二、Node
(一)Node 核心
1.Node 概述
- Node 是一个 JS 的运行环境
约定俗成
- JavaScript 指运行在浏览器环境下的 JS
- NodeJS 指运行在 Node 环境下的 JS
1)浏览器中的 JS
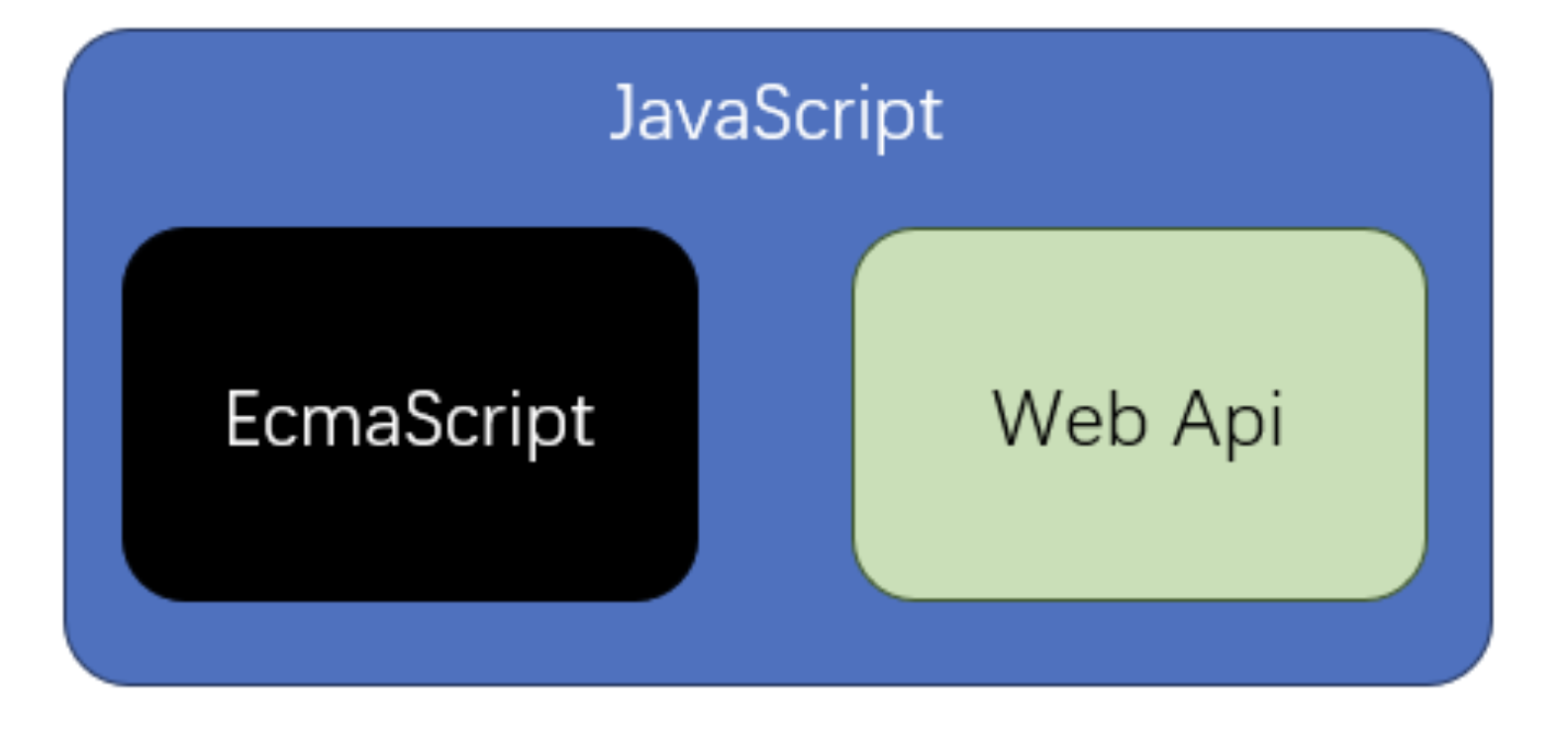
- Web API 提供了操作浏览器窗口和页面的能力
- BOM
- DOM
- AJAX
- 该能力有局限
- 跨域问题(浏览器本身的同源策略所导致的)
- 无法读写文件(只能读取用户指定的文件)
2)Node 中的 JS
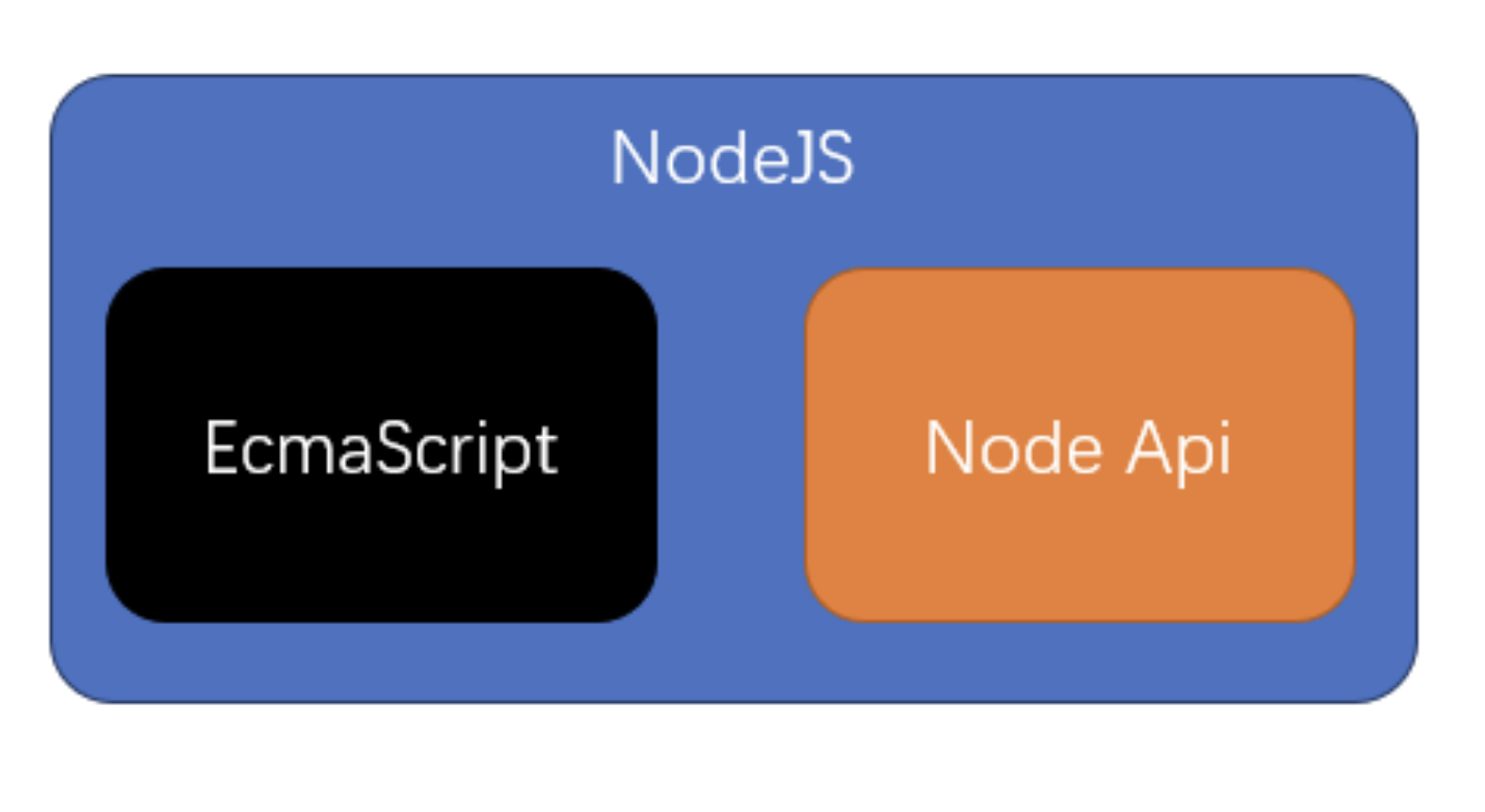
- Node API 几乎提供了所有能完成的功能
3)分层结构对比
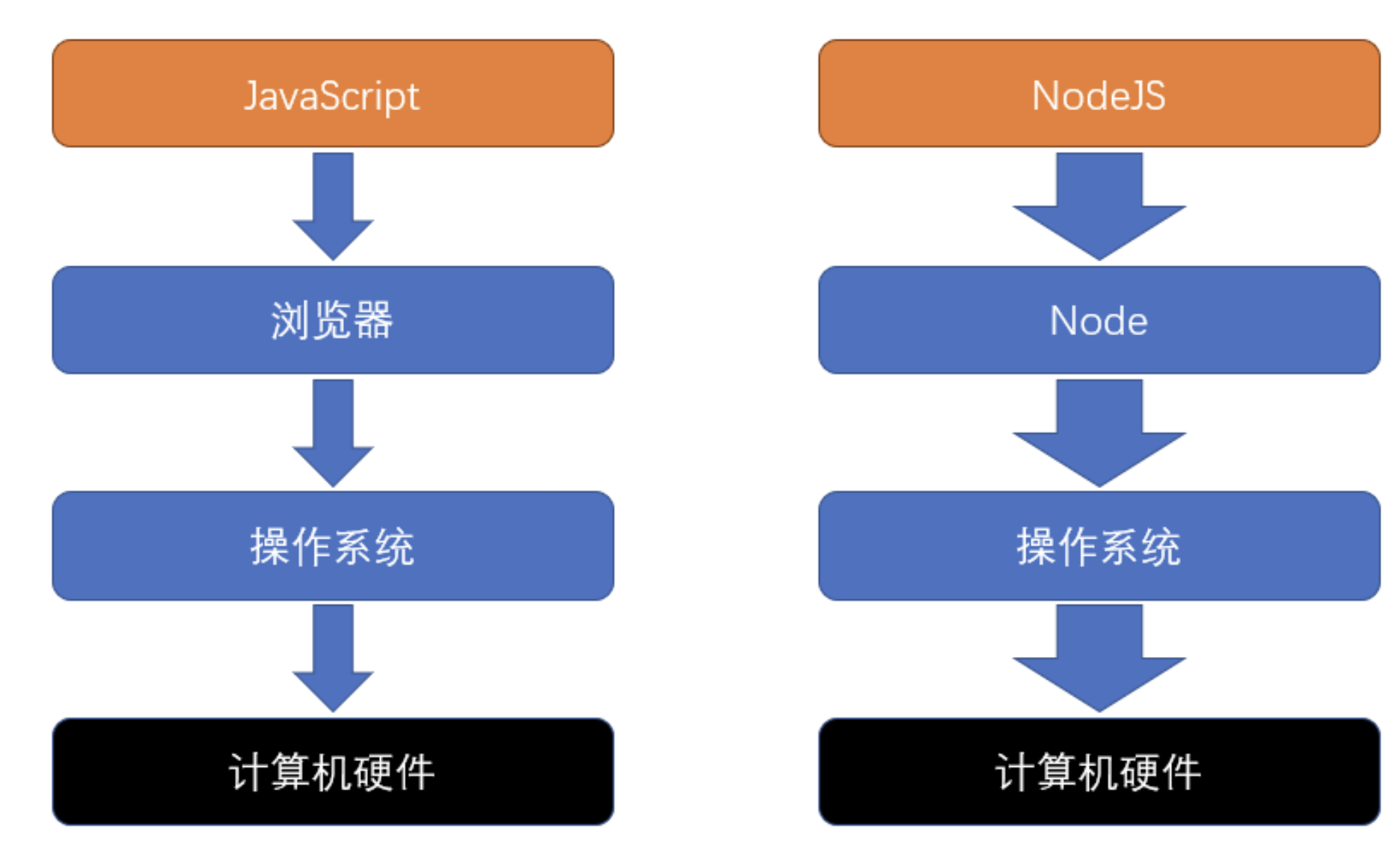
- 浏览器提供了有限的能力
- JS 只能使用浏览器提供的功能,完成有限的操作
- Node 提供了完整的控制计算机的能力
- NodeJS 几乎可以通过 Node 提供的接口,实现对整个操作系统的控制
4)应用 1:开发桌面应用程序
- 如:Visual Studio Code
5)应用 2:开发服务器应用程序
- 结构 1
- 通常应用在微型站点上,如:个人博客
- Node 服务器要完成
- 请求的处理、响应
- 数据库交互
- 各种业务逻辑
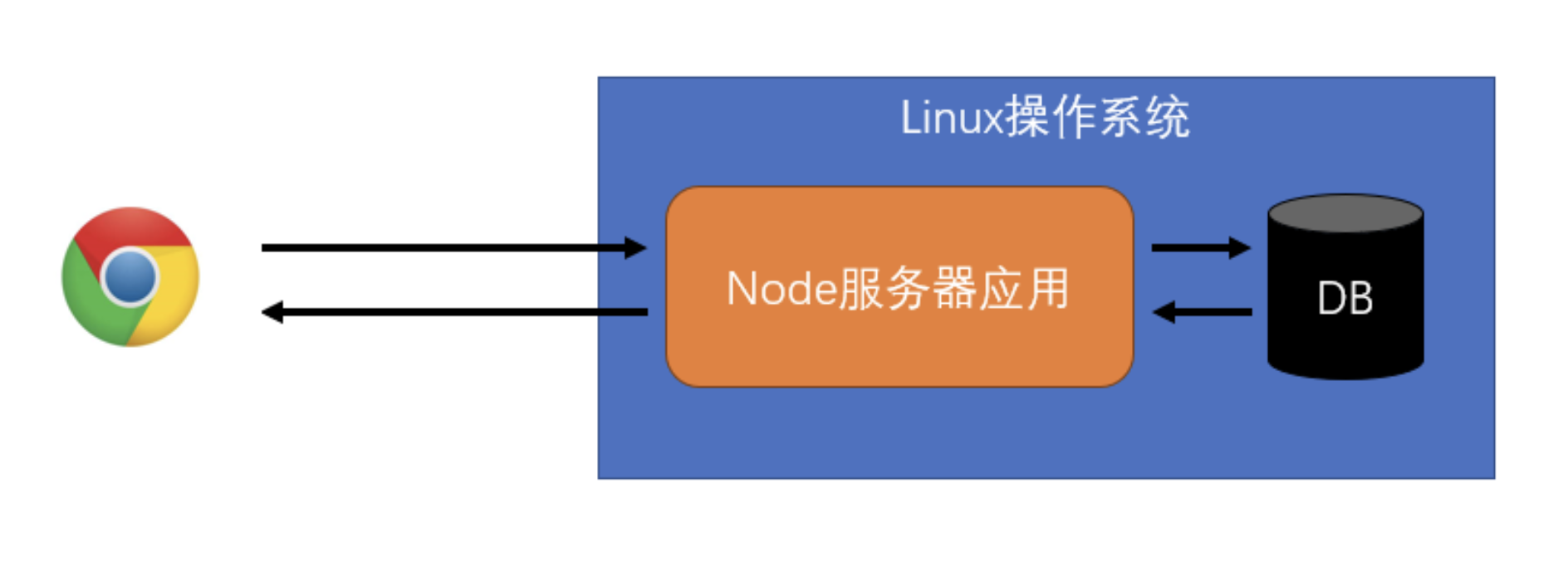
- 结构 2
- 常见结构,通常应用在各种规模的站点上
- Node 服务器不做任何与业务逻辑相关的处理
- 多数时候只负责请求的处理、响应
- 有时会负责额外的功能
- 简单的信息记录,如:请求日志、用户偏好、广告信息
- 静态资源托管
- 缓存
- 后端服务器负责和业务数据库做交互
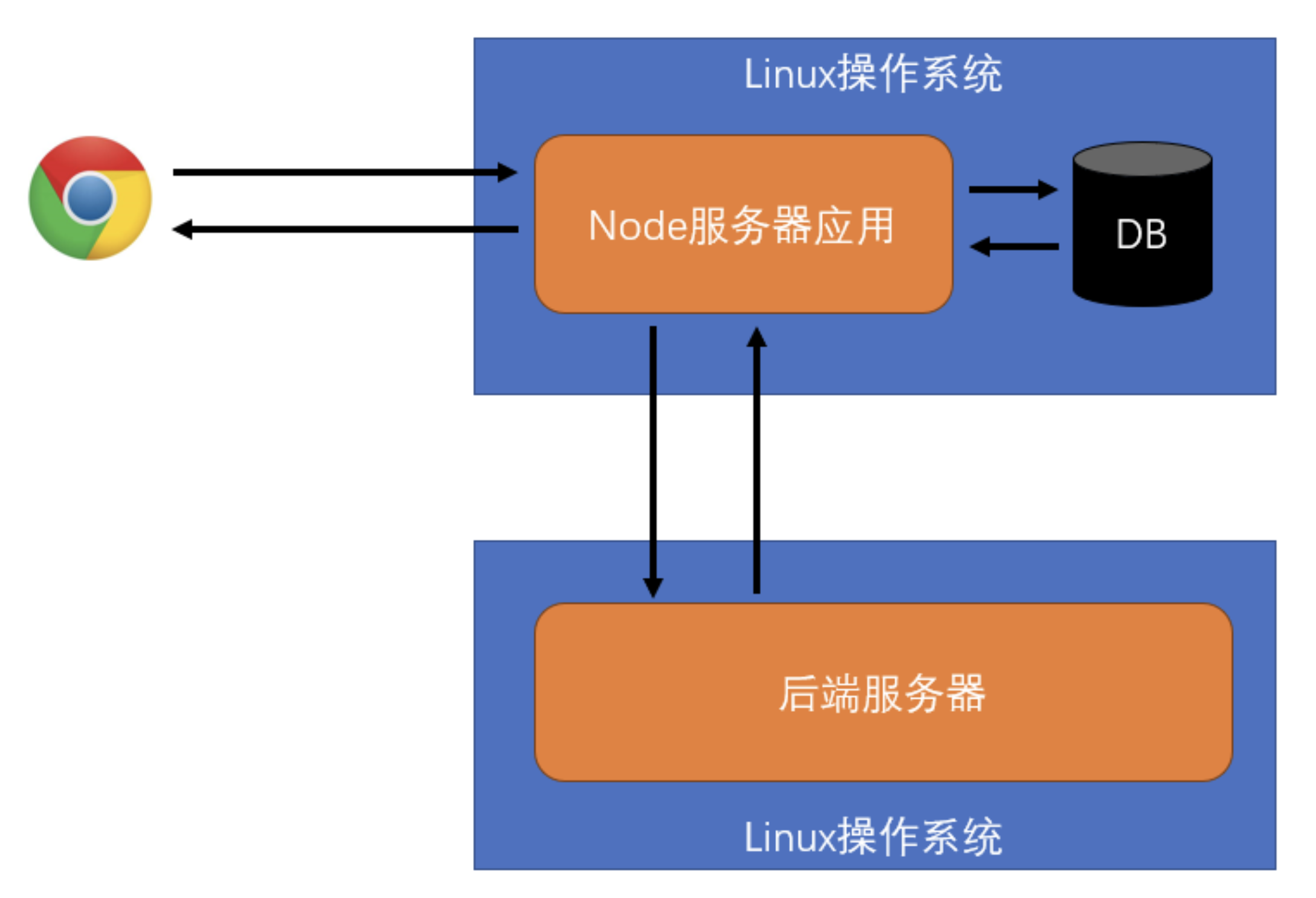
结构 2 好处
- 相较于其他后端编程语言,Node 是解释型语言
- 虽然大数据计算能力差,但是 吞吐量大 ,读写文件速度极快
- 本身是异步的,没有进程切换的负担,可以快速响应大量的用户请求
- 其他后端编程语言,如 Java,是编译型语言
- 读写文件能力较慢
- 大数据计算能力强,可以开启多个线程异步计算
2.全局对象 global
编辑器智能提示
node i @types/node
- global 自身有一个属性 global
- 类似于 window 自身有一个属性 window
- 都是为了便于全局访问全局对象本身
window.window === window; // true
global.global === global; // true
1)setTimeout
- 浏览器环境中返回的是数字(timerId)
- Node 环境中返回的是对象(定时器)
2)setInterval
- 浏览器环境中返回的是数字(timerId)
- Node 环境中返回的是对象(定时器)
3)setImmediate
- 类似于 setTimeout 0
- 但是有区别
4)console
- 和浏览器环境中的 console 一致
5)__dirname
- 获取当前模块所在的目录
- 不是 global 的属性
6)__filename
- 获取当前模块的文件路径
- 不是 global 的属性
7)Buffer
- ES6 出现之前,Node 对 Buffer 类型有需求,于是自定义了一套
- ES6 实现了类型化数组之后,Node 直接继承自 UInt8Array(无符号整型数组,每个数字占 8 位即一个字节,0-255)
- 计算机中存储的基本单位 —— 字节
- 使用时、输出时可能需要使用 十六进制 表示
const buffer = Buffer.from("abcdefg", "utf-8");
// <Buffer 61 62 63 64 65 66 67>
8)process
| 属性/方法 | 说明 |
|---|---|
cwd() | 返回当前 NodeJS 进程的工作目录(命令行目录) 绝对路径 与当前执行的文件所在目录无关 |
exit() | 强制退出当前 Node 进程 可传入退出码,默认为 0,表示正常成功退出,1 表示错误退出 |
argv | 类型为 String[] 获取命令中的所有参数 |
platform | 获取当前的操作系统 输出平台版本,如:win32,表示支持 32 位或以上的操作系统 API |
kill(pid) | 根据进程 ID 杀死进程 |
env | 获取环境变量对象 |
3.Node 的模块化细节
1)模块的查找
- 绝对路径
- 根据绝对路径直接加载模块
require("D:\\test\\index.js");
- 相对路径
./或../- 相对于当前模块
- 转换为绝对路径
- 加载模块
require("./index.js");
- 相对路径
- 检查是否是内置模块
- 如:fs、path 等
- 不是则继续检查当前目录中的 node_modules
- 不是则继续检查上级目录中的 node_modules
- 转换为绝对路径
- 加载模块
- 检查是否是内置模块
// node_modules/abc/index.js
require("abc");
- 关于后缀名
- 不提供后缀名,会自动补全
js、json、node、mjs- 依次补全直到相应文件查找成功为止
require("./a");
- 关于文件名
- 仅提供目录,不提供文件名
- 自动寻找该目录中的 index.js
- package.json 中的 main 字段
- 表示包的默认入口
- 导入或执行包时,仅提供目录,则使用 main 字段值补全入口
- 默认值为 index.js
- 仅提供目录,不提供文件名
// src/index.js
require("./src");
查找顺序
./src✖./src.js✖./src.json✖./src.node✖./src.mjs✖./src/index✔
2)module 对象
- 记录当前模块的信息
- 包括模块间的引用关系、模块 id、模块状态等
- 通过
Module()构造函数创建,该函数仅供 Node 内部使用
3)require 函数
require.resolve("./src");- 获得该目录的绝对路径
- 但是 没有加载模块
4)Node 模块化原理(如何避免模块变量污染全局)
- 模拟 require 函数内部运行机制(伪代码)
function require(modulePath) {
// 1. 将modulePath转换为绝对路径:D:\repository\NodeJS\源码\myModule.js
// 2. 判断是否该模块已有缓存
if (require.cache["D:\\repository\\NodeJS\\源码\\myModule.js"]) {
return require.cache["D:\\repository\\NodeJS\\源码\\myModule.js"].result;
}
// 3. 读取文件内容
// 4. 包裹到一个函数中
function __temp(module, exports, require, __dirname, __filename) {
// 文件内容是动态变化的
console.log("当前模块路径:", __dirname);
console.log("当前模块文件:", __filename);
exports.c = 3;
module.exports = {
a: 1,
b: 2,
};
this.m = 5;
}
// 5. 创建module对象
module.exports = {};
const exports = module.exports;
// 6.绑定this
__temp.call(
module.exports, // this
module,
exports,
require,
module.path,
module.filename,
);
return module.exports;
}
require.cache = {};
- 当执行一个模块或使用 require 函数时,会将模块放置在一个函数环境中(
__temp) this === module.exports === exports- 如果模块中对
module.exports或exports重新赋值,则 this 指向变化 - 模块内尽量不要使用 this
- 如果模块中对
- require 函数最终返回的是 module.exports
// myModule.js
console.log("当前模块的路径:", __dirname);
console.log("当前模块的文件名:", __filename);
/**
* 一开始
* this === module.exports === exports
* => { c: 3 }
*/
exports.c = 3;
/**
* 重新赋值后
* this === exports
* => { c: 3 }
* this !== module.exports
* => { a: 1, b: 2 }
*/
module.exports = {
a: 1,
b: 2,
};
/**
* 重新赋值后
* this === exports
* => { c: 3, m: 5 }
* this !== module.exports
* => { a: 1, b: 2 }
*/
this.m = 5;
// index.js 导入该模块
const result = require("./myModule");
console.log(result); // { a: 1, b: 2 }
4.Node 中的 ES 模块化
- 版本 13 已全面支持 ES 模块化
1)模块化
- 模块化分为 commonjs 和 ES Module
- 默认情况下指的都是 commonjs
- ES Module 是在 V8 引擎内部运行的
- 不是在函数环境中运行,即没有通过参数注入 module 对象
- 开启 ES 模块化的文件中无法使用 commonjs 语法
2)开启 ES Module 的两种方式
- JS 文件后缀名设置为
.mjs- 只有当前文件能使用 ES 模块化
- package.json 文件中 type 属性设置为
module- 该 package.json 文件对应的整个包目录都可以使用 ES 模块化
注意
- 当使用 ES 模块化运行时
- 必须添加
--experimental-modules标记 - 文件后缀名必须写全
- 必须添加
{
"scripts": {
"start": "node --experimental-modules index.mjs"
}
}
3)基本使用
// a.mjs
export default 5;
export const a = 1;
// module.exports = 15; // 会报错
// index.mjs
import * as obj from "./a";
console.log(obj); // { a: 1, default: 5 }
4)ES Module 异步导入模块
import("./a.mjs").then((resolve, reject) => {});
5.基本内置模块
1)os
os.EOL()- end-of-line 一行结束的分隔符
- 不同操作系统不一样
- Unix:
\n - Windows:
\r\n
os.arch()- 获取 CPU 的架构名
- x32/x64
os.cpus()- 获取 CPU 每一个核的信息
- 返回一个数组,数组的长度表示 CPU 是多少核
- 通常用于根据不同内核开辟不同的线程
os.freemem()- 返回当前可用的空闲内存数量
- 单位默认是字节
- 要转换成 MB 则使用
os.freemem() / 1024 ** 2
os.homedir()- 获取用户目录路径
- 如:
/Users/ikuko
os.hostname()- 获取主机名
