观察实时数据的变化(如:聊天、k 线图)时,过去我们往往使用两种方式完成
- 短轮询,即客户端每隔一段时间就向服务器发送消息,询问有没有新的数据
- 长轮询,发起一次请求询问服务器,服务器可以将该请求挂起,等到有新消息时再进行响应。响应后,客户端立即又发起一次请求,重复整个流程
无论是哪一种方式,都暴露了 HTTP 协议的弱点,即响应必须在请求之后发生,服务器是被动的,无法主动推送消息,而让客户端不断的发起请求又白白的占用了资源
WebSocket 的出现就是为了解决这个问题,它利用 HTTP 协议完成握手之后,就可以与服务器建立持久的连接,服务器可以在任何需要的时候,主动推送消息给客户端,这样占用的资源最少,同时实时性也最高
3)前端如何实现即时通讯?
- 短轮询,即客户端每隔一段时间就向服务器发送消息,询问有没有新的数据
- 长轮询,发起一次请求询问服务器,服务器可以将该请求挂起,等到有新消息时再进行响应。响应后,客户端立即又发起一次请求,重复整个流程
- Websocket,握手完毕后会建立持久性的连接通道,随后服务器可以在任何时候推送新消息给客户端
(二十五)WebSocket 实战
1.WebSocket API
const ws = new WebSocket("地址"); // 创建websocket连接,浏览器自动握手
// 事件:握手完成后触发
ws.onopen = function () {
console.log("连接到了服务器");
};
// 事件:收到服务器消息后触发
ws.onmessage = function (e) {
console.log(e.data); // e.data:服务器发送的消息
};
// 事件:连接关闭后触发
ws.onclose = function () {
console.log("连接关闭了");
};
// 发送消息到服务器
ws.send("消息");
// 连接状态:0-正在连接中 1-已连接 2-正在关闭中 3-已关闭
console.log(ws.readyState);
2.Socket.io
- 原生的接口虽然简单,但是在实际应用中会造成很多麻烦
- 如:一个页面,既有 K 线,也有实时聊天
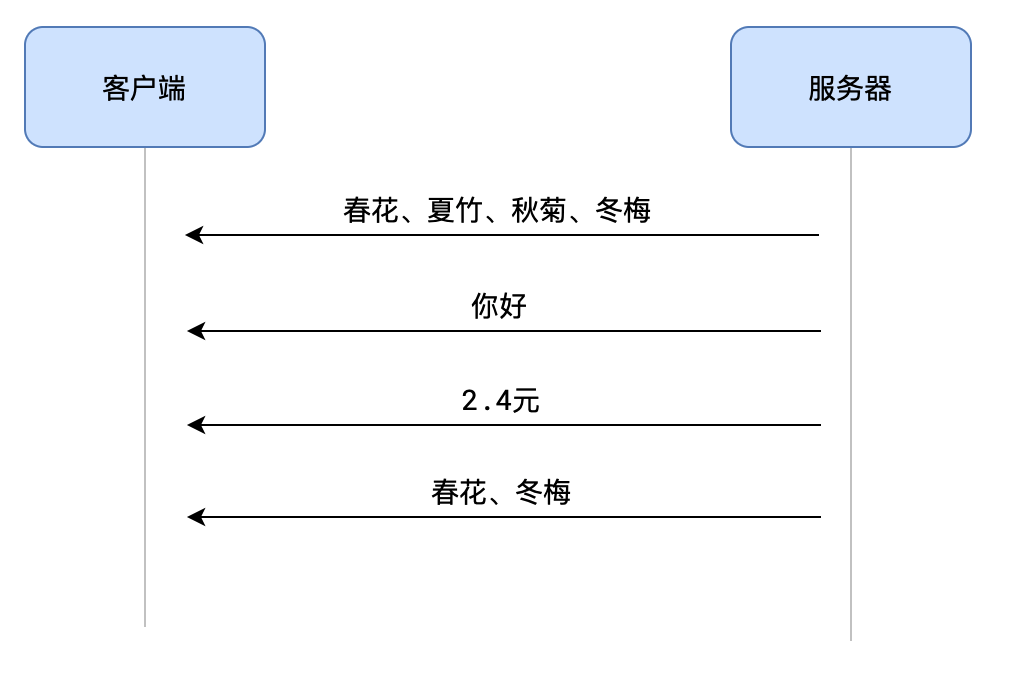
上图是一段时间中服务器给客户端推送的数据,无法区分这些数据的含义
这就是问题所在:连接双方可以在任何时候发送任何类型的数据,另一方必须要清楚这个数据的含义是什么
虽然可以自行解决这些问题,但毕竟麻烦
- Socket.io 解决了这些问题,把消息放到不同的 事件 中
- 通过监听和触发事件来实现对不同消息的处理
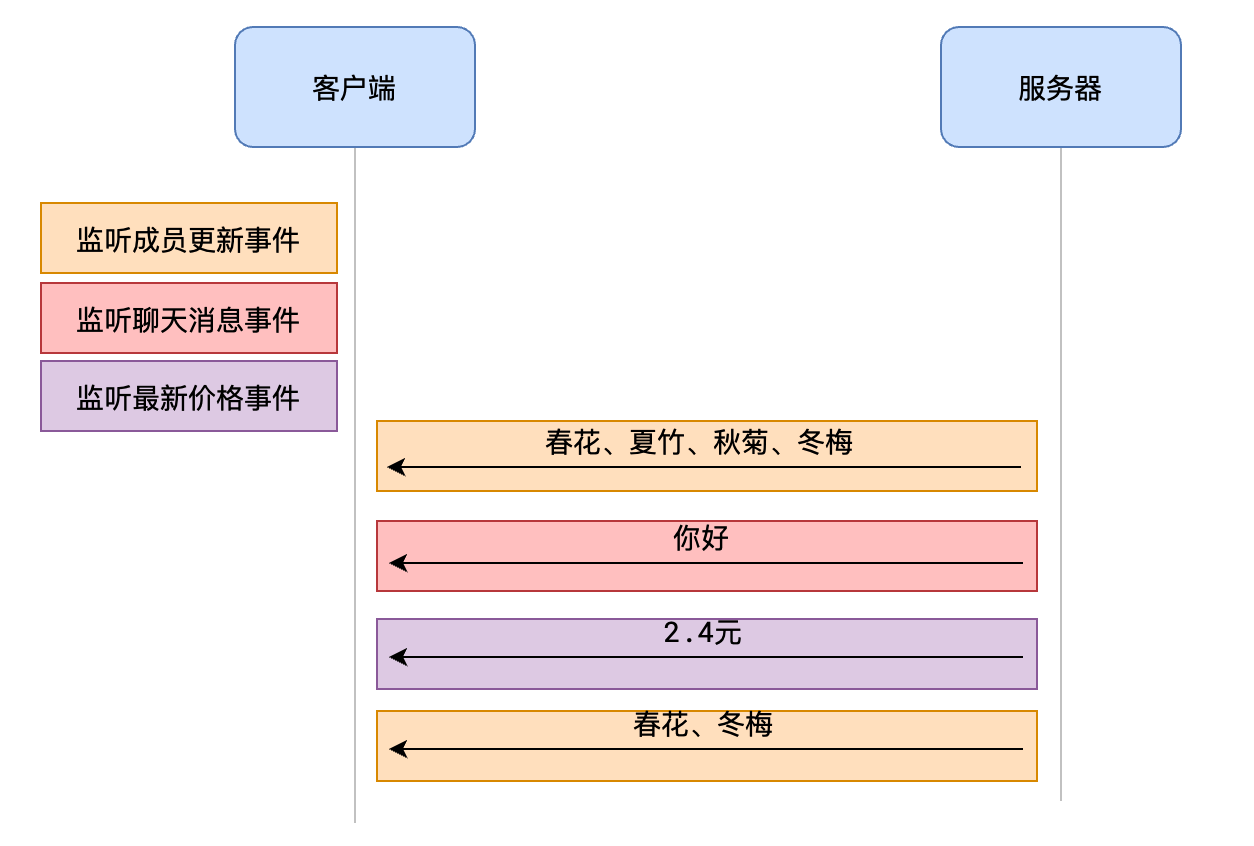
- 客户端和服务器双方事先约定好不同的事件,事件由谁监听,由谁触发,就可以把各种消息进行有序管理了
注意
Socket.io 为了实现这些要求,对消息格式进行了特殊处理,因此如果一方要使用 Socket.io,双方必须都使用
1)在客户端使用 Socket.io
- 在约定事件名时要注意,Socket.io 有一些预定义的事件名
- 如:message、connect 等
- 为了避免冲突,建议自定义事件名使用一个特殊的前缀
- 如:
$
- 如:
- Socket.io 对低版本浏览器还进行了兼容处理
- 如果浏览器不支持 WebSocket,Socket.io 将使用长轮询(long polling)处理
- Socket.io 还支持使用 命名空间 来进一步隔离业务
3.接口文档
1)测试接口
- 连接地址:ws://localhost:9527
- 服务器消息
- 服务器每隔 3 秒钟会发送一个消息给客户端
- 每次收到客户端的消息后,服务器会回应一个消息
2)聊天室接口
- 连接地址:ws://localhost:9528
a)服务器触发的事件/客户端需要监听的事件
| 事件名 | 触发时机 | 传递的消息 | 传递消息示例 |
|---|---|---|---|
$updateUser | 有新用户进入 有老用户退出 自己进入 | 当前聊天室的用户数组 | ['张三', '李四'] |
$name | 自己进入 | 分配的用户名称 | "张三" |