- 如:
Sutee--IKUKO.local
os.tmpdir()- 获取操作系统的临时目录
- 不同操作系统的临时目录不一样
- 通常用于保存一些临时文件
2)path
path.basename()- 根据文件路径获得文件名
- 只根据传入的路径返回值,不会真的去找是否存在该目录或该文件
- filename:从盘符开始的文件绝对路径,如:
D:\xxx\xxx\a.html,翻译为文件路径 - path:更广泛的含义,指目录或 URL 地址,如:
https://www.baidu.com,翻译为路径 - basename:不包含前缀路径,如:
a.html或a(根据是否传入后缀名返回不同的值),翻译为文件名
const basename = path.basename("dfsdsf/sdsafz/asxcx/a.html");
// a.html
const basename = path.basename("dfsdsf/sdsafz/asxcx/a.html", ".html");
// a
const basename = path.basename("dfsdsf/sdsafz/asxcx/a.jpg", ".html");
// a.jpg
path.sep()- separator,返回操作系统的分隔符
- Unix:
/ - Windows:
\
path.delimiter()- 也是分隔符,通常用于区分环境变量中的分隔符
console.log(process.env.PATH.split(path.delimiter));
path.dirname()- 返回参数路径中的目录名
- 不会检查路径是否存在
console.log(path.dirname("a/b/c/d.js"));
console.log(path.dirname("a/b/c/d"));
// a/b/c
path.extname()- 返回文件的后缀名
- 不会检查文件是否存在
console.log(path.extname("a/b/c/d.js"));
// .js
console.log(path.extname("a/b/c/d"));
// 输出空字符串
path.join()- 将多个参数拼接成完整路径
console.log(path.join("a", "b", "c", "d.js"));
// a/b/c/d.js
console.log(path.join("a", "b", "../", "d.js"));
// a/d.js
path.normalize()- 将路径转换为符合操作系统形式的字符串
- 参数路径中如果包含返回上级目录的符号,会自动定位到相应的目录
path.relative()- 返回参数路径 2 相对于参数路径 1 的相对路径表示形式的字符串
- Webpack 中常用
path.resolve()- 返回参数路径的绝对路径表示形式的字符串
- Webpack 中常用
const path = require("path");
// 获得a.js文件相对于命令行路径(process.cwd())的绝对路径
const absolutePath = path.resolve("./a.js");
// 获得a.js文件相对于当前目录的绝对路径
const absolutePath = path.resolve(__dirname, "./a.js");
关于 `./`
- 只有在 require 函数内部使用时是相对于当前文件目录
- 其他 API 中使用时都是相对于命令行路径(process.cwd())
- 所以通常不使用相对路径,而是借助 path 库转换为绝对路径
const path = require("path");
const filename = path.resolve(__dirname, "./myFile.txt");
3)url
- 返回参数路径的 URL 对象信息
- 字符串解析为对象
- 构造函数:
new URL.URL(str) - 功能函数:
URL.parse(str)
- 构造函数:
- 对象转换为字符串
- 功能函数:
URL.format(obj)
- 功能函数:
const URL = require("url");
const urlObject = new URL.URL("https://nodejs.org:80/a/b/c?t=3&u=5#abc");
/**
{
href: "https://nodejs.org:80/a/b/c?t=3&u=5#abc",
origin: "https://nodejs.org:80",
protocol: "https:",
username: "",
password: "",
host: "nodejs.org:80",
hostname: "nodejs.org",
port: "80",
pathname: "/a/b/c",
search: "?t=3&u=5",
hash: "#abc"
}
*/
4)util
util.callbackify()- 将异步函数转换为回调形式
- 返回一个函数,是一个高阶函数
- 通常用于工程中统一异步处理方式,转换第三方库提供的异步函数
const util = require('util');
const delay(duration = 1000) = async () => {
return new Promise((resolve) => {
setTimeout(() => {
resolve(duration);
}, duration);
})
}
delay(500).then((time) =>{
console.log(time)
});
const delayCallback = util.callbackify(delay);
delayCallback(500, (err, time) => {
console.log(time);
})
Node 中所有回调函数的参数格式
都是两个参数:err 错误对象、data 返回的数据
util.promisify()- 将回调模式的函数转换为异步模式
- 是一个高阶函数
const util = require("util");
const delayCallback = (duration, callback) => {
setTimeout((err, duration) => {
callback(err, duration);
}, duration);
};
const delay = util.promisify(delayCallback);
// delay(500).then((err, time) => {
// console.log(time);
// });
(async () => {
const res = await delay(500);
console.log(res);
})();
util.inherits()- 定义继承关系
- ES6 之后使用
class代替
util.isDeepStrictEqual()- 深度严格比较
- 包括属性值类型不同
- 通常用于比较多级嵌套结构的对象比较
6.文件 I/O
1)I/O input output
- 对外部设备的输入输出
- 外部设备:磁盘、网卡、显卡、打印机...
- I/O 的交互时间远远高于内存和 CPU 的交互时间
- 所以 fs 模块的 API 基本都是异步的
2)fs 模块
fs.readFile()- 读取一个文件
const fs = require("fs");
const path = require("path");
const filename = path.resolve(__dirname, "./files/1.txt");
// 以Buffer格式输出(图片、音频、视频等)
fs.readFile(filename, (err, content) => {
console.log(content);
});
// 以utf-8格式输出(文本等)
fs.readFile(filename, "utf-8", (err, content) => {
console.log(content);
});
// 完整形式
fs.readFile(
filename,
{
encoding: "utf-8",
},
(err, content) => {
console.log(content);
},
);
fs.writeFile()- 向文件写入内容
- 如果文件不存在会自动创建文件再写入
- 如果目录不存在则直接报错
async function test() {
// 写入内容,如果文件不为空则覆盖原文,默认编码为utf-8
await fs.promises.writeFile(filename, buffer);
// 写入内容,如果文件不为空则在原文末尾追加内容
await fs.promises.writeFile(filename, "阿斯顿发发放到发", {
flag: "a", // append
});
// 写入内容,使用Buffer编码
const buffer = Buffer.from("abcde", "utf-8");
await fs.promises.writeFile(filename, buffer);
console.log("写入成功");
}
fs.stat()- 获取文件或目录信息
size:占用字节atime:上次访问时间mtime:上次文件内容被修改的时间ctime:上次文件状态被修改的时间birthtime:文件创建时间isDirectory():判断是否是目录isFile():判断是否是文件
fs.readdir()- 获取目录中的子文件和子目录
- 无法获取子目录中的文件
- 返回一个数组,数组中保存了文件和目录的名称
fs.mkdir()- 创建目录
fs.unlink()- 删除文件
fs.exists()- 官方删除,替换为
fs.stat()或fs.access() - 判断文件或目录是否存在
- 官方删除,替换为
async function exists(filename) {
try {
await fs.promises.stat(filename);
return true;
} catch (err) {
if (err.code === "ENOENT") {
//文件不存在
return false;
}
throw err;
}
}
- Node 提供了
xxxSync()的同步 APIxxx替换为上述异步 API- 会导致 JS 代码阻塞,极其影响性能
- 一般只在程序启动初始化时,运行有限的次数即可
- Node12 之后为 fs 模块新增了
promises子对象- 保留了原有异步 API
- 拷贝原有 fs 模块的异步 API 到该子对象上
- 可以直接作 promise 使用
const fs = require("fs");
const path = require("path");
const filename = path.resolve(__dirname, "./files/1.txt");
async function test() {
const content = await fs.promises.readFile(filename, "utf-8");
console.log(content);
}
test();
API 三种形式
fs.readFile()fs.readFileSync()fs.promises.readFile()
3)练习:读取一个目录中的所有子目录和文件
- 每个目录或文件都是一个对象
- 目录的 size 是 0
- 在操作系统底层,目录其实也是一个文件
- 保存了指向当前目录下文件的指针,不占用内存空间
| 属性/方法 | 说明 |
|---|---|
name | 文件名 |
ext | 后缀名,如果是目录则为空字符串 |
isFile | 是否是一个文件 |
size | 文件大小 |
createTime | 日期对象,创建的时间 |
updateTime | 日期对象,修改的时间 |
getChildren() | 得到目录的所有子文件对象,如果是文件则返回空数组 |
getContent(isBuffer = false) | 读取文件内容,如果是目录则返回 null |
const path = require("path");
const fs = require("fs");
class File {
/**
* 构造函数
* @param {String} filename 绝对路径
* @param {String} basename 文件名
* @param {String} ext 后缀名,如果是目录则为空字符串
* @param {Boolean} isFile 是否是一个文件
* @param {Number} size 文件大小
* @param {Date} createTime 日期对象,创建的时间
* @param {Date} updateTime 日期对象,修改的时间
*/
constructor(filename, basename, ext, isFile, size, createTime, updateTime) {
this.filename = filename;
this.basename = basename;
this.ext = ext;
this.isFile = isFile;
this.size = size;
this.createTime = createTime;
this.updateTime = updateTime;
}
/**
* 生成 File 对象
* @param {String} filename 文件完整路径
* @returns {File} 生成文件对象
*/
static generateFile = async (filename) => {
const stat = await fs.promises.stat(filename);
return new File(
filename,
path.basename(filename),
path.extname(filename),
stat.isFile(),
stat.size,
new Date(stat.birthtime),
new Date(stat.mtime),
);
};
/**
* 读取文件内容
* @param {Boolean} isBuffer 是否以Buffer格式输出
* @returns 文件内容,如果是目录则返回null
*/
getContent = async (isBuffer = false) => {
if (!this.isFile) return null;
return await fs.promises.readFile(this.filename, isBuffer ? "utf-8" : undefined);
};
/**
* 获得当前目录下的所有子文件对象
* @returns 子文件对象,如果是文件则返回空数组
*/
getChildren = async () => {
if (this.isFile) return [];
// 获取所有子文件的文件名
const children = await fs.promises.readdir(this.filename);
// 遍历子文件名数组,生成文件对象
const promises = children.map((subBasename) => {
// 拼接当前目录完整路径和子文件对象名,得到子文件的完整路径
const subFilename = path.resolve(this.filename, subBasename);
// 生成文件对象(Promise)
return File.generateFile(subFilename);
});
return Promise.all(promises);
};
}
/**
* 读取目录中的所有子目录和子文件
* @param {String} dirname 目录名
*/
const readDir = async (dirname) => {
const file = await File.generateFile(dirname);
return file.isFile ? file : await file.getChildren();
};
const main = async () => {
const dirname1 = path.resolve(__dirname, "./myfiles/1");
const res1 = await readDir(dirname1);
console.log(res1[0]); // File {}
const content1 = await res1[0].getContent();
console.log(content1); // <Buffer 61 73 73 61 66 61 73 64 66>
const dirname2 = path.resolve(__dirname, "./myfiles/1.txt");
const res2 = await readDir(dirname2);
console.log(res2); // File {}
const content2 = await res2.getContent(true);
console.log(content2); // abc阿斯顿发发放到发
};
main();
7.文件流
1)流
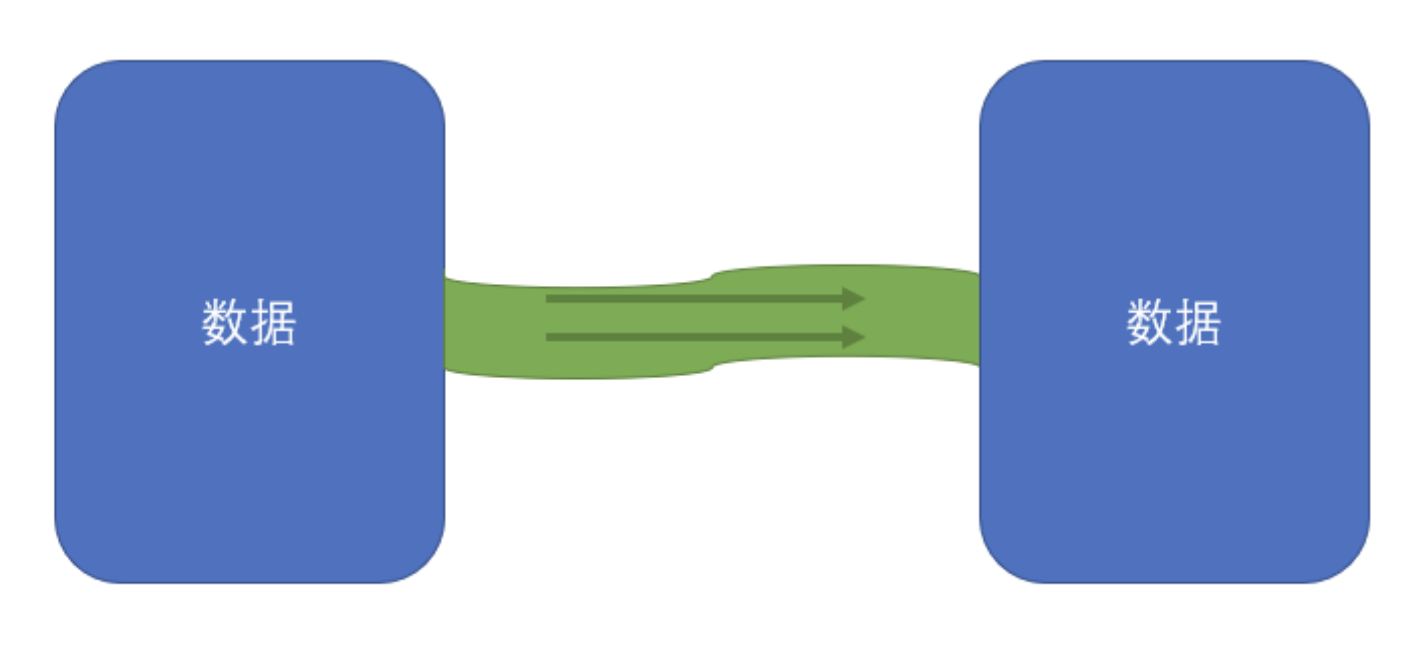
- 指数据的流动,数据从一个地方缓缓地流动到另一个地方
- 流是有方向的
| 分类 | 说明 |
|---|---|
| 可读流 Readable | 数据从源头流向内存 |
| 可写流 Writable | 数据从内存流向源头 |
| 双工流 Duplex | 数据既可从源头流向内存,也可从内存流向源头 实际上是把可读流和可写流封装为一个对象 |
2)流的作用
- 其他介质和内存的数据规模不一致
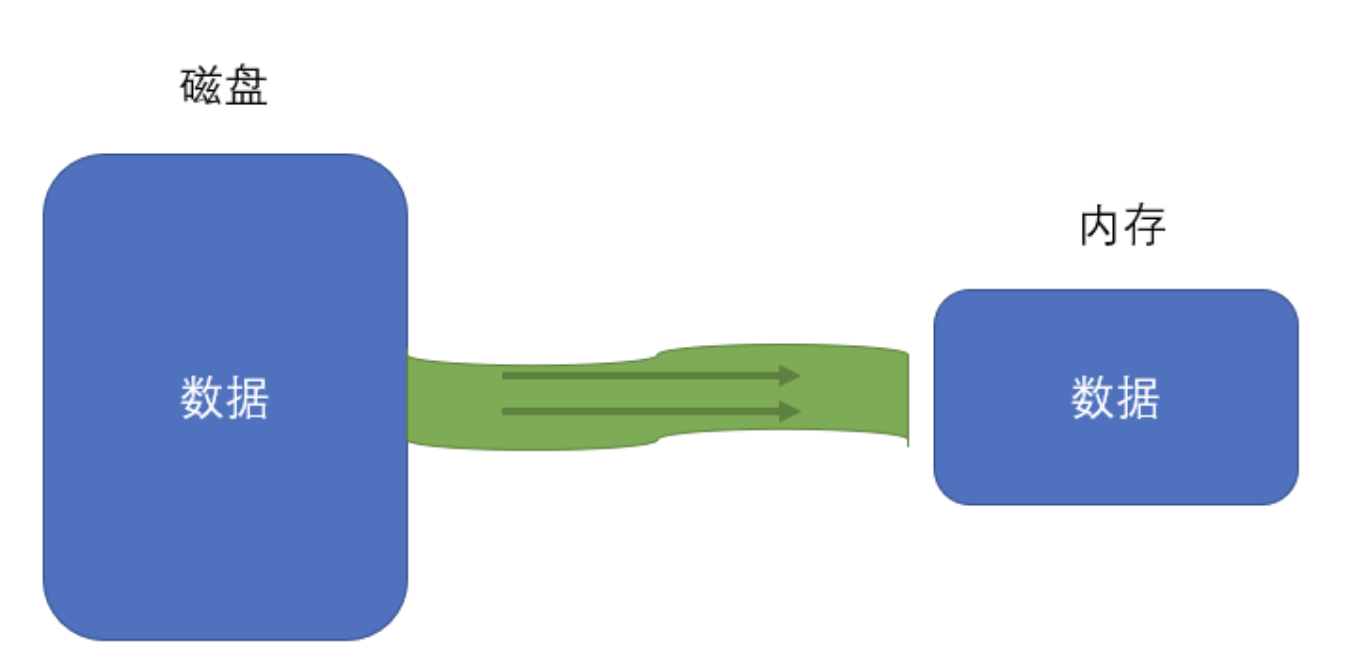
- 其他介质和内存的数据处理能力不一致
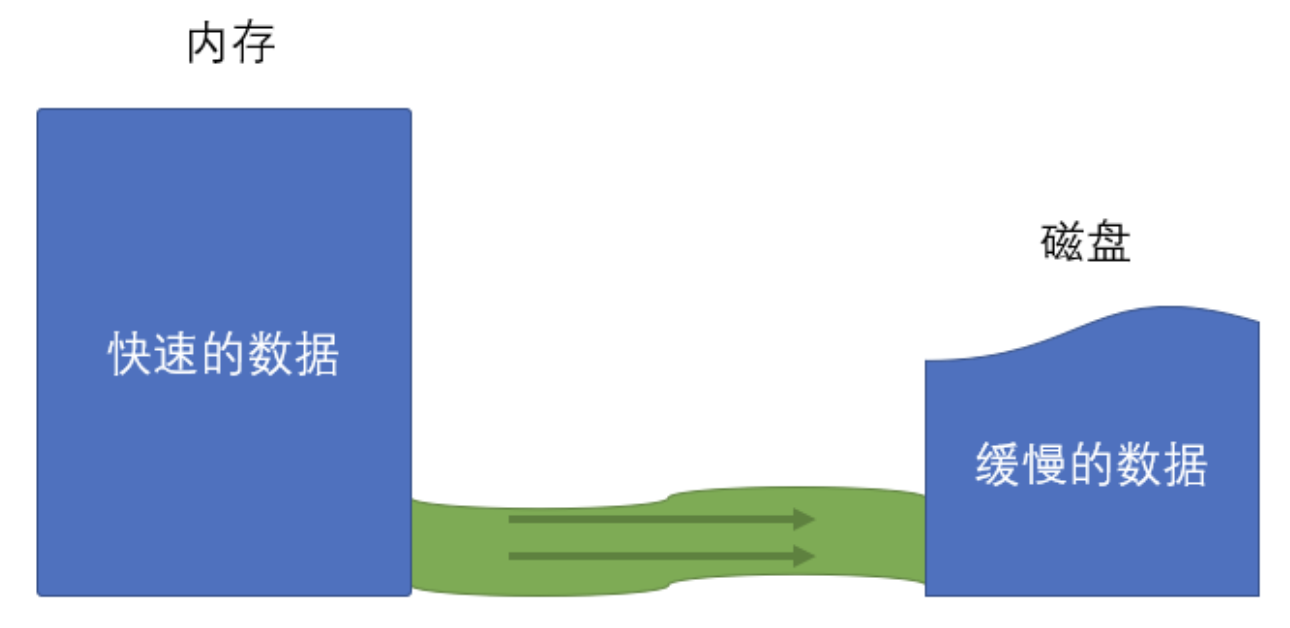
3)文件流的含义
- 内存数据和磁盘文件数据之间的流动
- Node 中不同流的类都应该继承自 Readable、Writable 这两个类
- 内部封装了一些流的常用操作属性和方法
const { Readable, Writable } = require("stream");
4)创建文件可读流
- 用于读取文件内容
fs.createReadStream(path[, options])path:读取的文件路径options:可选配置
| options 配置项 | 含义 |
|---|---|
encoding | 编码方式 |
start | 起始字节 |
end | 结束字节 |
highWaterMark | 每次读取的字节数,默认 64*1024(64KB)如果 encoding: 'utf-8',该数量表示字符数如果 encoding: null,该数量表示字节数 |
- 返回值:Readable 的子类 ReadStream
rs.pause():暂停读取,会触发 pause 事件rs.resume():恢复读取,会触发 resume 事件rs.on(事件名, 处理函数)
| rs.on 事件名 | 含义 |
|---|---|
open | 文件被打开后触发 文件打开并不代表开始读取文件,需要注册 data 事件 |
error | 发生错误时触发 |
close | 文件被关闭后触发 触发方式 1:通过 rs.close() 手动关闭触发方式 2:文件读取完成后自动关闭( autoClose 配置项默认值为 true 时) |
data | 读取到一部分数据后触发,会触发多次 注册该事件后才会真正开始读取 每次读取 highWaterMark 配置项指定的数量回调函数中会附带读取到的数据 若指定了编码,则读取到的数据会自动按照编码转换为字符串 若没有指定编码,则读取到的数据是 Buffer 类型 |
end | 所有数据读取完毕后触发 先触发 end,再触发 close |
const fs = require("fs");
const path = require("path");
const filename = path.resolve(__dirname, "./abc.txt");
const rs = fs.createReadStream(filename, {
encoding: "utf-8",
highWaterMark: 1,
autoClose: true, // 文件读取完毕后自动关闭,默认为true
});
rs.on("open", () => {
console.log("文件被打开了");
});
rs.on("close", () => {
console.log("文件关闭时触发");
});
rs.on("data", (chunk) => {
console.log("读到了一部分数据:", chunk);
rs.pause(); // 暂停读取
});
rs.on("pause", () => {
console.log("暂停读取了");
setTimeout(() => {
rs.resume(); // 恢复读取
}, 1000);
});
rs.on("resume", () => {
console.log("恢复读取了");
});
rs.on("end", () => {
console.log("全部数据读取完毕");
});
5)创建文件可写流
- 向文件中写入内容
fs.createWriteStream(path[, options])path:写入的文件路径options:可选配置
| options 配置项 | 含义 |
|---|---|
flags | 操作文件的方式:w(覆盖)、a(追加)、其他 |
encoding | 编码方式 |
start | 起始字节 |
highWaterMark | 每次最多写入的字节数 默认是 16*1024(16KB) |
- 返回值:Writable 的子类 WriteStream
ws.on(事件名, 处理函数)openerrorclose
ws.end([data])- 结束写入,将自动关闭文件
- 是否自动关闭取决于
autoClose配置,默认为 true
- 是否自动关闭取决于
- data 是可选的
- 表示关闭前的最后一次写入
- 结束写入,将自动关闭文件
ws.write(data)- 写入一组数据
- data 可以是字符串或 Buffer
- 返回一个 Boolean 值
- true:写入通道没有被填满,接下来的数据可以直接写入,无需排队
- false:写入通道目前已被填满,接下来的数据将进入写入队列
- 写入通道大小由 highWaterMark 值确定
const fs = require("fs");
const path = require("path");
const filename = path.resolve(__dirname, "./abc.txt");
const ws = fs.createWriteStream(filename, {
encoding: "utf-8",
highWaterMark: 3,
autoClose: true, // 文件读取完毕后自动关闭,默认为true
});
const flag = ws.write("啊");
console.log(flag); // false
警告
utf-8 的编码方式下,1 个中文字符代表 3 个字节
6)背压问题
- 写入队列是内存中的数据【有限】
- 磁盘处理速度极慢,内存中写入的数据队列排队速度极快
- 可以根据 write 函数的返回值判断是否产生背压
- 返回值为 true