$history | 自己进入 | 历史聊天记录 | [{ name:"张三", content:"你好", date: 1635484786373 }] |
$message | 其他人发送消息 | 消息对象 | { name:"张三", content:"你好", date: 1635484786373 } |
b)客户端触发的事件/服务器需要监听的事件
| 事件名 | 触发时机 | 传递的消息 | 传递消息示例 |
|---|---|---|---|
$message | 发送聊天消息 | 消息字符串 | "你好!" |
3)客户端 App.vue
<template>
<div class="app">
<ChatWindow v-if="!isLoading" :me="me" :history="history" :users="users" @chat="handleChat" />
</div>
</template>
<script>
import ChatWindow from "./components/ChatWindow.vue";
import { io } from "socket.io-client";
export default {
components: {
ChatWindow,
},
data() {
return {
history: [],
me: "",
users: [],
isLoading: true,
socket: null,
};
},
created() {
this.socket = io("ws://localhost:9528");
this.socket.on("connect", () => {
this.isLoading = false;
});
this.socket.on("$updateUser", (users) => {
this.users = users;
});
this.socket.on("$name", (name) => {
this.me = name;
});
this.socket.on("$history", (history) => {
this.history = history;
});
this.socket.on("$message", (msg) => {
this.history.push(msg);
});
},
beforeDestroy() {
this.socket.disconnect();
},
methods: {
handleChat(msg) {
this.history.push(msg);
this.socket.emit("$message", msg.content);
},
},
};
</script>
<style>
.app {
width: 100%;
height: 100%;
position: fixed;
left: 0;
top: 0;
background: #1e1e1e;
display: flex;
justify-content: center;
align-items: center;
}
* {
margin: 0;
padding: 0;
box-sizing: border-box;
list-style: none;
}
</style>
4)客户端 ChatWindow.vue
<template>
<div class="container">
<div class="users">
<p>聊天室成员</p>
<ul>
<li v-for="u in users" :key="u">{{ u }}</li>
</ul>
</div>
<div class="main">
<div class="content-area" ref="info">
<div v-for="(h, i) in history" :class="{ mine: me === h.name }" :key="i" class="item">
<div class="name">{{ h.name }}</div>
<div class="content">{{ h.content }}</div>
<div class="date">{{ formatDate(h.date) }}</div>