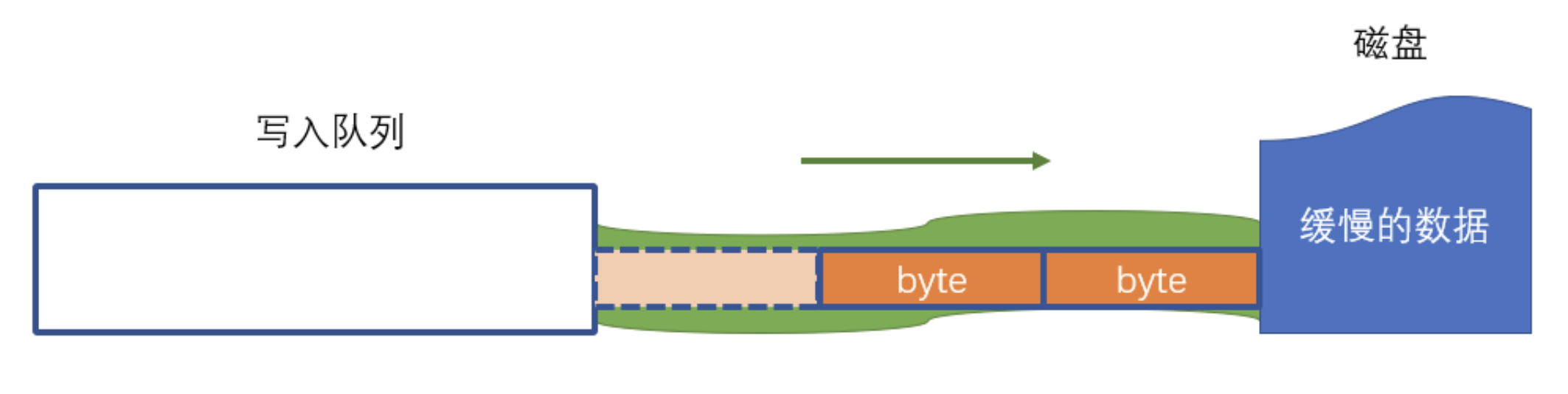
- 返回值为 false
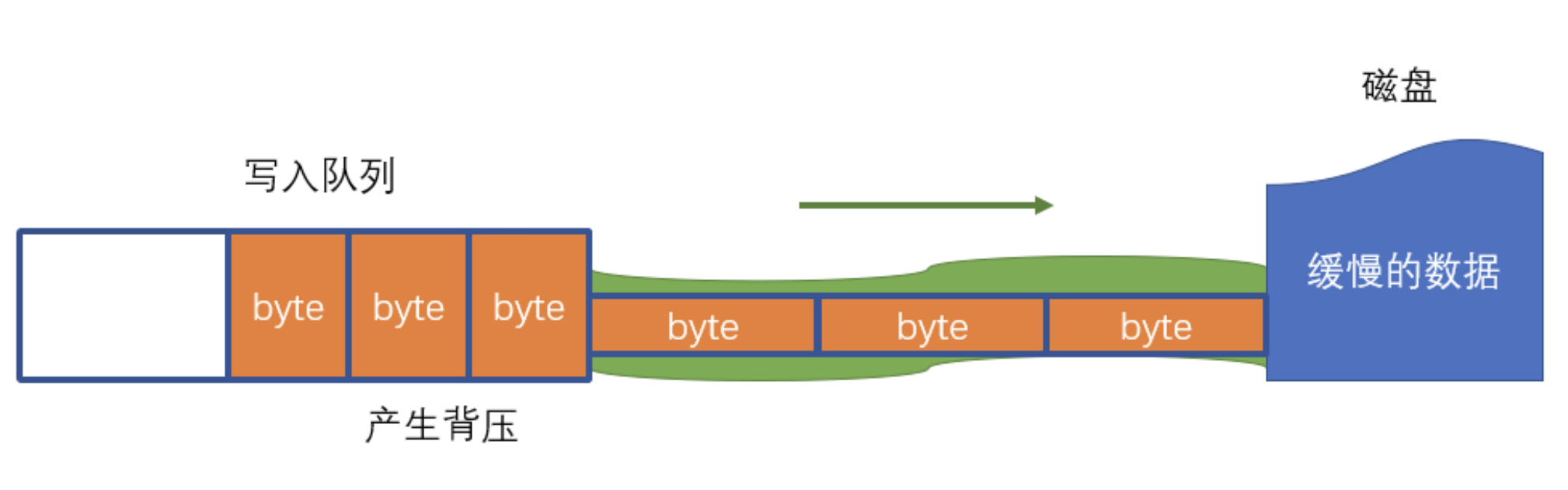
- 当写入队列 排满后 再被清空时,会触发
drain事件- 没有排满,即使清空了也不会触发
const ws = fs.createWriteStream(filename, {
encoding: "utf-8",
highWaterMark: 3,
autoClose: true, // 文件读取完毕后自动关闭,默认为true
});
// 一直写,直到通道达到上限,或者无法直接写入
let i = 0;
const write = () => {
let flag = true;
while (flag && i < 1024 * 1024 * 10) {
flag = ws.write("a");
i++;
}
};
write();
ws.on("drain", () => {
console.log("可以再次写入了");
write();
});
7)解决背压问题
const fs = require("fs");
const path = require("path");
/**
* 拷贝文件方式1
* 直接将文件内容读到内存中,再将内存中的内容写入文件
* 会产生背压问题
*/
const function1 = async () => {
const origin = path.resolve(__dirname, "./temp/abc.txt");
const target = path.resolve(__dirname, "./temp/abc1.txt");
console.time("first");
const content = await fs.promises.readFile(origin);
await fs.promises.writeFile(target, content);
console.timeEnd("first");
console.log("方式1复制成功");
};
/**
* 拷贝文件方式2
* 读取文件内容到内存中直到通道占满时暂停,等清空后继续读取,边读取边写入文件
* 解决背压问题
*/
const function2 = async () => {
const origin = path.resolve(__dirname, "./temp/abc.txt");
const target = path.resolve(__dirname, "./temp/abc2.txt");
console.time("second");
const rs = fs.createReadStream(origin);
const ws = fs.createWriteStream(target);
rs.on("data", (chunk) => {
const flag = ws.write(chunk);
if (!flag) rs.pause(); // 下一次写入就会造成背压,暂停读取
});
ws.on("drain", () => {
rs.resume(); // 继续读取
});
rs.on("close", () => {
// 读完了
ws.end(); // 关闭写入流
console.timeEnd("second");
console.log("方式2复制成功");
});
};
function1();
function2();
/**
* second: 14.531ms
* 方式2复制成功
* first: 16.038ms
* 方式1复制成功
*/
- 可写流封装了解决背压问题的代码
rs.pipe(ws)- 将可读流连接到可写流
- 返回参数的值
- 该方法可解决背压问题
const function2 = async () => {
const origin = path.resolve(__dirname, "./temp/abc.txt");
const target = path.resolve(__dirname, "./temp/abc2.txt");
console.time("second");
const rs = fs.createReadStream(origin);
const ws = fs.createWriteStream(target);
rs.pipe(ws);
rs.on("close", () => {
console.timeEnd("second");
console.log("方式2复制成功");
});
};
8.net 模块
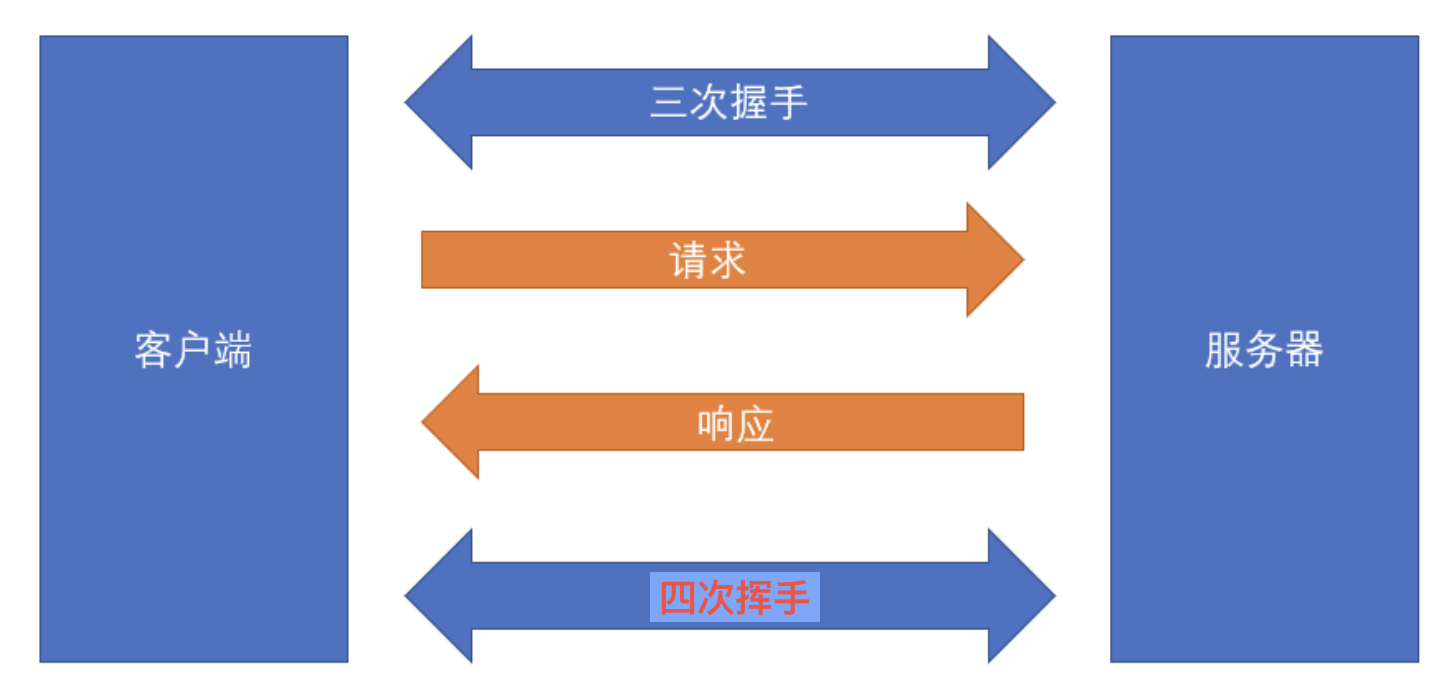
1)回顾 HTTP 请求
- 普通模式
- 长连接模式
- 请求头附带
Connection: keep-alive - 响应头携带
Connection: keep-alive
- 请求头附带
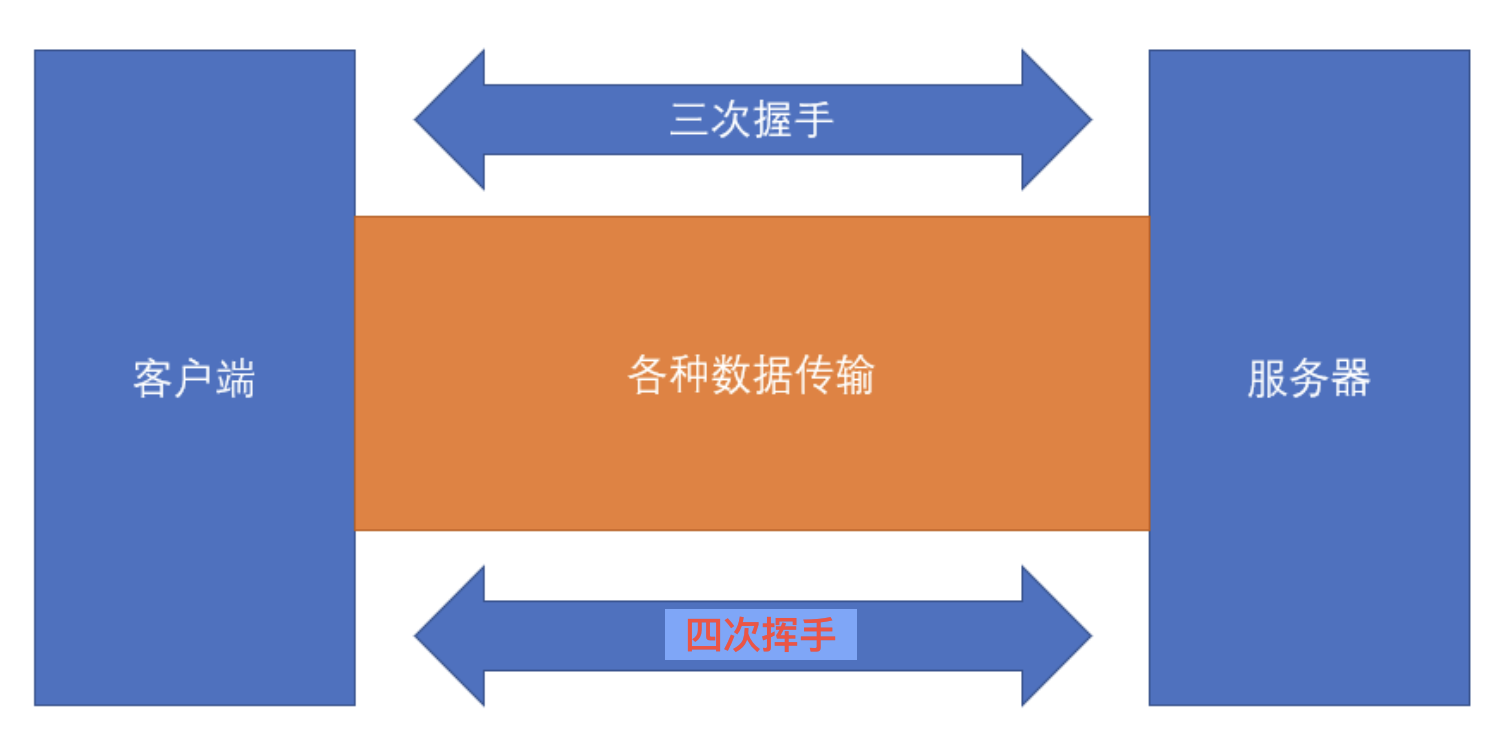
- 三次握手和四次挥手是 TCP/IP 协议的过程
- 一旦建立连接,客户端和服务器可以互相发起请求和响应请求
- HTTP 请求指中间的请求和响应过程
- 基于 TCP/IP 协议之上
- HTTP 规定了通信双方消息传递的模式和消息的格式
- 只能客户端发起请求,服务器响应请求【消息传递的模式】
客户端发送的请求的格式
- HTTP 协议规定的
- TCP/IP 协议无需遵循该格式
- 如果发送的请求格式不正确,服务器会返回 400 Bad request
- 写在模板字符串中时,行头不能有缩进
请求行<br/>
请求头<br/>
<br/>
请求体
- 就算没有传递请求体,也要保留请求头后面空两行
- 否则服务器会一直等待客户端传递请求体
请求行<br/>
请求头<br/>
<br/>
<br/>
2)作用
- net 是一个通信模块
- 可以实现进程间的通信 IPC
- 可以实现 网络通信 TCP/IP
3)创建客户端
net.createConnection(options[, connectListener])- 返回:
socket对象- 一个特殊的文件
- 在 node 中表现为一个双工流对象
- 通过向流写入内容发送数据
- 通过监听流的内容获取数据
- 根据服务器响应头中的 Content-Length 判断 chunk 是否接收完毕

const net = require("net");
// 建立连接通道【内部完成了三次握手和四次挥手】
const socket = net.createConnection(
{
host: "www.baidu.com",
port: 80,
},
() => {
console.log("连接成功");
},
);
// 向服务器发送请求【请求头中标明请求的方法】
socket.write(`GET / HTTP/1.1
Host: www.baidu.com
Connection: keep-alive
`);
let receive = null; // 是否接收到服务器的消息
/**
* 提炼出响应字符串中的响应头和响应体
* @param {String} response 响应字符串
*/
const parseResponse = (response) => {
const index = response.indexOf("\r\n\r\n");
const head = response.substring(0, index);
const body = response.substring(index + 2); // 响应头后面有两个空行
const headers = head.split("\r\n");
// 去掉响应行,将响应头按照":"分割,并且去除首尾空格符
const headerArray = headers.slice(1).map((str) => str.split(":").map((s) => s.trim()));
// 将响应头字符串组装成对象
const header = headerArray.reduce((pre, cur) => {
pre[cur[0]] = cur[1];
return pre;
}, {});
// 将响应体组装成对象
const bodyObject = body.trimStart();
return {
header,
body: bodyObject,
};
};
/**
* 根据 Content-Length 判断是否接收完毕所有字节数
*/
const isReceiveOver = () => {
const contentLength = +receive.header["Content-Length"]; // 需要接收的响应体总字节数
const currentLength = Buffer.from(receive.body, "utf-8").byteLength;
return currentLength > contentLength;
};
// 读取到的数据是二进制字符串
socket.on("data", (chunk) => {
// 直接调用end可能导致服务器消息还未接收完毕就关闭了连接
// console.log("来自服务器的消息", chunk.toString("utf-8"));
// socket.end();
const response = chunk.toString("utf-8");
if (!receive) {
// 第一次接收
receive = parseResponse(response);
isReceiveOver() && socket.end(); // 一次就接收完毕
return;
}
receive.body += response;
if (isReceiveOver()) {
socket.end();
return;
}
});
// 需要客户端调用end关闭连接,服务器才会结束
socket.on("close", () => {
console.log("结束了", receive.body);
});
4)创建服务器
net.createServer()- 返回:
server对象
- 返回:
server.listen(port)- 监听当前计算机中的某个端口,监听后不会结束,等待客户端连接
server.on("listening", () => {})- 开始监听端口后触发的事件
server.on("connection", socket => {})- 当某个连接到来时触发该事件,监听函数会获得一个 socket 对象
- 会触发两次
- 一次是客户端发起请求时的测试连接
- 测试连接成功后才正式建立连接
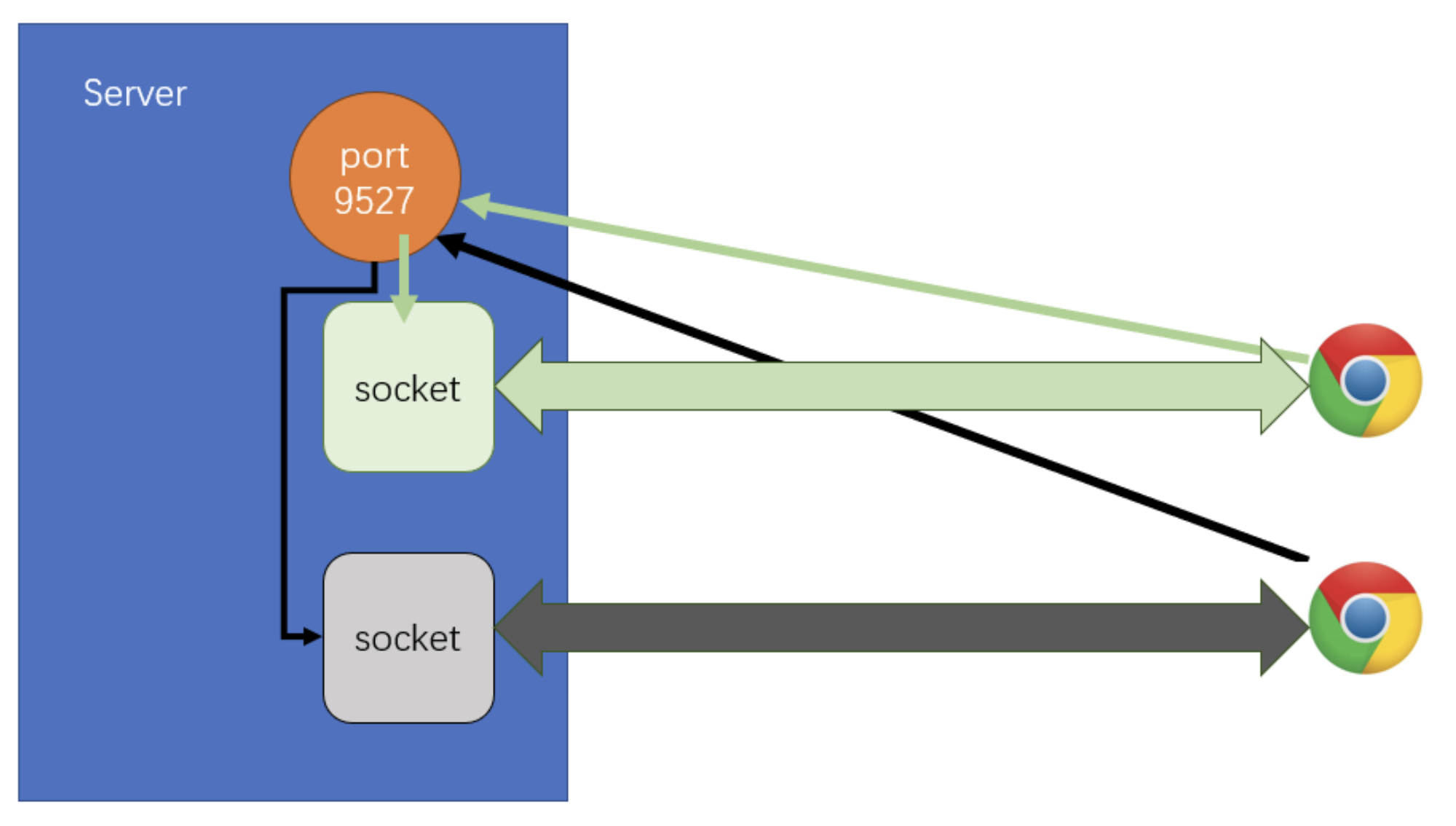
const net = require("net");
const server = net.createServer();
const fs = require("fs");
const path = require("path");
server.listen(9527); // 服务器监听9527端口
server.on("listening", () => {
console.log("server listen 9527");
});
server.on("connection", (socket) => {
console.log("有客户端连接到服务器");
socket.on("data", async (chunk) => {
// console.log(chunk.toString("utf-8"));
const filename = path.resolve(__dirname, "./hsq.jpg");
const bodyBuffer = await fs.promises.readFile(filename);
const headBuffer = Buffer.from(
`HTTP/1.1 200 OK