</div>
</div>
<div class="form">
<textarea v-model="value" @keydown.enter="handleEnter"></textarea>
</div>
</div>
</div>
</template>
<script>
import moment from "moment";
moment.locale("zh-cn");
export default {
props: {
users: {
type: Array,
default: () => [],
},
history: {
type: Array,
default: () => [],
},
me: {
type: String,
required: true,
},
},
data() {
return {
value: "",
};
},
mounted() {
this.$watch(
"history",
() => {
const div = this.$refs.info;
div.scroll(0, div.scrollHeight);
},
{ immediate: true },
);
},
methods: {
formatDate(date) {
date = moment(date);
return date.fromNow().replace(/\s/g, "");
},
handleEnter() {
const v = this.value.trim();
if (v) {
this.value = "";
this.$emit("chat", { name: this.me, content: v, date: Date.now() });
}
},
},
};
</script>
<style scoped>
.container {
background: #fff;
width: 665px;
height: 522px;
display: flex;
border-radius: 5px;
box-shadow: -2px 2px 2px rgba(0, 0, 0, 0.5);
overflow: hidden;
}
.users {
width: 150px;
border-right: 1px solid #ccc;
line-height: 30px;
overflow: auto;
flex: 0 0 auto;
}
.users p {
text-align: center;
border-bottom: 1px solid #ccc;
}
.users li {
padding: 0 10px;
font-size: 12px;
border-bottom: 1px solid #ccc;
background: #f1f1f1;
}
.users li:nth-child(2n) {
background: #fff;
}
.main {
flex: 1 1 auto;
background: #f1f1f1;
display: flex;
flex-direction: column;
}
.content-area {
height: 400px;
padding: 1em;
overflow: auto;
border-bottom: 1px solid #ccc;
font-size: 14px;
line-height: 1.5;
flex: 0 0 auto;
scroll-behavior: smooth;
}
.item {
float: left;
max-width: 70%;
clear: both;
margin-bottom: 1em;
}
.name {
font-size: 12px;
color: #666;
}
.date {
color: #bbb;
font-size: 12px;
text-align: right;
}
.content {
background: #fff;
border-radius: 5px;
padding: 10px;
margin: 5px 0;
}
.mine.item {
float: right;
}