Content-Type: image/jpeg
`,
"utf-8",
);
const result = Buffer.concat([headBuffer, bodyBuffer]);
socket.write(result);
socket.end();
});
socket.on("end", () => {
console.log("连接关闭了");
});
});
9.http 模块
- 无需手动管理 socket
- 无需手动组装消息格式
1)发送一个 http 请求
http.request(url[, options][, callback])- 返回一个 request 对象,是一个可写流
- 如果不手动调用 end,服务器会认为请求体还未传输完成,响应不会结束
- 响应体不会直接存放到返回值中,因为内容可多可少
- 需要响应体时应该自己用流的方式读取
const http = require("http");
const request = http.request(
"http://duyi.ke.qq.com",
{
method: "GET",
},
(resp) => {
console.log("服务器响应的状态码", resp.statusCode);
console.log("服务器响应头Content-Type", resp.headers["content-type"]);
let body = "";
resp.on("data", (chunk) => {
body += chunk.toString("utf-8");
});
resp.on("end", () => {
console.log(body);
});
},
);
// request.write("a=1&b=2"); // POST请求时写入请求体
request.end(); // 表示消息体结束
2)创建一个服务器
http.createServer([options][, requestListener])- 会自动忽略测试连接,只输出正式连接的数据
const http = require("http");
const url = require("url");
// 处理请求
const handleRequest = (req) => {
console.log("有请求来了");
console.log("请求地址", req.url);
const urlObj = url.parse(req.url);
console.log("请求路径", urlObj);
console.log("请求方法", req.method);
console.log("请求头", req.headers);
let body = "";
req.on("data", (chunk) => {
body += chunk.toString("utf-8");
});
req.on("end", () => {
console.log("请求体", body);
});
};
const server = http.createServer((req, res) => {
handleRequest(req);
res.setHeader("a", "1");
res.setHeader("b", "2");
res.statusCode = 404;
res.write("你好!");
res.end();
});
server.listen(9527);
server.on("listening", () => {
console.log("server listen 9527");
});
3)总结官方文档对应的类
- 客户端发送的请求(请求其他服务器)
- http.request()返回的对象是 ClientRequest 对象
- callback 接收到的响应对象是 IncomingMessage 对象
- 服务器响应的请求(响应其他客户端)
- http.createServer()返回的对象是 Server 对象
- requestListener 接收到的请求对象 req 是 IncomingMessage 对象
- requestListener 接收到的响应对象 res 是 ServerResponse 对象
4)练习:创建一个静态资源服务器
- 根目录创建 public 文件夹
- 可以存储 html、css、js、img 等文件
- Node 不会运行这些文件,但是会读取文件
- 访问
http:localhost:9527/index.html时返回public/index.html文件内容 - 访问
http:localhost:9527/css/index.css时返回public/css/index.css文件内容
- 访问
const http = require("http");
const path = require("path");
const URL = require("url");
const fs = require("fs/promises");
/**
* 获得文件状态
* @param {String} filename 文件路径
* @returns {Stats} 文件信息状态对象,如果函数出错则返回null
*/
const getFileStat = async (filename) => {
try {
return await fs.stat(filename);
} catch {
return null;
}
};
/**
* 获得文件信息
* @param {String} url 请求的路径
* @returns {String} 返回文件内容,文件不存在则返回null
*/
const getFile = async (url) => {
// urlObj.path 包含 query 参数,应该使用 pathname
const urlObj = URL.parse(url);
let filename = path.resolve(
__dirname,
"public",
urlObj.pathname.substring(1), // 去除开头的/才不会使最终路径拼接成盘符根目录
);
let stat = await getFileStat(filename);
// 访问的目录/文件不存在
if (!stat) return null;
// 访问的是目录,拼接 index.html
if (stat.isDirectory()) {
filename = path.resolve(__dirname, "public", urlObj.pathname.substring(1), "index.html");
stat = await getFileStat(filename);
if (!stat) return null;
return await fs.readFile(filename);
}
// 访问的文件存在
return await fs.readFile(filename);
};
/**
* 处理请求
* @param {http.IncomingMessage} req 请求对象
* @param {http.ServerResponse} res 响应对象
*/
const handleRequest = async (req, res) => {
const file = await getFile(req.url);
if (!file) {
res.statusCode = 404;
res.write("Resource is not exist");
} else {
res.write(file);
}
res.end();
};
const server = http.createServer(handleRequest);
server.listen(7000);
server.on("listening", () => {
console.log("Server listening on port 7000");
});
10.https 协议
主要作用
保证数据在传输过程中,不被窃取和篡改,从而保证传输安全

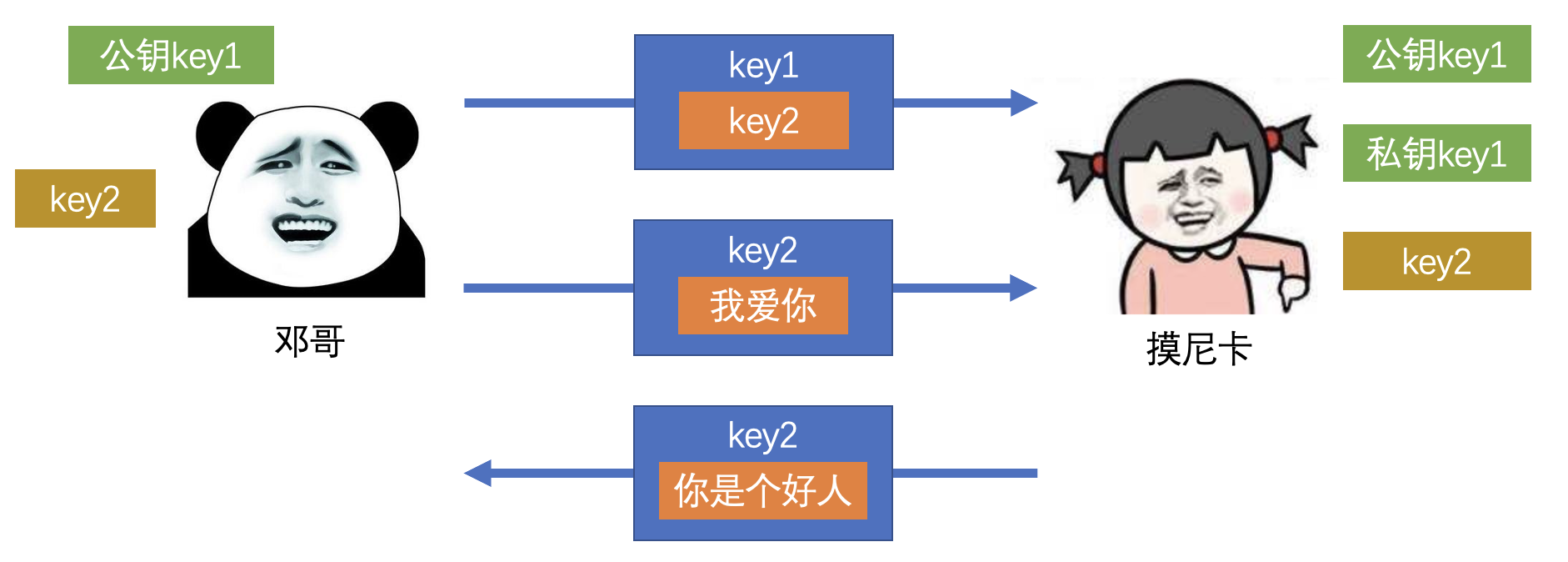
1)对称加密(单密钥加密)
- 加密过程
- 解密过程

- 产生 一个 密钥
- 可以用其加密,也可以用其解密
- 常用算法:DES、3DES、AES、Blowfish 等

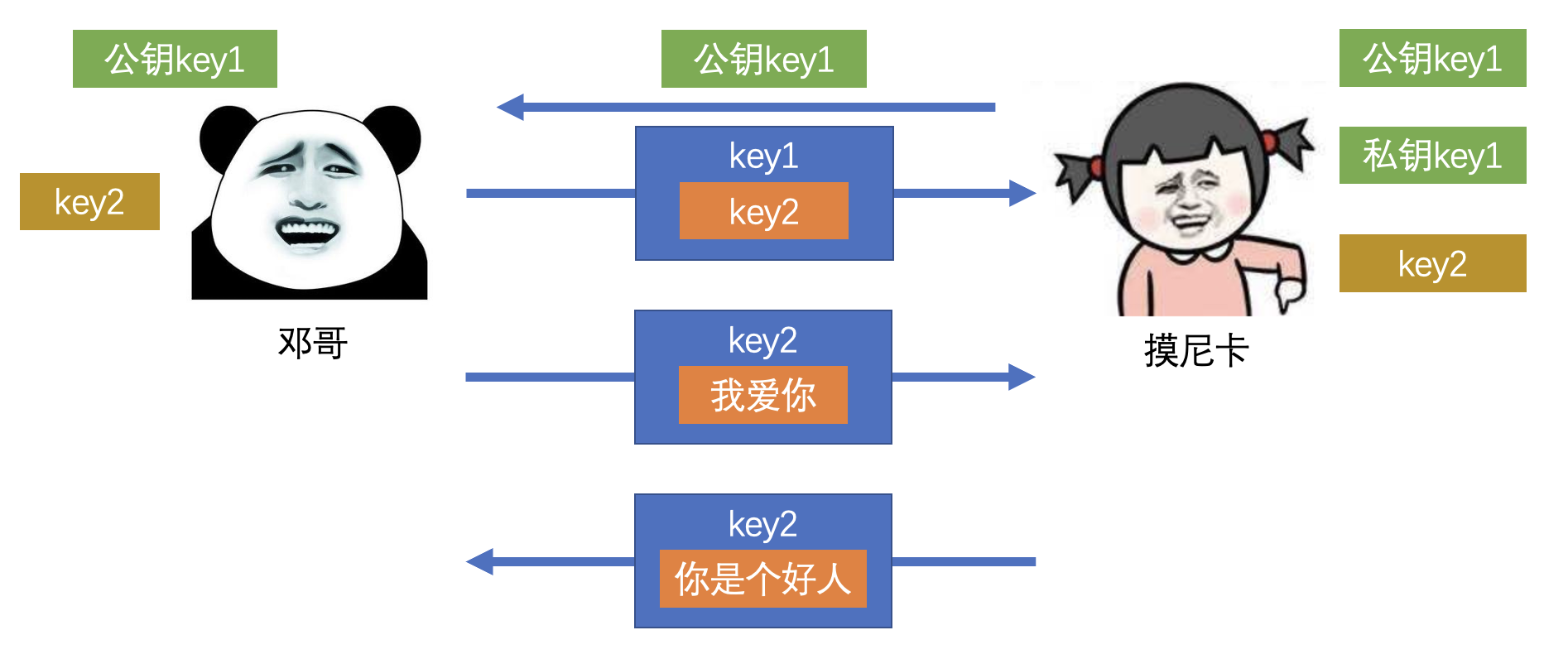
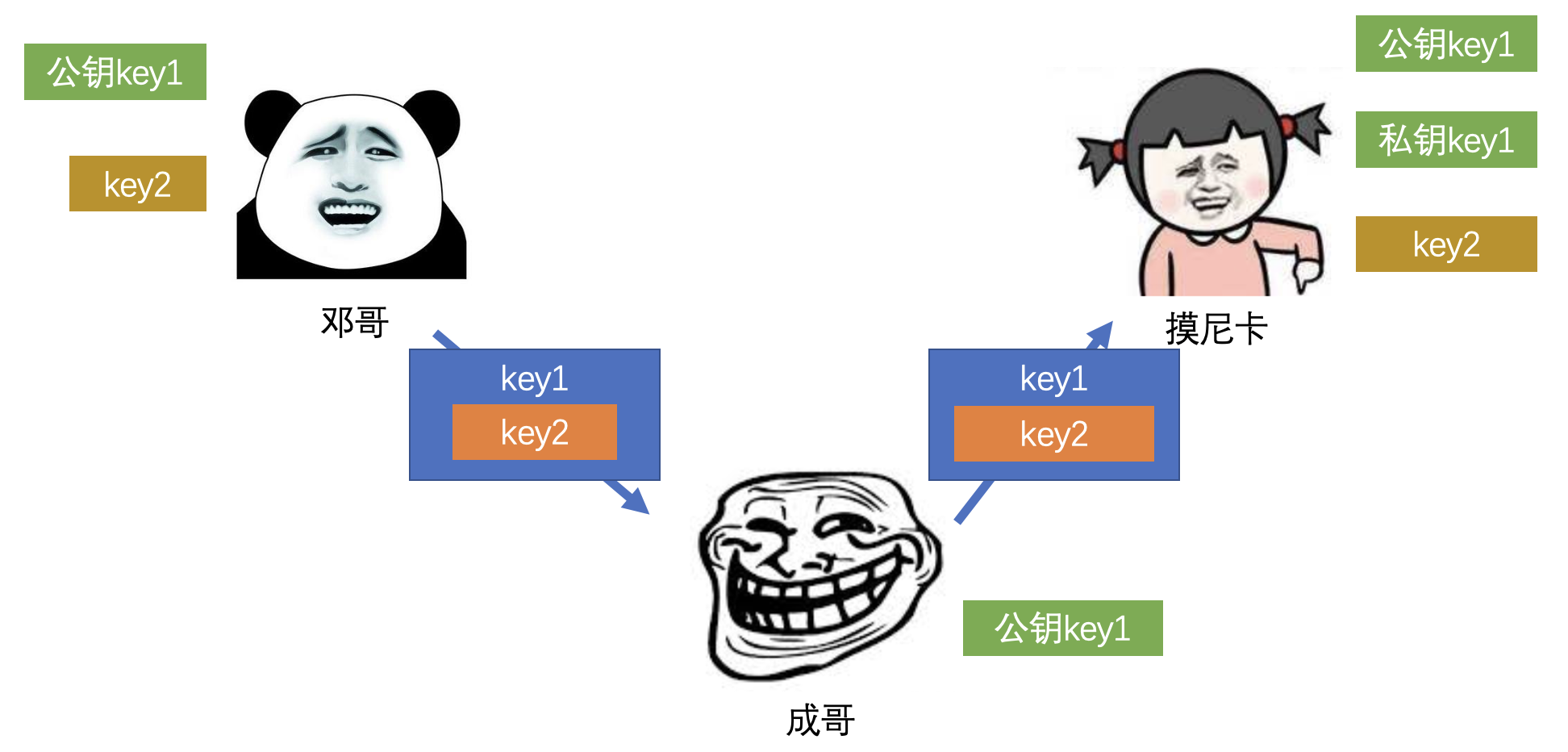
2)非对称加密
- 加密过程

- 解密过程

- 产生 一对 密钥
- 一个用于加密,一个用于解密
- 常用算法:RSA、Elgamal、Rabin、D-H、ECC 等
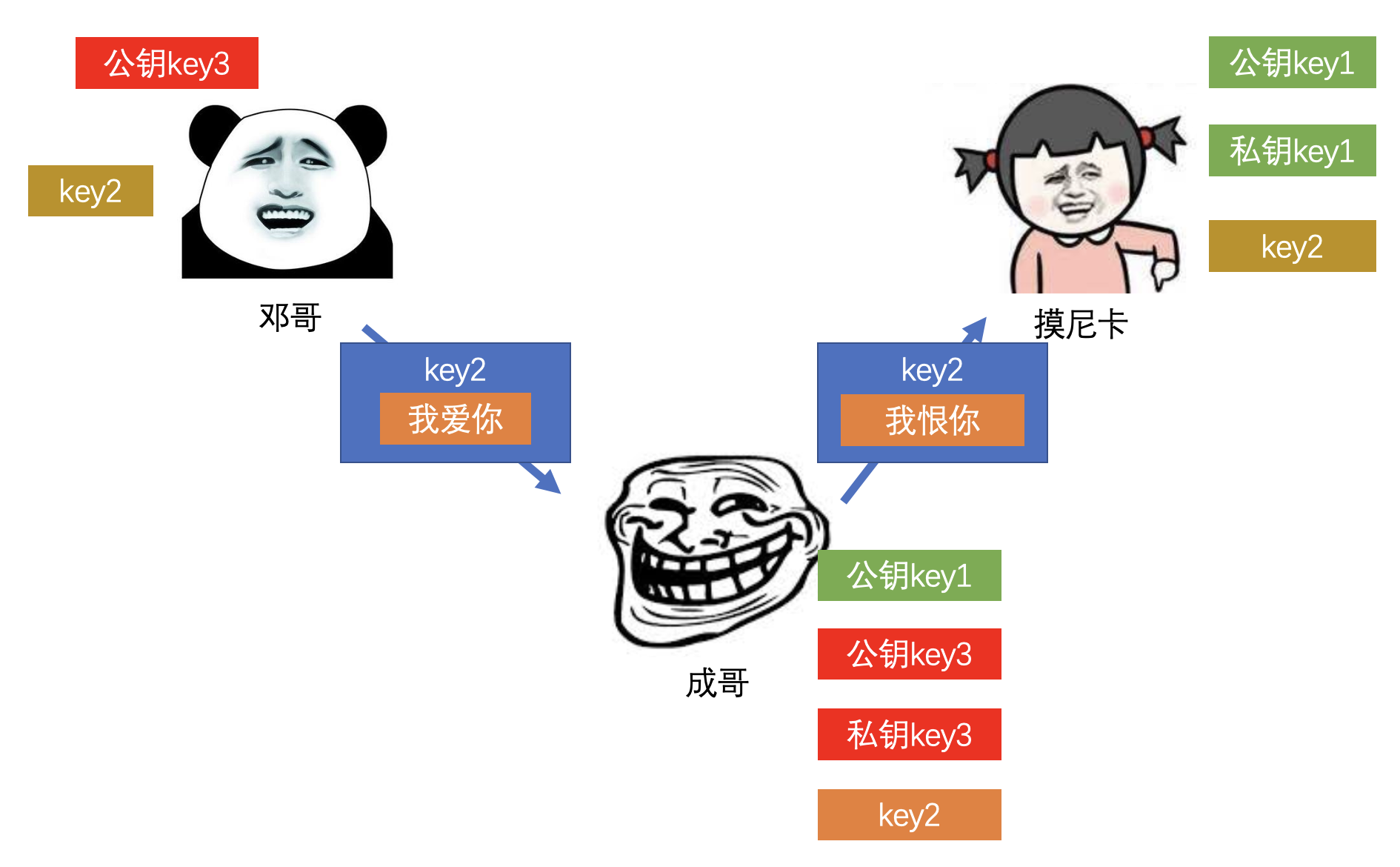
3)证书颁发机构
- CA, Certificate Authority
- 对称算法和非对称算法加密都无法完全避免通信问题,需要引入权威的第三方机构
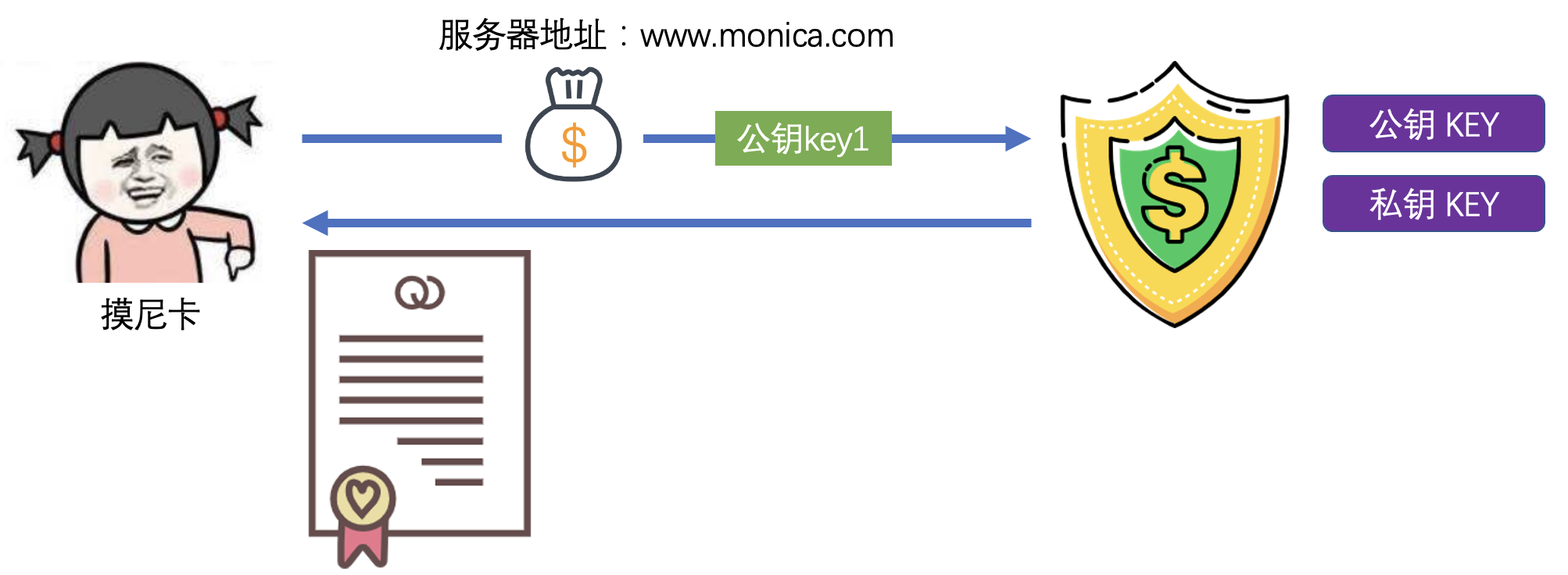
4)证书颁发流程
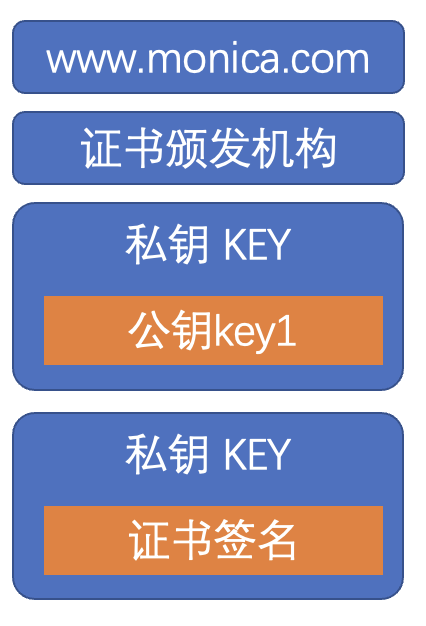
5)证书
- DC, Digital Certificate
- 证书中的服务器公钥和证书签名是通过 CA 的私钥加密的
- 其他终端只能通过 CA 的公钥解密读取,无法重新加密伪造
6)证书签名
- Signature
- 证书签名的算法是公开的
- 使得每一个拿到证书的终端都可以验证签名是否被篡改

7)证书验证流程
- 浏览器获取证书
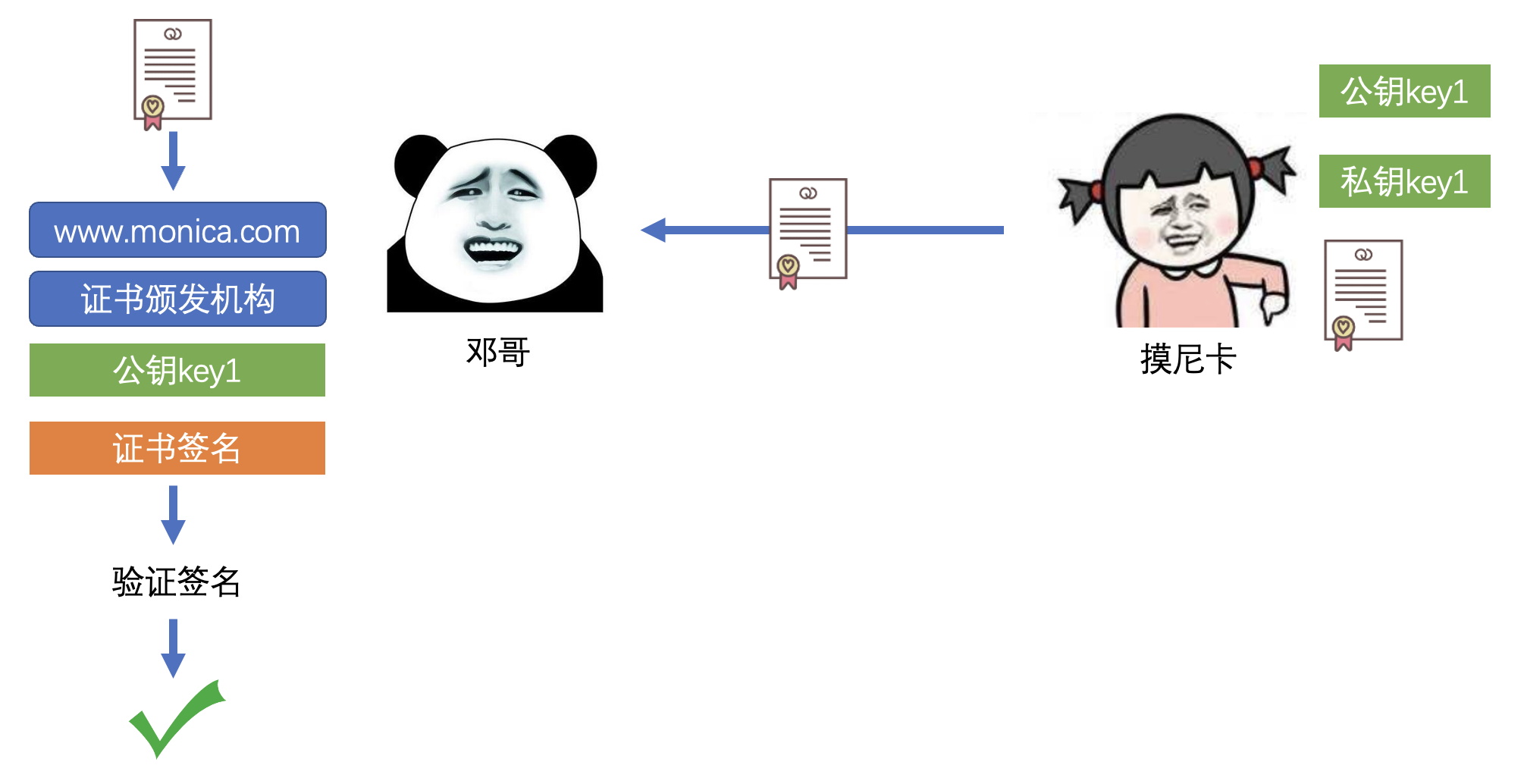
- 无法被篡改
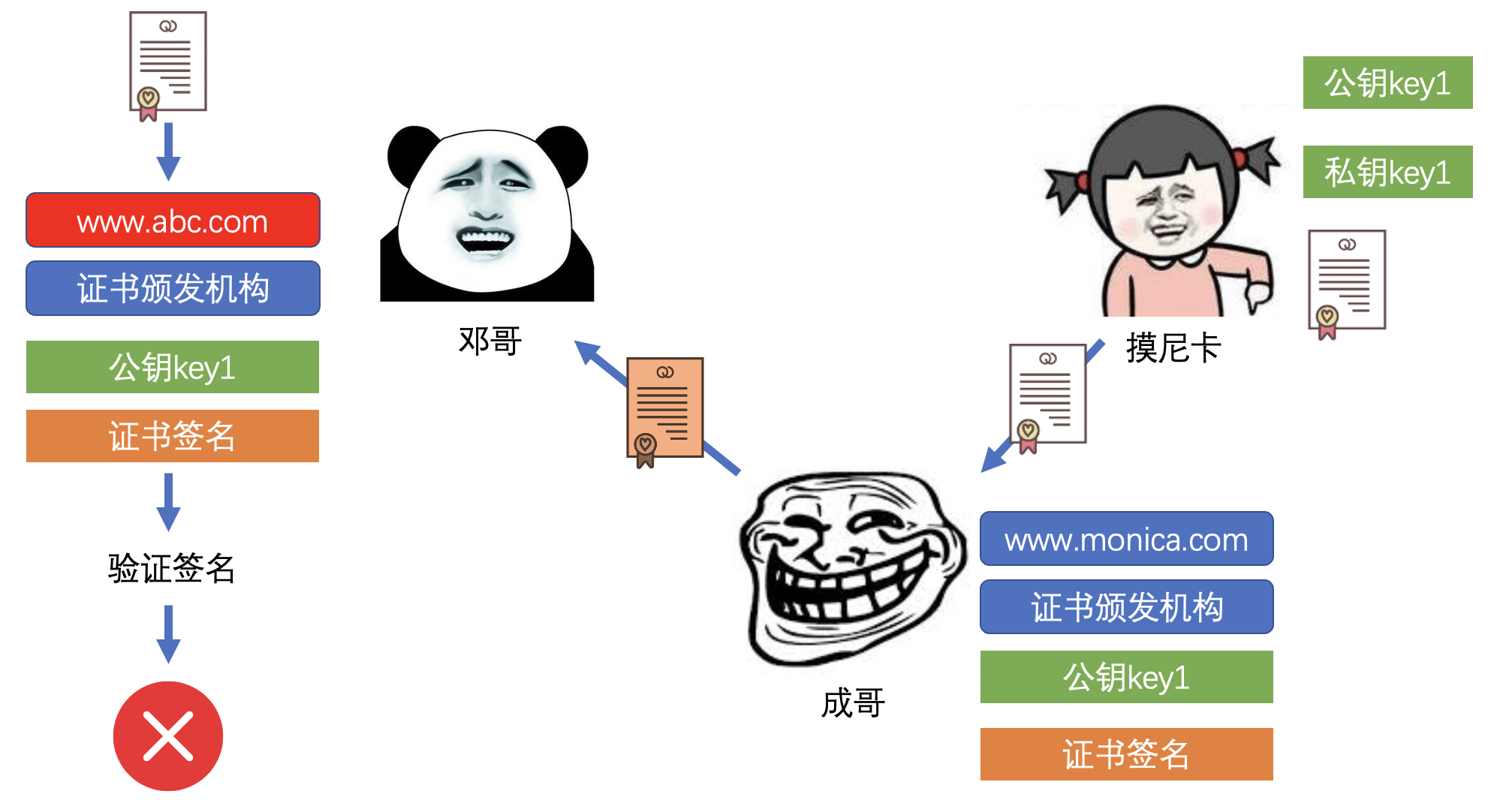
- 通信双方正常通信
- 第三方无法查看和篡改
8)协议
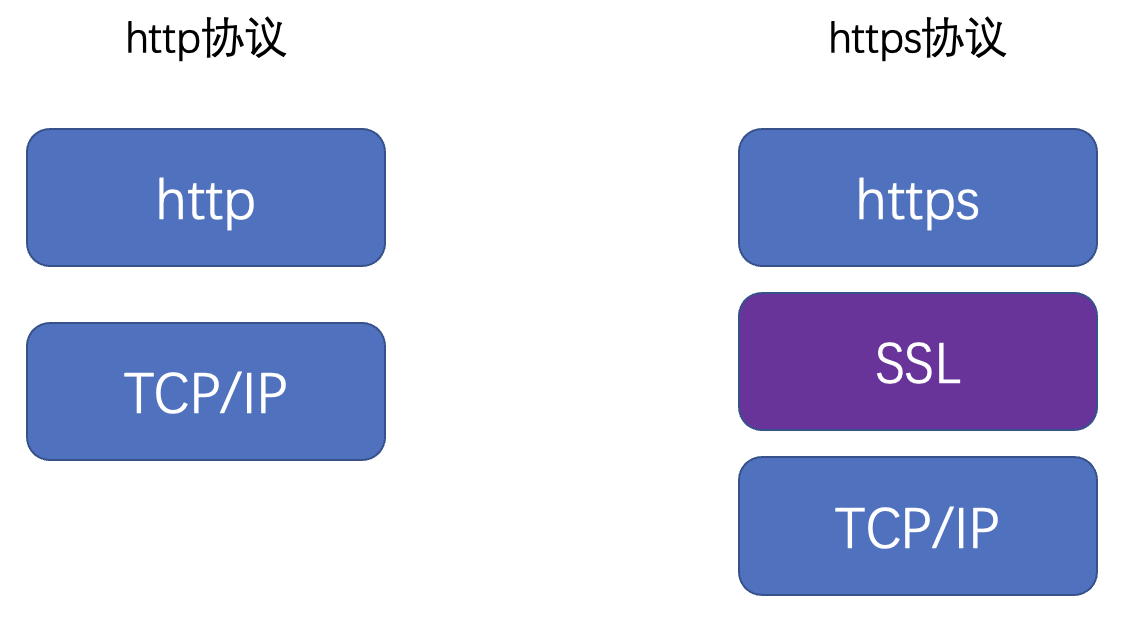
- 浏览器希望,在通过 https 协议请求到的网页中,其他资源都应该使用 https 协议获取
- 服务器:申请证书
- 客户端:访问时使用
https://xxx - https 协议的默认端口号是 443
11.https 模块
1)服务器结构
- 练习结构
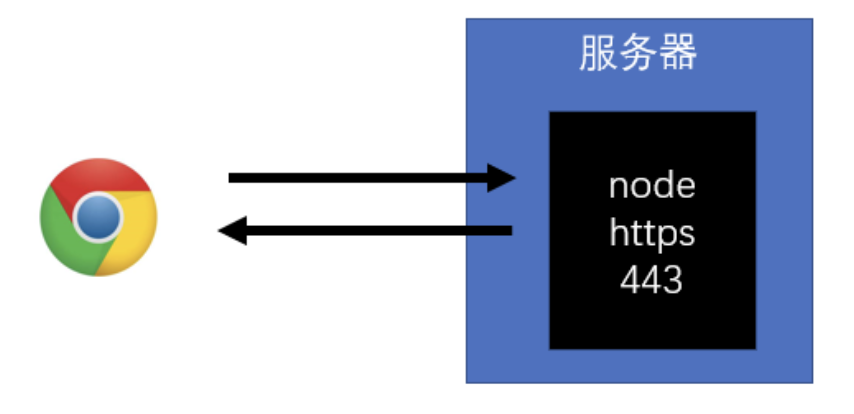
- 常见结构

2)证书准备方式 1:网上购买权威机构证书
- 准备好资金、服务器、域名
- 该方式应用在部署环境中
- 一般都是公司购买
3)证书准备方式 2:本地产生证书
- 开发者作为权威机构发布证书
- 安装 openssl
- 下载源码,自行构建
- 下载 Windows 安装包, 安装路径配置到环境变量中
- Mac 自带
- 通过输入命令 openssl 测试
openssl
- 生成 CA 私钥
genrsa- 密钥对生成算法
-des3- 使用对称加密算法 des3 对私钥进一步加密
- 命令运行过程中会让用户输入密码,该密码将作为 des3 算法的 key
-out ca-pri-key.pem- 将加密后的私钥保存到当前目录的
ca-pri-key.pem文件中 - pem, Privacy-Enhanced Mail(PEM)
- 将加密后的私钥保存到当前目录的
1024- 私钥的字节数
openssl genrsa -des3 -out ca-pri-key.pem 1024
- 生成 CA 公钥(证书请求)
- 通过私钥文件
ca-pri-key.pem中的内容,生成对应的公钥,保存到ca-pub-key.pem文件中 - 运行过程中要使用之前输入的密码来实现对私钥文件的解密
- 其他输入信息
Country Name:国家名 CNProvince Name:省份名 GuangdongLocal Name:城市名Company Name:公司名Unit Name:部门名Common Name:站点名- ...
- 通过私钥文件
openssl req -new -key ca-pri-key.pem -out ca-pub-key.pem
- 生成 CA 证书
- 使用 X.509 证书标准
- 通过证书请求文件
ca-pub-key.pem生成证书 - 使用私钥
ca-pri-key.pem加密 - 将证书保存到
ca-cert.crt文件中
openssl x509 -req -in ca-pub-key.pem -signkey ca-pri-key.pem -out ca-cert.crt
- 生成服务器私钥
openssl genrsa -out server-key.pem 1024
- 生成服务器公钥
openssl req -new -key server-key.pem -out server-scr.pem
- 生成服务器证书
openssl x509 -req -CA ca-cert.crt -CAkey ca-pri-key.pem -CAcreateserial -in server-scr.pem -out server-cert.crt
4)https 模块
const https = require("https");
const server = https.createServer(
{
key: fs.readFileSync(path.resolve(__dirname, "./server-key.pem")), // 私钥
cert: fs.readFileSync(path.resolve(__dirname, "./server-cert.crt")), // 服务器证书
},
handler,
);
server.on("listening", () => {
console.log("server listen 443");
});
server.listen(443);
12.Node 的生命周期(事件循环)
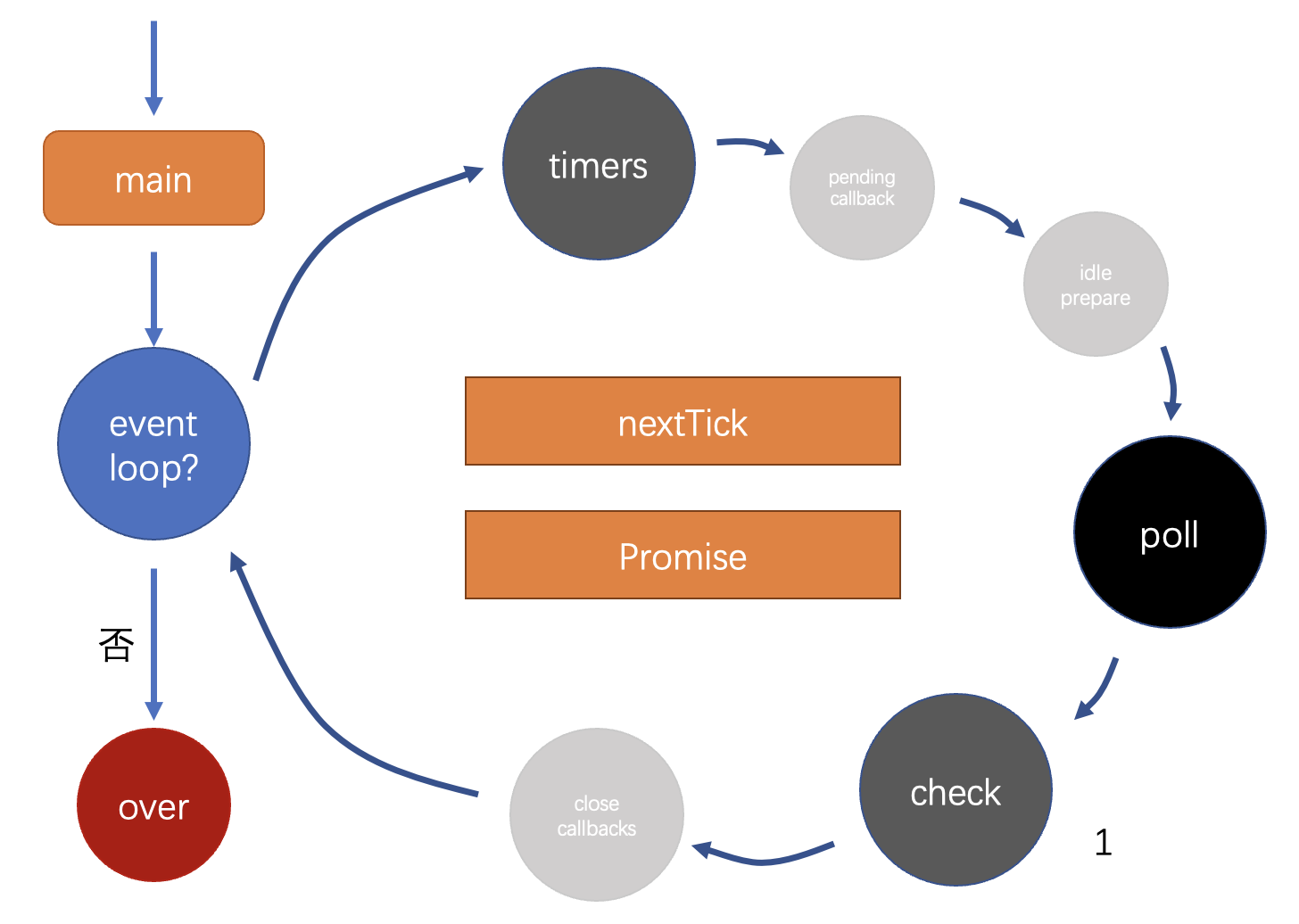
1)main
- Node 程序的入口文件
2)event loop
- 检查是否需要进入事件循环
- 即其他线程是否还有任务未处理,或是否有其他任务正在执行中
- Node 有六个队列,浏览器最多两个
- 图示中事件循环每一个圈代表一个队列
3)timers
- 计时队列
- 存放计时器的回调函数
- 队列中有回调函数则弹出执行,再进入下一个队列【前端开发中这样理解即可】
- 实际上的工作过程
- 每次进入该阶段时,调起计时器线程
- 循环遍历检查计时器线程中的计时器是否到达时间
- 执行到达时间的计时器的回调函数
- 内部其实没有队列的结构,就是一个循环
- 开发时为了方便,可以理解为队列结构
4)poll
- 轮询队列
- 除了 timers 和 check,绝大部分回调都会被放入该队列
- 如:文件的读取、监听用户请求
- 如果 poll 中有回调
- 依次执行回调,直到清空队列
- 如果 poll 中没有回调
- 等待其他队列中出现回调
- 如果其他队列出现回调,结束该阶段,进入下一阶段
- 如果其他队列没有出现回调,持续等待,直到出现回调为止
- 等待其他队列中出现回调
const fs = require("fs");
// 期望200ms后输出,实际输出>300
const start = Date.now();
setTimeout(function f1() {
console.log("setTimeout", Date.now() - start);
}, 200);
fs.readFile("./index.js", "utf-8", function f2() {
console.log("readFile");
const start = Date.now();
while (Date.now() - start < 300) {} // 强制读取文件执行300ms
});
提示
程序卡住不会结束时,都是卡在 poll 阶段
5)check
- 检查队列
- 与 timers 的循环结构不同,check 阶段是真正的队列结构
- 使用
setImmediate的回调会直接进入该队列 - 类似于
setTimeout(0),但也有区别- 进入 timers 队列
setImmediate 和 setTimeout(0) 的区别
- 两者执行效果类似
- 由于 check 阶段是真正的队列结构,只需要简单地操作队列,执行速率高
- timers 队列有线程切换、循环、计算的开销
- 执行顺序无法确定
- setTimeout 其实取不到 0,最少时间是 1ms
- 如果进入队列时还未到 1ms,timers 为空,会经过 poll 阶段来到 check 阶段
- 先执行 setImmediate
- 如果计算机卡了一下,进入队列时超过了 1ms,timers 不为空
- 先执行 setTimeout
setTimeout(() => {
console.log("Bb");
}, 1);
// }, 0);
setImmediate(() => {
console.log("Aa");
});
6)面试题 1
- readFile 整个回调进入 poll 队列,在该阶段等待
- 文件读取完毕后,一定先从 poll 阶段进入 check 阶段
- 所以该情况下一定先执行 setImmediate 再执行 setTimeout
const fs = require("fs");
fs.readFile("./index.js", () => {
setTimeout(() => console.log(1), 0);
setImmediate(() => console.log(2));
});
/**
* 2
* 1
*/
7)nextTick & Promise
- 都是微任务队列
- 不会开启额外线程,期望以最快速度立即执行
警告
在事件循环中,每次执行一个回调之前,都必须先清空 nextTick 和 Promise 队列
- 执行 main
- 输出 3,同步代码
- check:1
- nextTick:2
- Promise:4
- 进入事件循环
- 输出 2,nextTick 加入 6
- 输出 6
- 输出 4,nextTick 加入 5
- 输出 5
- 依次检查 timers、poll、check,输出 1
setImmediate(() => {
console.log(1);
});
process.nextTick(() => {
console.log(2);
process.nextTick(() => {
console.log(6);
});
});
console.log(3);
Promise.resolve().then(() => {
console.log(4);
process.nextTick(() => {
console.log(5);
});
});
/**
* 3
* 2
* 6
* 4
* 5
* 1
*/
8)面试题 2
- 执行 main
- 输出 script start
- timers:1ms 后加入 setTimeout0、3ms 后加入 setTimeout3
- check:setImmediate
- nextTick:nextTick
- 执行 async1
- 输出 async1 start
- Promise:async1 end
- 执行 async2
- 输出 async2
- 执行 new Promise
- 输出 promise1、promise2
- Promise:async1 end、promise3
- 输出 script end
- 进入事件循环
- 清空 nextTick
- 输出 nextTick
- 情况 Promise
- 输出 async1 end
- 输出 promise3
- 输出结果可能性 1
- 输出 setImmediate
- 输出 setTimeout0
- 输出 setTimeout3
- 输出结果可能性 2
- 输出 setTimeout0
- 输出 setImmediate
- 输出 setTimeout3
- 输出结果可能性 3
- 输出 setTimeout0
- 输出 setTimeout3
- 输出 setImmediate
- 清空 nextTick
async function async1() {
console.log("async1 start");
await async2();
console.log("async1 end");
}
async function async2() {
console.log("async2");
}
console.log("script start");
setTimeout(function () {
console.log("setTimeout0");
}, 0);
setTimeout(function () {
console.log("setTimeout3");
}, 3);
setImmediate(() => console.log("setImmediate"));
process.nextTick(() => console.log("nextTick"));
async1();
new Promise(function (resolve) {
console.log("promise1");
resolve();
console.log("promise2");
}).then(function () {
console.log("promise3");
});
console.log("script end");
/**
* script start
* async1 start
* async2
* promise1
* promise2
* script end
* nextTick
* async1 end
* promise3
* setImmediate
* setTimeout0
* setTimeout3
*/
13.EventEmitter
- Node 事件管理的通用机制
res.on("data", () => {});
socket.on("close", () => {});
- 内部维护多个事件队列,实际上就是一个数组对象
{
"abc": [fn1, fn2, fn3],
"bcd: "[fn1]
}
1)创建一个事件处理对象
- 可以注册事件,也可以触发事件
- 触发事件时,会依次运行注册的时间函数(同步执行)
const { EventEmitter } = require("events");
const ee = new EventEmitter();
const fn = () => {
console.log("abc事件触发了");
};
// 注册事件
ee.on("abc", fn);
// 移除注册事件
ee.off("abc", fn);
ee.once("bcd", () => {
console.log("只触发一次");
});
// 触发事件
ee.emit("abc");
ee.emit("bcd");
// 传递参数
ee.on("cdf", (data1, data2) => {
console.log("该事件触发了", data1, data2);
});
ee.emit("cdf", 123, 456);
2)封装网络请求模块
- MyRequest.js
const EventEmitter = require("events");
const http = require("http");
module.exports = class extends EventEmitter {
constructor(url, options) {
super();
this.url = url;
this.options = options;
}
send(body = "") {
const request = http.request(this.url, this.options, (res) => {
let result = "";
res.on("data", (chunk) => {
result += chunk.toString("utf-8");
});
res.on("end", () => {
this.emit("response", res.headers, result);
});
});
request.write(body);
request.end();
}
};
- index.js
const MyRequest = require("./MyPractice");
const request = new MyRequest("http://duyi.ke.qq.com");
request.send();
request.on("response", (headers, body) => {
console.log(headers);
console.log(body);
});
(二)MySQL
1.数据库简介
- 解决内存和磁盘存储数据格式不一致的问题
- 内存:只能暂时存储,和 CPU 交互,读取速度快
- 磁盘:字符串或二进制,文件形式,可以永久存储
1)作用
- 持久的存储数据
- 数据存储在硬盘文件中
- 备份和恢复数据
- 快速地存取数据
- 权限控制
2)类型
- 关系型数据库
| 项目 | 说明 |
|---|---|
| 特点 | 以表和表的关联构成的数据结构 |
| 优点 | 能表达复杂的数据关系 强大的查询语言,能精确查找想要的数据 |
| 缺点 | 读写性能较差,尤其是海量数据的读写 数据结构比较死板,不能随意增删改数据列 |
| 用途 | 存储结构复杂的数据 |
| 代表 | Oracle、MySQL、SQL Server |
- 非关系型数据库
| 项目 | 说明 |
|---|---|
| 特点 | 以极其简单的结构存储数据 文档型、键值对型 |
| 优点 | 海量数据读写效率很高 格式灵活可以随意增删改数据属性 |
| 缺点 | 难以表示复杂的数据结构 对于复杂查询效率低 |
| 用途 | 存储结构简单的数据 |
| 代表 | MongoDB、Redis、Membase |
- 面向对象数据库
- 适于 Java、C# 等强类型的面向对象语言
- 当需要将数据从内存原封不动地存储到硬盘中时,需要经过该数据库的适配
- 通常商业机构才会使用,需要收费
3)术语
| 缩写 | 全称 | 含义 |
|---|---|---|
| DB | Database | 数据库 |
| DBA | Database Administrator | 数据库管理员 |
| DBMS | Database Management System | 数据库管理系统 |
| DBS | Database System | 数据库系统 DBS 包含 DB、DBA、DBMS |
2.安装 MySQL
1)MySQL 特点
- 属于关系型数据库
- 瑞典 MySQL AB 公司开发,已被 Oracle 收购
- 开源
- 轻量
- 快速
2)下载
3)使用
- 进入 mysql 命令交互
mysql -uroot -p
- 查看当前数据库字符编码
show variables like 'character\_set\_%';
- 修改
my.ini文件中的默认字符编码C:\ProgramData\MySQL\MySQL Server 8.0
default-character-set=utf8mb4
character-set-server=utf8mb4
- 将
my.ini文件放置到C:\Program Files\MySQL\MySQL Server 8.0\目录下 - 停止 MySQL(Windows)
net stop mysql80
- 启动 MySQL(Windows)
net start mysql80
- 查看当前拥有的数据库
show databases;
4)可视化工具
- Navicat
3.数据库设计
1)SQL
- Structured Query Language 结构化查询语言
- 大部分关系型数据库都拥有基本一致的 SQL 语法
| 分支 | 全称 | 操作对象 |
|---|---|---|
| DDL | Data Definition Language 数据定义语言 | 数据库对象(库、表、视图、存储过程) |
| DML | Data Manipulation Language 数据操控语言 | 数据库中的记录 |
| DCL | Data Control Language 数据控制语句 | 用户权限 |
2)管理库
- 创建库
create database `test`;
- 切换当前库
use test;
- 删除库
drop database test;
3)管理表
- 创建表
- 字段
- 字段名
- 字段类型
- 是否为 null
- 是否自增
- 默认值
| 字段类型 | 含义 |
|---|---|
bit | 占 1 位,0 或 1,true 或 false |
int | 占 32 位,整数 |
decimal(M, N) | 能精确计算的实数 M 是总的数字位数,N 是小数位数 |
char(n) | 固定长度位 n 的字符,不足字符自动补齐空格 |
varchar(n) | 长度可变,最大长度位 n 的字符 |
text | 大量的字符 |
date | 仅日期 |
datetime | 日期和时间 |
time | 仅时间 |
create table student (
name varchar(100) not null,
birthday date not null,
sex bit not null default 0,
stuno int null auto_increment,
primary key (stuno)
);
- 修改表
alter table student
add column phone varchar(11) not null after sex;
- 删除表
drop table student;
4)主键和外键
- 根据设计原则,每张表都要有主键
- 主键
- 主键必须满足以下要求
- 唯一
- 不可更改
- 无业务含义
- 可以是数字、字符串、UUID(全球唯一的长字符串)
- 主键必须满足以下要求
select uuid();
- 外键
- 用于产生表关系的列
- 外键列会连接到另一张表(或自己)的主键
alter table student
add foreign key (classid) references class(id);
5)表关系
| 关系 | 描述 | 实现 |
|---|---|---|
| 一对一 | 一个 A 对应一个 B,一个 B 对应一个 A 如:用户和用户信息 | 把任意一张表的主键同时设置为外键 |
| 一对多 | 一个 A 对应多个 B,一个 B 对应一个 A A 和 B 是一对多,B 和 A 是多对一 如:班级和学生、用户和文章 | 在多一端的表上设置外键,对应到另一张表的主键 |
| 多对多 | 一个 A 对应多个 B,一个 B 对应多个 A 如:学生和老师 | 需要新建一张关系表,关系表至少包含两个外键,分别对应到两张表 |
6)三大设计范式
- 要求数据库表的每一列都是不可分割的原子数据项
- 如:如果业务需要省市区可选,则地址列不能单独用“住址”列存储“中国广东省深圳市”
- 非主键列必须依赖于主键列
- 如:学生表不应该有“广告名称”列,广告和学生没有关系
- 非主键列必须直接依赖于主键列
- 如:学生表不应该有“班级名称”列,班级和学生是间接关系
4.表记录的增删改查(CRUD)
- DML,Data Manipulation Language,数据操控语言
1)增 Create
-- 增加语句
insert into student (stuno, `name`, birthday, sex, phone, classid)
values ('400', '成哥', '1900-1-1', true, '13344415246', 2);
insert into student (stuno, `name`, birthday, sex, phone, classid)
values ('500', '成哥', '1900-1-1', true, '13344415246', 2),
('501', '邓哥', '1900-1-2', '13344445556', 2);
2)查 Retrieve
3)改 Update
update student set `name` = '邓旭明' where id = 12;
4)删 Delete
delete from student where id = 11;
5.单表基本查询
select XXX from XXX where XXX order by XXX limit XXX;
- 运行顺序
from=>where=>select=>order by=>limit
1)select
- 别名
select ismale as '性别' from employee;
select ismale '性别' from employee;
*- 匹配数据源中的所有列
select * from employee;
select *, 'abc' as 'extra' from employee;
case- case 结束必须加上
end - end 后面可以加上当前列的别名
- case 结束必须加上
select id, `name`,
-- case ismale when 1 then '男' else '女' end sex,
case when ismale = 1 then '男' else '女' end sex,
salary
from employee;
select id, `name`,
case when ismale = 1 then '男' else '女' end sex,
case when salary >= 10000 then '高'
when salary >= 5000 then '中'
else '低' end `level`,
salary
from employee;
distinct- 去重
- 一般只查一列
- distinct 必须写在选择列最前面
- 作用域 from 前面所有选择列
select distinct `location` from employee;
-- 结果表会去掉 location和id 组合起来后重复的数据,所以单独的一列数据还是会重复
select distinct `location`, id from employee;
2)from
- 单表查询时,from 后面的表是 原始表/物理表,即数据库中创建的表,存储在硬盘中
- 执行 select 语句时,将原始表的数据逐行读取到内存中,再筛选出 from 前的列,形成 结果表,存储在内存中
select id, loginid, loginpwd, 'abc' from user;
select id, loginid, loginpwd, 'abc' as '额外的一列' from user;
3)where
=inisis not>、<、>=、<=betweenlike%表示可以匹配多个_表示只匹配一个
andor
select * from employee where ismale = 1;
select * from department where companyId in (1, 2);
select * from employee where `location` is not null;
select * from employee where salary >= 10000;
select * from employee where salary between 10000 and 12000;
select * from employee where `name` like '%袁%'; -- X袁X
select * from employee where `name` like '袁%'; -- 袁XX
select * from employee where `name` like '袁_'; -- 袁X
select * from employee where `name` like '张%'
and ismale = 0 and salary >= 12000;
-- 姓张且工资过12k 或者 出生日期在1996之后
select * from employee where `name` like '张%'
and ismale = 0 and salary >= 12000
or birthday >= '1996-1-1';
-- 姓张且工资过12k 或者 姓张且出生日期在1996之后
select * from employee where `name` like '张%'
and ismale = 0
and (salary >= 12000 or birthday >= '1996-1-1');
4)order by
asc- ascending,升序
desc- descending,降序
select * from employee where `name` like '张%'
and ismale = 0
and (salary >= 12000 or birthday >= '1996-1-1')
order by salary asc;
select *,
case ismale when 1 then '男' else '女' end sex
from employee
order by sex asc, salary desc;
5)limit
n, m- 跳过 n 条数据,取出 m 条数据
-- 取出第3-5条数据
select * from employee limit 2,3;
6)练习
- 查询 user 表,得到账号为 admin,密码为 123456 的用户
select * from user where loginid = 'admin' and loginpwd = '123456';
- 查询员工表,按照员工的入职时间降序排序,并且使用分页查询
- 查询第 3 页,每页 5 条数据
limit (page - 1) * pagesize, pagesize
select * from employee
order by joinDate desc
limit 10,5;
- 查询工资最高的女员工
select * from employee
where ismale = 0
order by salary desc
limit 0,1;
6.联表查询
1)笛卡尔积
- 多张表相乘
select * from user, company;
select t1.name 主场, t2.name 客场 from team as t1, team as t2
where t1.id != t2.id;
2)左连接
- 又叫左外连接,left join
- 依次取出 表 1 中的数据,依次比对 表 2 每一条数据是否满足 on 的条件
- 满足则将当前表 1 的数据行和当前表 2 的数据行拼接成结果集中新的一行
- 如果表 2 没有对应数据,表 1 的数据需要单独形成一行,结果集的表 2 区域全为 null
- 左表的记录必须出现一次
select * from department as d
left join employee as e
on d.id = e.deptId;
3)右连接
- 又叫右外连接,right join
- 依次取出 表 2 中的数据,依次比对 表 1 每一条数据是否满足 on 的条件
- 满足则将当前表 1 的数据行和当前表 2 的数据行拼接成结果集中新的一行
- 如果表 1 没有对应数据,表 2 的数据需要单独形成一行,结果集的表 1 区域全为 null
- 右表的记录必须出现一次
select * from employee as e
right join department as d
on d.id = e.deptId;
4)内连接
- inner join
- 依次取出表 1 中的数据,依次比对表 2 每一条数据是否满足 on 的条件
- 满足则将当前表 1 的数据行和当前表 2 的数据行拼接成结果集中新的一行