.mine .content {
background: #a9e97a;
}
.mine .name {
text-align: right;
}
.mine .date {
text-align: left;
}
.form {
flex: 1 1 auto;
}
.form textarea {
width: 100%;
height: 100%;
resize: none;
border: none;
outline: none;
padding: 20px;
}
</style>
5)服务器 ws.js
const { WebSocketServer } = require("ws");
function createServer(port) {
return new Promise(function (resolve) {
const wss = new WebSocketServer(
{
port,
},
() => {
resolve(wss);
},
);
});
}
let count = 0;
async function init(port) {
const wss = await createServer(port);
console.log(`支持原生 WebSocket 的服务器已启动,端口号:${port}`);
wss.on("connection", (socket) => {
// console.log(`有一个小伙伴已经和我完成了握手,可以随意的发消息了!`);
socket.on("message", (message) => {
// console.log(`收到小伙伴的消息:${message}`);
socket.send("你说的真好!很棒棒哦!");
});
});
const timer = setInterval(() => {
count++;
wss.clients.forEach((ws) => {
ws.send(`来自服务器的消息:${count}`);
});
}, 3000);
wss.on("close", () => {
clearInterval(timer);
});
}
init(9527);
6)服务器 chat.js
const { Server } = require("socket.io");
const history = []; // 聊天历史记录 {name:string, content:string, date: number}
let nextId = 1; // 下一个用户的id
const users = new Set(); // 用户数组
const io = new Server({
path: "/",
cors: {
origin: "*",
methods: ["GET", "POST"],
},
});
io.on("connection", (socket) => {
// 分配用户名
const username = `游客${nextId++}`;
users.add(username);
// 广播通知所有用户(含自己)
io.emit("$updateUser", [...users]);
// 发送聊天记录
socket.emit("$history", history);
// 告知用户名
socket.emit("$name", username);
// 监听聊天消息
socket.on("$message", (content) => {
const msg = {
name: username,
content,
date: Date.now(),
};
history.push(msg);
// 广播消息
socket.broadcast.emit("$message", msg);
});
socket.on("disconnect", () => {
// 清除用户
users.delete(username);
// 广播通知所有用户
socket.broadcast.emit("$updateUser", [...users]);
});
});
io.listen(9528);
console.log(`Socket.io 聊天室已启动,端口号:9528`);