- 如果表 1 没有对应数据,则不出现在结果集中
- 条件必须满足才出现
select * from department as d
inner join employee as e
on d.id = e.deptId;
select e.name as empname, d.name as dptname, c.name as comname
from department as d
inner join employee as e on d.id = e.deptId
inner join company as c on d.companyId = c.id;
5)练习
- 显示出所有员工的姓名、性别(使用男或女显示)、入职时间、薪水、所属部门(显示部门名称)、所属公司(显示公司名称)
select e.name 员工姓名,
case when e.ismale = 1 then '男' else '女' end 性别,
e.joinDate 入职时间,
e.salary 薪水,
d.name 所属部门,
c.name 所属公司
from employee e
inner join department d on e.deptId = d.id
inner join company c on d.companyId = c.id;
- 查询腾讯和蚂蚁金服的所有员工姓名、性别、入职时间、部门名、公司名
select e.name 员工姓名,
case when e.ismale = 1 then '男' else '女' end 性别,
e.joinDate 入职时间,
d.name 部门名,
c.name 公司名
from employee e
inner join department d on e.deptId = d.id
inner join company c on d.companyId = c.id
where c.name in ('腾讯科技', '蚂蚁金服');
- 查询渡一教学部的所有员工姓名、性别、入职时间、部门名、公司名
select e.name 员工姓名,
case when e.ismale = 1 then '男' else '女' end 性别,
e.joinDate 入职时间,
d.name 部门名,
c.name 公司名
from employee e
inner join department d on e.deptId = d.id
inner join company c on d.companyId = c.id
where c.name like '%渡一%' and d.name = '教学部';
7.函数和分组
1)内置函数
- 数学函数
| 函数名 | 说明 |
|---|---|
ABS(x) | 返回 x 的绝对值 |
CEIL(x) CEILING(x) | 返回大于 x 的最小整数值【向上取整】 |
FLOOR(X) | 返回小于 x 的最大整数值【向下取整】 |
MOD(x, y) | 返回 x/y 的模(余数) |
PI() | 返回 pi 的值(圆周率) |
RAND() | 返回 0 到 1 内的随机值 |
ROUND(x, y) | 返回参数 x 的 四舍五入 后有 y 位小数的值 |
TRUNCATE(x, y) | 返回数字 x 截断 为 y 位小数的结果 |
select abs(-1);
select ceil(1.4);
select round(3.1415926, 3);
select truncate(3.1415926,3);
select truncate(salary,0) from employee;
- 聚合函数
- 只能查出一列
- 但是可以查询多个聚合函数
| 函数名 | 说明 |
|---|---|
AVG(col) | 返回指定列的平均值 |
COUNT(col) | 返回指定列中 非 NULL 值 的个数 |
MIN(col) | 返回指定列的最小值 |
MAX(col) | 返回指定列的最大值 |
SUM(col) | 返回指定列的所有值之和 |
select avg(salary) as avg from employee;
-- 报错
-- select avg(salary), id as avg from employee;
-- 查出所有有id的员工的数量,即员工数量
select count(id) from employee;
-- 先查出所有员工,每一行中只要有一列非null就加入结果集,最后返回结果集总数量
-- 由于id是主键,一定非null,所以 count(*) 和 count(id) 效果一致
-- 尽量别用 count(*) ,需要比对全部列,消耗性能且占用内存
select count(*) from employee;
select count(id) as 员工数量,
avg(salary) as 平均薪资,
sum(salary) as 总薪资,
min(salary) as 最低薪资
from employee;
- 字符函数
| 函数名 | 说明 |
|---|---|
CONCAT(s1, s2, ..., sn) | 将 s1, s2, ..., sn 连接成字符串 |
CONCAT_WS(sep, s1, s2, ..., sn) | 将 s1, s2, ..., sn 连接成字符串,并用 sep 字符作间隔 |
TRIM(str) | 去除字符串首部和尾部的所有空格 |
LTRIM(str) | 从字符串 str 中去除首部的空格 |
RTRIM(str) | 从字符串 str 中去除尾部的空格 |
select concat(name, salary) from employee;
select concat_ws('@', name, salary) from employee;
- 日期函数
| 函数名 | 说明 |
|---|---|
CURDATE() 或 CURRENT_DATE() | 返回当前的日期 |
CURTIME() 或 CURRENT_TIME() | 返回当前的时间 |
TIMESTAMPDIFF(part, date1, date2) | 返回 date1 到 date2 之间相隔的 part 值 part 用于指定的相隔的年或月或日等 part 取值:microsecond、second、minute、hour、day、week、month、quarter、year 一般用于计算年龄 |
select curdate();
select curtime();
select timestampdiff(hour, '2010-1-1 11:11:11', '2010-1-2 11:11:11');
-- 计算年龄
select *,
timestampdiff(year, birthday, curdate()) as age
from employee order by age;
2)自定义函数
3)分组
- 适用于复杂查询
- 运行顺序
from=>join...on...=>where=>group by=>select=>having=>order by=>limit
- 分组后只能查询分组的列和聚合列
- 分组后筛选只能使用 having
-- 查询员工分布的居住地,以及每个居住地有多少名员工,如:天府三街 3
select location, count(id) empnum
from employee group by location;
select location, count(id) empnum
from employee
group by location
having empnum >= 40;
-- 查询所有薪水在10000以上的员工分布的居住地,仅得到员工数量大于30的结果
select location, count(id) empnum
from employee
where salary >= 10000
group by location
having count(id) >= 30;
4)练习
- 查询渡一每个部门的员工数量
select d.name dname, count(e.id) enum
from employee e
inner join department d on d.id = e.deptId
inner join company c on c.id = d.companyId
where c.name like '%渡一%'
group by d.id, d.name;
- 查询每个公司的员工数量
select c.name cname, count(e.id) enum
from employee e
inner join department d on d.id = e.deptId
inner join company c on c.id = d.companyId
group by c.id, c.name;
- 查询所有公司 15 年内入职的居住在万家湾的女员工数量
-- 错误
-- select c.name cname, count(e.id) enum,
-- timestampdiff(year, e.joinDate, CURDATE()) as 入职年限
-- from employee e
-- inner join department d on d.id = e.deptId
-- inner join company c on c.id = d.companyId
-- where e.ismale = 0 and e.location like '%万家湾%'
-- group by c.name
-- having 入职年限 <= 15;
select c.name,
case when r.enum is null then 0 else r.enum end number
from company c left join (
select c.id, c.name, count(e.id) enum
from employee e
inner join department d on d.id = e.deptId
inner join company c on c.id = d.companyId
where e.ismale = 0 and e.location like '%万家湾%'
and timestampdiff(year, e.joinDate, CURDATE()) <= 15
group by c.id, c.name
) as r
on c.id = r.id;
- 查询渡一所有员工分布在哪些居住地,每个居住地的数量
select e.location location, count(e.id) enum
from employee e
inner join department d on d.id = e.deptId
inner join company c on c.id = d.companyId
where c.name like '%渡一%'
group by e.location;
- 查询员工人数大于 200 的公司信息
-- group by 最好只查一列
-- select c.*, count(e.id) enum
-- from employee e
-- inner join department d on d.id = e.deptId
-- inner join company c on c.id = d.companyId
-- group by c.id
-- having enum > 200;
select * from company
where id in (
select c.id
from company as c inner join department as d on c.id = d.companyid
inner join employee as e on d.id = e.deptid
group by c.id, c.`name`
having count(e.id) >= 200
);
- 查询渡一公司里比它平均工资高的员工
select e.*
from employee e
inner join department d on d.id = e.deptId
inner join company c on c.id = d.companyId
where c.name like '%渡一%'
and e.salary >= (
select avg(e.salary) from employee e
inner join department d on d.id = e.deptId
inner join company c on c.id = d.companyId
where c.name like '%渡一%'
);
- 查询渡一所有名字为两个字和三个字的员工对应人数
select char_length(e.name) nameLength, count(e.id) enum
from employee e
inner join department d on d.id = e.deptId
inner join company c on c.id = d.companyId
where c.name like '%渡一%'
group by nameLength
having nameLength in (2, 3);
- 查询每个公司每个月的总支出薪水,并按照从低到高排序
select c.name cname, sum(e.salary) totalSalary
from employee e
inner join department d on d.id = e.deptId
inner join company c on c.id = d.companyId
group by c.id, c.name
order by totalSalary asc;
8.视图
- 操作视图属于 DDL
- 数据存储在内存中
- 可以简化 SQL 查询
- 可以减少网络传输
- Node 程序中需要向 MySQL 数据库传输 SQL 语句
- 越简单的语句传输越快,传输的数据量越少
1)创建视图
create view 视图名 as 查询语句;
create view empinfo as select c.name cname, sum(e.salary) totalSalary
from employee e
inner join department d on d.id = e.deptId
inner join company c on c.id = d.companyId
group by c.id, c.name
order by totalSalary asc;
2)查询视图
select * from empinfo where cname like '%渡一%';
(三)数据驱动和 ORM
1.MySQL 驱动程序
1)驱动程序
- 是连接内存和其他存储介质的桥梁
- MySQL 驱动程序是连接内存数据和 MySQL 数据的桥梁
- MySQL 为不同编程语言提供了不同的驱动程序包
- MySQL
- 官方驱动
- MySQL2
- 第三方驱动
- 前身为 MySQL-Native
- 优化好,运行效率较高,推荐
- 接口基本一致
- MySQL
2)使用 MySQL2 createConnection
npm install --save mysql2
- 回调模式 CRUD
const mysql = require("mysql2");
// 创建一个数据库连接
const connection = mysql.createConnection({
host: "localhost",
user: "root",
password: "123123",
database: "companydb",
});
// 查询
connection.query("select * from company;", function (err, results) {
// err 错误
// result 查询结果
console.log(results); // results contains rows returned by server
});
// 新增
connection.query("insert into company(name, location, buildDate) values('abc', '阿萨德', curdate());", (err, res) => {
console.log(err, res);
});
// 修改
connection.query("update company set name = 'bcd' where id = 4", (err, res) => {
console.log(err, res);
});
// 删除
connection.query("delete from company where id = 4", (err, res) => {
console.log(err, res);
});
// 断开连接
connection.end();
- 异步模式 CRUD
const mysql = require("mysql2/promise");
const test = async () => {
const connection = await mysql.createConnection({
host: "localhost",
user: "root",
password: "123123.",
database: "companydb",
});
const [results] = await connection.query("select * from company where id = 5;");
console.log(results);
connection.end();
};
test(5);
3)防止 SQL 注入
- 用户通过注入 SQL 语句到最终查询中,导致整个 SQL 与预期行为不符
const mysql = require("mysql2/promise");
const test = async (id) => {
const connection = await mysql.createConnection({
host: "localhost",
user: "root",
password: "123123.",
database: "companydb",
multipleStatements: true, // 允许运行多条SQL语句,默认false
});
// SQL 不能直接用字符串书写,否则有 SQL 注入的风险
const [results] = await connection.query(`select * from company where id = ${id};`);
console.log(results);
connection.end();
};
test(`''; delete from company where id = 5`);
4)解决 SQL 注入隐患 execute
- MySQL 支持变量
- 变量的内容不作为任何 SQL 关键字
- 形成的语句称为预编译的 SQL 语句
- sql 语句待填充的位置要用
?占位 - 不直接使用 query 运行,先使用 execute 预编译
- 参数传入 sql 模板,数组为模板中所有
?待填充的数据 - 模糊查询需要使用
concat('%', ?, '%') - 驱动程序内部使用变量的模式将数据填充进 sql 语句中
- 参数传入 sql 模板,数组为模板中所有
const mysql = require("mysql2/promise");
const test = async (id) => {
const connection = await mysql.createConnection({
host: "localhost",
user: "root",
password: "123123.",
database: "companydb",
multipleStatements: true, // 允许运行多条SQL语句,默认false
});
// SQL 不能直接用字符串书写,否则有 SQL 注入的风险
const sql = `select * from company where id = ?;`;
const [results] = await connection.execute(sql, [id]);
console.log(results);
connection.end();
};
test(`''; delete from company where id = 5`);
5)使用连接池 createPool
- Node 程序和 MySQL 数据库需要建立多条连接
- 一个请求建立一条连接
- 如果没有及时释放连接,会占用大量服务器资源
- 同时过多的连接会导致服务器卡顿
- 最优雅的实现方式是创建连接池(数组)
- 保存了所有的连接对象
- 连接池中连接达到阈值后,新来的请求都需要等待
- 避免服务器资源占用
const mysql = require("mysql2/promise");
const pool = mysql.createPool({
host: "localhost",
user: "root",
password: "123123",
database: "companydb",
multipleStatements: true,
});
const test = async (id) => {
// 创建一个数据库连接
const sql = `select * from employee where \`name\` like concat('%', ?, '%');`;
const [results] = await pool.execute(sql, [id]);
console.log(results);
};
test("袁");
2.Sequelize 简介
1)ORM 框架
- Object Relational Mapping 对象关系映射
- 不同的后端编程语言都有不同的 ORM 框架
- 通过 ORM 框架,可以自动地把程序中的对象和数据库关联
- ORM 框架会隐藏具体的数据库底层细节,让开发者使用同样的数据操作接口,完成对不同数据库的操作
- 优势
- 开发者无需关注数据库,仅需关心对象
- 可轻易地完成数据库的移植
- 无需拼接复杂的 SQL 语句,即可完成精确查询
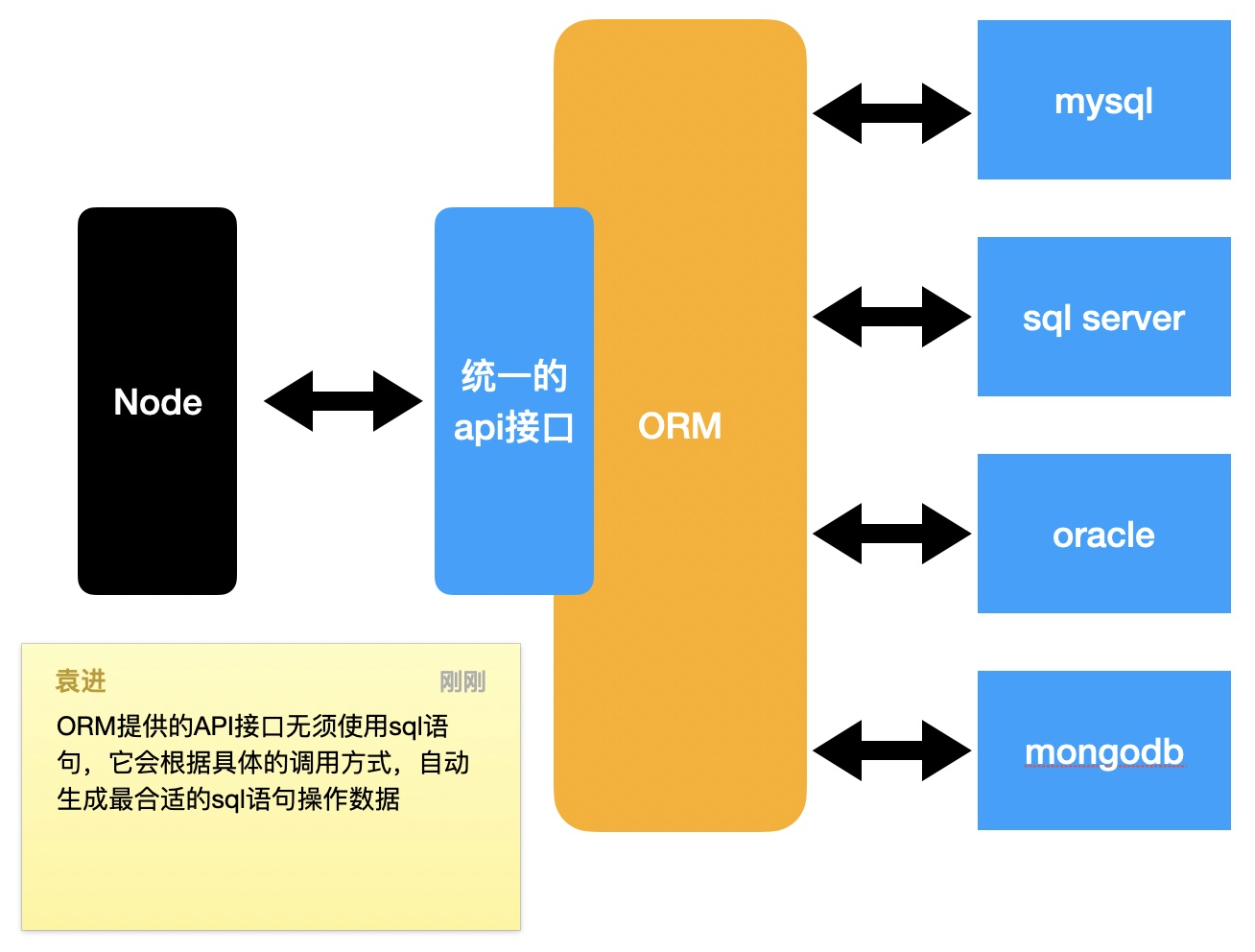
2)Node 中的 ORM
- Sequelize
- 支持 JS、TS
- 成熟
- TypeORM
- 只支持 TS
- 不成熟
3.模型定义和同步
- 案例:学校数据库
- 四张表(四个模型)
- 管理员:id、账号、密码、姓名
- 班级:id、名称、开班时间
- 学生:id、姓名、出生日期、性别、联系电话、所属班级
- 书籍:id、名称、图片、出版时间、作者
1)安装 Sequelize
npm i sequelize mysql2
"dependencies": {
"mysql2": "^2.1.0",
"sequelize": "^5.21.5"
}
2)连接到数据库
- models 文件夹,存放各种模型
- 可以简单地理解为一张数据表对应一个模型
- 模型本质是一个 JS 对象
- 创建并导出 ORM 实例
- 一个系统使用一个 ORM 实例即可
- 内部创建了连接池
// models/db.js
const { Sequelize } = require("sequelize");
const sequelize = new Sequelize("myschooldb", "root", "123123", {
host: "localhost",
dialect: "mysql", // 数据库类型
logging: null, // 隐藏数据库操作日志
});
module.exports = sequelize;
- 测试连接
// index.js
const sequelize = require("./models/db");
(async () => {
try {
await sequelize.authenticate();
console.log("Connection has been established successfully.");
} catch (error) {
console.error("Unable to connect to the database:", error);
}
})();
3)定义模型
- 主键列不需要定义,会自动生成
- define 函数的参数 1 是模型名,默认会对应生成数据表名
${模型名}s- 如:Admin -> Admins
- 如果不希望该默认,可以传入第三个参数配置对象
- 配置
freezeTableName: true - 或者直接指定表名
tableName: "administrator"
- 配置
模型命名
规范是首字母大写,看作类
// models/Admin.js
const sequelize = require("./db");
const { DataTypes } = require("sequelize");
// 创建一个模型对象
const Admin = sequelize.define(
"Admin",
{
loginId: {
type: DataTypes.STRING,
allowNull: false,
},
loginPwd: {
type: DataTypes.STRING,
allowNull: false,
},
},
{
// freezeTableName: true,
// tableName: 'administrator',
createdAt: false,
updatedAt: false,
paranoid: true, // 配置后,该表的数据不会真正的删除,而是增加一列deletedAt,记录删除的时间
},
);
// // 将模型同步到数据库中,生成数据表
// (async () => {
// await Admin.sync({
// alter: true,
// });
// })();
module.exports = Admin;
4)定义模型间的关系
// models/relation.js
const Class = require("./Class");
const Student = require("./Student");
Class.hasMany(Student);
Student.belongsTo(Class);
5)同步所有模型
// models/sync.js
require("./Admin");
require("./Book");
require("./Class");
require("./Student");
const sequelize = require("./db");
sequelize
.sync({
alter: true,
})
.then(() => {
console.log("所有模型同步完成");
});
4.模型的增删改
1)三层架构
- 搭建后端工程的基本框架
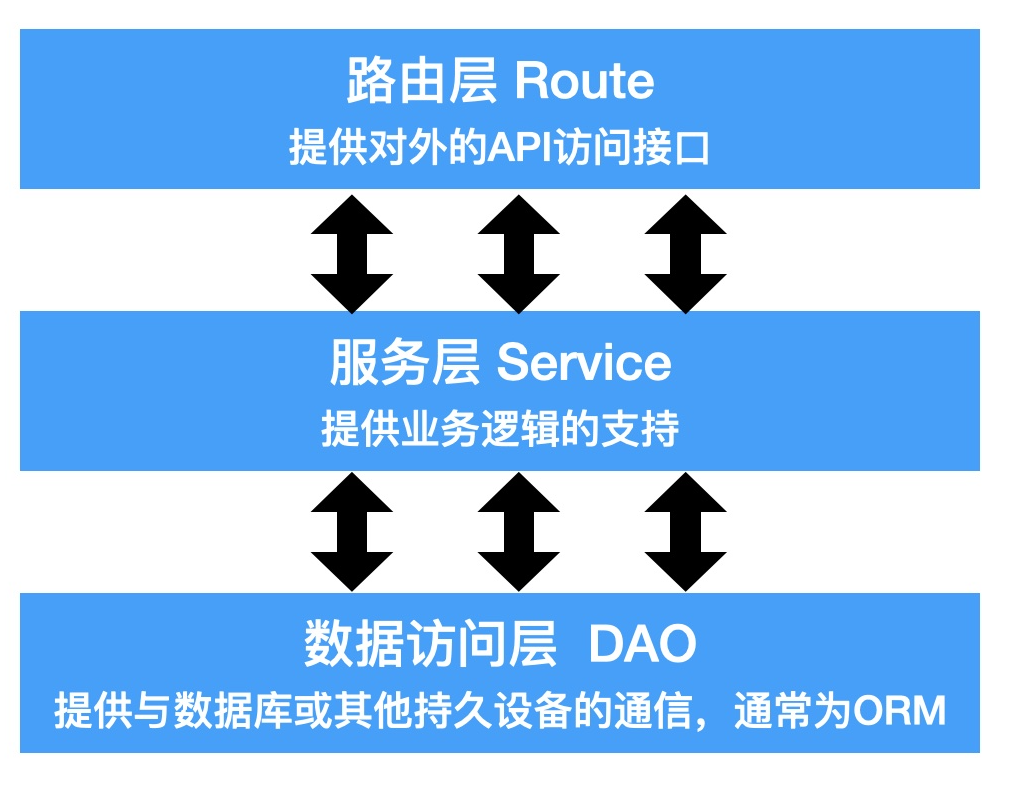
- 路由层
- 原来叫 UI 层,又叫服务层/API 层
- 服务层
- 又叫业务逻辑层
- 数据访问层
- Java 中为 DAO,Data Access Object
- C#中为 DAL,Data Access Layer
- 一般这一层都使用 ORM 框架
- Node 中三层架构对应的文件夹
- 路由层 —— routes
- 服务层 —— services
- 数据访问层 —— models
2)增加
// services/adminService.js
exports.addAdmin = async function (adminObj) {
/**
* TODO
* 应该判断adminObj的各种属性是否合理,以及帐号是否已存在
* 传入operatorId当前操作用户id,判断是否是管理员
*/
// 方式1
// // 同步方法,构建一个模型实例
// const ins = Admin.build({
// loginId: "abc",
// loginPwd: "123",
// });
// ins.loginId = "bcd";
// // 异步方法,同步到数据库
// ins.save().then(() => {
// console.log("新建管理员成功");
// });
// 方式2
const ins = await Admin.create(adminObj);
// 将实例对象扁平化
return ins.toJSON();
};
3)删除
// services/adminService.js
exports.deleteAdmin = async function (adminId) {
// 方式1:有实例可以直接删除,没有实例则执行了两条语句
// // 1.得到实例
// const ins = await Admin.findByPk(adminId);
// // 2.删除数据
// ins && await ins.destroy();
// 方式2:不需要实例,只执行一条语句
return await Admin.destroy({
where: {
id: adminId,
},
});
};
4)修改
exports.updateAdmin = async function (id, adminObj) {
// 方式1:有实例可以直接修改,没有实例则执行了两条语句
// // 1.得到实例
// const ins = await Admin.findByPk(id);
// // 2.修改数据
// ins.loginId = adminObj.loginId;
// // 3.保存
// ins.save();
// 方式2:不需要实例,只执行一条语句
return await Admin.update(adminObj, {
where: {
id,
},
});
};
5.模拟数据
- mock/mockClass.js
const Mock = require("mockjs");
const result = Mock.mock({
"datas|16": [
{
"id|+1": 1,
name: "前端第 @id 期",
openDate: "@date",
},
],
}).datas;
const Class = require("../models/Class");
Class.bulkCreate(result);
- mock/mockStudent.js
const Mock = require("mockjs");
const result = Mock.mock({
"datas|500-700": [
{
name: "@cname",
birthday: "@date",
"sex|1-2": true,
mobile: /1\d{10}/,
// location: "@city(true)",
"ClassId|1-16": 0,
},
],
}).datas;
const Student = require("../models/Student");
Student.bulkCreate(result);
6.数据抓取
1)抓取豆瓣读书中的书籍信息
2)涉及的库
// spider/fetchBook.js
const axios = require("axios").default;
const cheerio = require("cheerio");
const Book = require("../models/Book");
/**
* 获取豆瓣读书网页的源代码
*/
const getBooksHTML = async () => {
const res = await axios.get("https://book.douban.com/latest");
return res.data;
};
/**
* 从豆瓣读书中得到一个完整的网页,并从网页中分析出书籍的基本信息
* 获得书籍的详情页链接数组
*/
const getBooksLinks = async () => {
const booksHTML = await getBooksHTML();
// 获得cheerio操作对象
const $ = cheerio.load(booksHTML);
// 获得新书速递首页40本书籍的封面a元素
const linkElements = $(".chart-dashed-list .media .media__img a");
// 遍历a元素数组,取出所有详情页链接
const links = linkElements.map((_, link) => link.attribs["href"]).get();
return links;
};
/**
* 根据书籍详情页的地址,获得该书籍的详细信息
* @param {String} detailUrl 详情页链接
*/
const getBookDetail = async (detailUrl) => {
// 获得详情页的网页源代码和cheerio操作对象
const res = await axios.get(detailUrl);
const $ = cheerio.load(res.data);
// 获取书籍名称
const name = $("h1 span").text();
// 获取书籍封面图片链接
const imgUrl = $("#content .article #mainpic .nbg img").attr("src");
// 获取书籍作者
const spanElements = $("#content .article #info span.pl");
const authorElement = spanElements.filter((_, el) => $(el).text().includes("作者"));
const author = authorElement.next("a").text();
// 获取书籍出版年
const publishElement = spanElements.filter((_, el) => $(el).text().includes("出版年"));
const publishDate = publishElement[0].nextSibling.nodeValue.trim();
return {
name,
imgUrl,
author,
publishDate,
};
};
/**
* 获得所有的书籍信息
*/
const getBooksInfo = async () => {
const booksLinks = await getBooksLinks();
const promises = booksLinks.map((link) => getBookDetail(link));
return Promise.all(promises);
};
/**
* 获得书籍信息,然后保存到数据库
*/
const setBooksInfoToDB = async () => {
const booksInfo = await getBooksInfo();
await Book.bulkCreate(booksInfo);
console.log("书籍信息爬取成功,已保存到数据库");
};
(async () => {
await setBooksInfoToDB();
})();
7.数据查询
| 常用 API | 说明 |
|---|---|
findOne | 查询单条数据 |
findByPK | 根据主键查询单条数据 |
findAll | 查询多条数据 |
count | 查询数量 |
include | 查询包含关系 |
const { Op } = require("sequelize");
exports.getStudentById = async function (id) {
const result = await Student.findByPk(id);
if (result) {
return result.toJSON();
}
return null;
};
exports.getStudents = async function (page = 1, limit = 10, sex = -1, name = "") {
const where = {};
if (sex !== -1) {
where.sex = !!sex;
}
if (name) {
where.name = {
[Op.like]: `%${name}%`,
};
}
const result = await Student.findAndCountAll({
attributes: ["id", "name", "sex", "birthday"],
where,
include: [Class],
offset: (page - 1) * limit,
limit: +limit,
});
return {
total: result.count,
datas: JSON.parse(JSON.stringify(result.rows)),
};
};
8.MD5 加密
- hash 加密算法的一种
- 可以将任何一个字符串加密成一个固定长度的字符串
- 单向加密:只能加密无法解密
- 同样的源字符串加密后得到的结果固定
const md5 = require("md5");
exports.addAdmin = async function (adminObj) {
adminObj.loginPwd = md5(adminObj.loginPwd);
const ins = await Admin.create(adminObj);
return ins.toJSON();
};
exports.updateAdmin = async function (id, adminObj) {
if (adminObj.loginPwd) {
adminObj.loginPwd = md5(adminObj.loginPwd);
}
return await Admin.update(adminObj, {
where: {
id,
},
});
};
exports.login = async function (loginId, loginPwd) {
loginPwd = md5(loginPwd);
const result = await Admin.findOne({
where: {
loginId,
loginPwd,
},
});
if (result && result.loginId === loginId && result.loginPwd === loginPwd) {
return result.toJSON();
}
return null;
};
9.moment
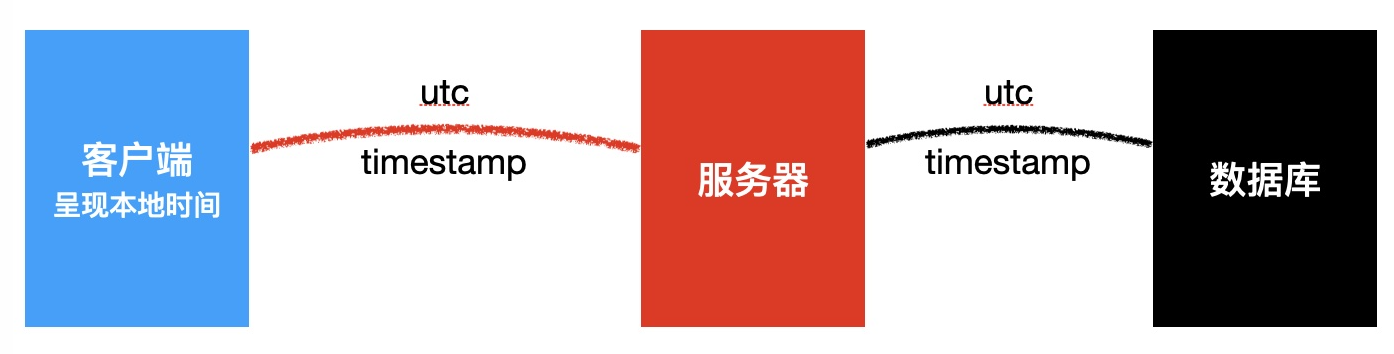
1)UTC 和北京时间
- 世界协调时
- 以英国格林威治时间为标准
- UTC 时间和北京时间相差 8 小时
- UTC 的凌晨相当于北京时间的上午 8 时
2)时间戳 timestamp
- 某个 UTC 时间到 UTC1970-1-1 凌晨经过的毫秒数
- 也可以是秒数,用小数部分记录毫秒
- 时间戳表示的是 UTC 时间的差异
北京时间:1970-1-1 08:00:00 => timestamp:0
UTC时间:1970-1-1 00:00:00 => timestamp:0
3)对于服务器的影响
- 服务器可能会部署到世界的任何位置
- 服务器内部应该统一使用 UTC 时间或时间戳,包括数据库
- Sequelize 默认生成的 createdAt 和 updatedAt 都使用 UTC 时间
4)对于客户端的影响
- 客户端要给不同地区的客户友好的时间显示
- 客户端应该把 UTC 时间或时间戳转换为本地时间
- 通常使用 moment 第三方库
10.数据验证
1)前后端三层验证
| 验证类型 | 目的 |
|---|---|
| 客户端(浏览器、APP、Pad、小程序等)验证 | 优化 用户体验,与安全无关 |
| 路由层 | 验证接口格式是否正常 |
| 服务器端逻辑验证(业务逻辑层的验证) | 保证 业务逻辑的完整性、安全性 |
| 数据库验证(约束) | 保证 数据完整性,非空约束、外键约束等,大系统才需要 |
完整性
- 一个完整的系统,最重要的验证一定在服务器端
- 完整性:业务方法随意使用时,数据一定是正确、合理的
2)相关库
- Validator
- 用于验证某个字符串是否满足某个规则
- Validate.js
- 用于验证某个对象的属性是否满足某些规则
3)自动转换格式
// service/init.js
const validate = require("validate.js");
const moment = require("moment");
validate.extend(validate.validators.datetime, {
/**
* 该函数会自动用于日期格式转换
* 它会在验证时自动触发,它需要将任何数据转换为时间戳返回
* 如果无法转换,返回NaN
* @param {*} value 传入要转换的值
* @param {*} options 针对某个属性的验证配置
*/
parse(value, options) {
let formats = ["YYYY-MM-DD HH:mm:ss", "YYYY-M-D H:m:s", "x"];
if (options.dateOnly) {
formats = ["YYYY-MM-DD", "YYYY-M-D", "x"];
}
return +moment.utc(value, formats, true);
},
/**
* 用户显示错误消息时,使用的显示字符串
* @param {timestamp} value 经过parse后传入的时间戳
*/
format(value, options) {
let format = "YYYY-MM-DD";
if (!options.dateOnly) {
format += " HH:mm:ss";
}
return moment.utc(value).format(format);
},
});
4)创建工具库
- 只保留希望添加到数据库中的属性
// utils/propertyHelper.js
exports.pick = function (obj, ...props) {
if (!obj || typeof obj !== "object") {
return obj;
}
const newObj = {};
for (const key in obj) {
if (props.includes(key)) {
newObj[key] = obj[key];
}
}
return newObj;
};
5)添加学生时增加数据验证
// services/studentService.js
const validate = require("validate.js");
const moment = require("moment");
const { pick } = require("../util/propertyHelper");
exports.addStudent = async function (obj) {
stuObj = pick(stuObj, "name", "birthday", "sex", "mobile", "ClassId");
console.log(stuObj);
validate.validators.classExits = async function (value) {
const c = await Class.findByPk(value);
if (c) {
return;
}
return "is not exist";
};
const rule = {
//验证规则
name: {
presence: {
allowEmpty: false,
},
type: "string",
length: {
minimum: 1,
maximum: 10,
},
},
birthday: {
presence: {
allowEmpty: false,
},
datetime: {
dateOnly: true,
earliest: +moment.utc().subtract(100, "y"),
latest: +moment.utc().subtract(5, "y"),
},
},
sex: {
presence: true,
type: "boolean",
},
mobile: {
presence: {
allowEmpty: false,
},
format: /1\d{10}/,
},
ClassId: {
presence: true,
numericality: {
onlyInteger: true,
strict: false,
},
classExits: true,
},
};
await validate.async(stuObj, rule);
const ins = await Student.create(obj);
return ins.toJSON();
};
11.访问器和虚拟字段
1)访问器
- 不改变数据库的存储格式,但是获取字段时能获得相应格式的属性值
2)虚拟字段
- 类似 Vue 中的 computed,不存在于数据库中,仅用于获取
// models/Student.js
const Student = sequelize.define(
"Student",
{
name: {
type: DataTypes.STRING,
allowNull: false,
},
birthday: {
type: DataTypes.DATE,
allowNull: false,
get() {
const birth = this.getDataValue("birthday");
if (birth) return birth.getTime();
return undefined;
},
},
age: {
type: DataTypes.VIRTUAL, // 虚拟字段
get() {
const now = moment.utc();
const birth = moment.utc(this.birthday);
return now.diff(birth, "y"); // 获得两个日期的年份差
},
},
sex: {
type: DataTypes.BOOLEAN,
allowNull: false,
},
mobile: {
type: DataTypes.STRING(11),
allowNull: false,
},
},
{
createdAt: false,
updatedAt: false,
paranoid: true,
},
);
12.日志记录
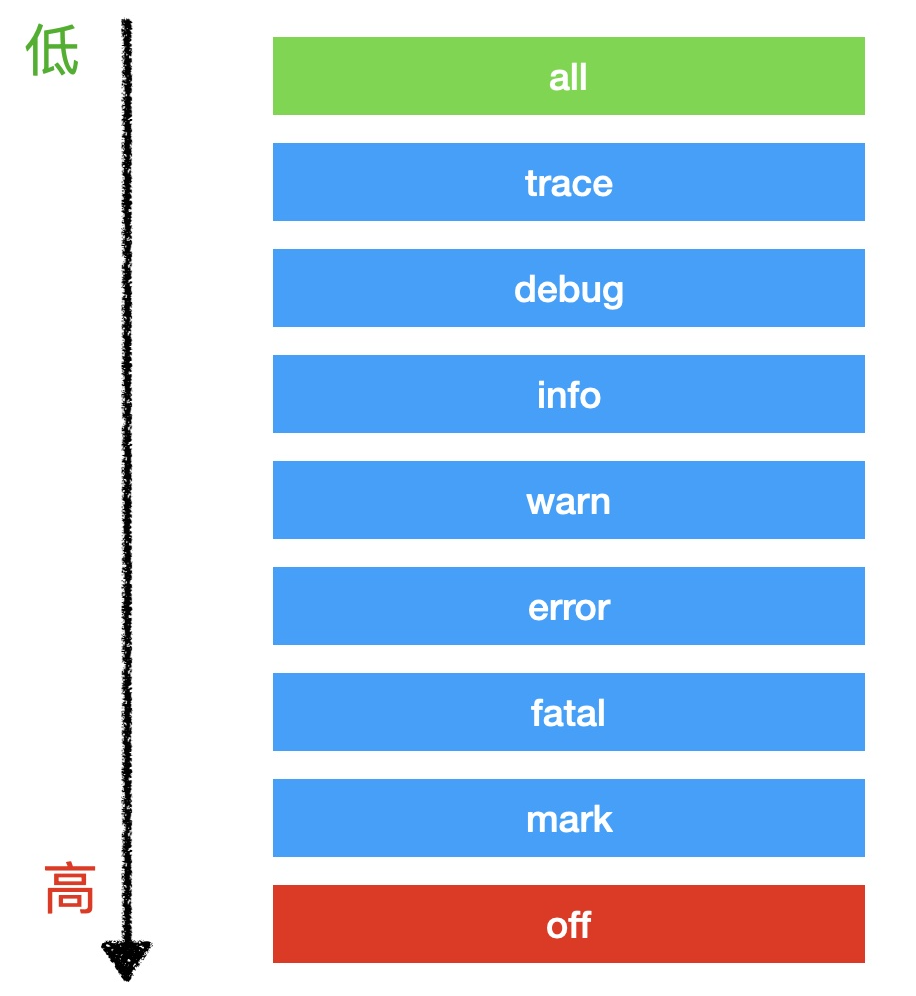
1)日志级别 level
- 如:调试日志、信息日志、错误日志等
2)日志分类 category
- 如:SQL 日志、请求日志等
3)日志出口 appender
- 应该把日志写到哪里
- 日志的书写格式是什么(layouts)
4)日志配置
// logger.js
const log4js = require("log4js");
const path = require("path");
log4js.configure({
appenders: {
sql: {
// 定义一个sql日志出口
type: "dateFile",
filename: path.resolve(__dirname, "logs", "sql", "logging.log"),
maxLogSize: 1024 * 1024, // 配置文件的最大字节数
keepFileExt: true,
layout: {
type: "pattern",
pattern: "%c [%d{yyyy-MM-dd hh:mm:ss}] [%p]: %m%n",
},
},
default: {
type: "stdout",
},
},
categories: {
/**
* 分类1
* 名称:sql(表示使用名为sql的出口)
* 出口:(异步写入日志)
* 出口名称:sql
* 类别级别:需要记录的日志等级
*/
sql: {
appenders: ["sql"], // 该分类使用出口sql的配置写入日志
level: "all",
},
default: {
appenders: ["default"],
level: "all",
},
},
});
// 程序正/异常退出时,还没记录完成的日志记录完
process.on("exit", () => {
log4js.shutdown();
});
const sqlLogger = log4js.getLogger("sql");
const defaultLogger = log4js.getLogger();
exports.sqlLogger = sqlLogger; // 数据库自定义日志
exports.logger = defaultLogger; // 控制台默认日志
5)sequelize 实例配置 logger
// models/db.js
const { Sequelize } = require("sequelize");
const { sqlLogger } = require("../logger");
const sequelize = new Sequelize("myschooldb", "root", "123123", {
host: "localhost",
dialect: "mysql", // 数据库类型
// logging: null, // 隐藏数据库操作日志
logging: (msg) => {
sqlLogger.debug(msg);
},
});
module.exports = sequelize;
(四)Express
- http 模块存在的问题
- 根据不同的请求路径、请求方法,完成不同操作,比较麻烦
- 读取请求体和写入响应体时,是通过流的方式实现的,比较麻烦
- 使用第三方库解决
- express
- 生态完整
- koa2
- 提供的 API 更友好
- express
1.Express 的基本使用
1)创建 express 对象
/**
* 方式1
*/
const express = require("express");
const http = require("http");
// 创建一个express应用
const app = express();
const port = 9527;
// app实际上是一个函数,用于处理请求
const server = http.createServer(app);
server.listen(port, () => {
console.log(`server listening on ${port}`);
});
/**
* 方式2
*/
const express = require("express");
// 创建一个express应用
const app = express();
const port = 9527;
// app实际上是一个函数,用于处理请求
app.listen(port, () => {
console.log(`server listening on ${port}`);
});
2)app 函数处理请求的原理
- 配置了一个请求映射
app.请求方法("请求路径", 处理函数)
- 如果请求方法和请求路径满足匹配,则执行处理函数
app.get("/abc", (req, res) => {
// req 和 res 是被 express 封装过的对象,无需直接操作流
console.log(req.headers);
});
// {
// 'user-agent': 'PostmanRuntime/7.33.0',
// accept: '*/*',
// 'postman-token': 'b5372547-066b-4fed-845b-5157909d7635',
// host: 'localhost:9527',
// 'accept-encoding': 'gzip, deflate, br',
// connection: 'keep-alive'
// }
3)获取请求信息
// 静态路由 -> localhost:9527/abc
app.get("/abc", (req, res) => {
// req 和 res 是被 express 封装过的对象,无需直接操作流
console.log("请求路径", req.path); // /abc
console.log("请求参数query", req.query); // { a: '1' }
});
// 动态路由 -> localhost:9527/news/123
app.get("/news/:id", (req, res) => {
console.log("动态参数params", req.params); // { id: '123' }
});
4)响应请求
- 调用了 send 则无需调用 end,内部自动调用
- 没有调用 send 要自己调用
- 响应头 content-type 自动对应不同的 send 参数
app.get("/abc", (req, res) => {
// 设置响应头
// res.setHeader("Content-Type", "application/json");
// 响应请求
// res.send("<h1>你好啊</h1>");
// res.send({
// a: 1,
// });
// 重定向
// res.status(302).header("location", "https://duyi.ke.qq.com").end();
// res.status(302).location("https://duyi.ke.qq.com").end();
res.redirect(302, "https://duyi.ke.qq.com");
});
5)REST 风格的 API 接口
- 规范化规定 API 接口路径和方法
- REST 风格:对同一个资源通过不同的方法完成不同的处理
| 请求地址 | 请求方法 | 接口功能 |
|---|---|---|
/api/student | post | 添加学生 |
/api/student/:id? | get | 获取学生 |
/api/student/:id | put | 修改学生 |
/api/student/:id | delete | 删除学生 |
6)匹配请求
// 匹配所有请求方法
app.all("", () => {});
// 匹配所有请求地址
app.get("*", () => {});
2.nodemon
- nodemon 是一个监视器
- 用于监控工程中的文件变化
- 如果发现文件有变化,可以执行一段脚本
- 通常用作开发依赖
- 当作 node 使用即可
- 首次运行后,改动了文件无需停止再重新运行
1)控制台启动服务
npx nodemon index
2)控制台查看帮助
npx nodemon -h
3)配置到 package.json
"scripts": {
"start": "nodemon -x npm run server",
"server": "node index"
},
npm start
4)指定配置文件
// ./nodemon.json
{
"env": {
"NODE_ENV": "development"
},
"watch": ["*.js", "*.json"],
"ignore": ["package*.json", "nodemon.json", "node_modules", "public"]
}
3.Express 中间件
- 其实就是 app 函数的处理函数
- 一个 app 映射对象可以匹配多个处理函数
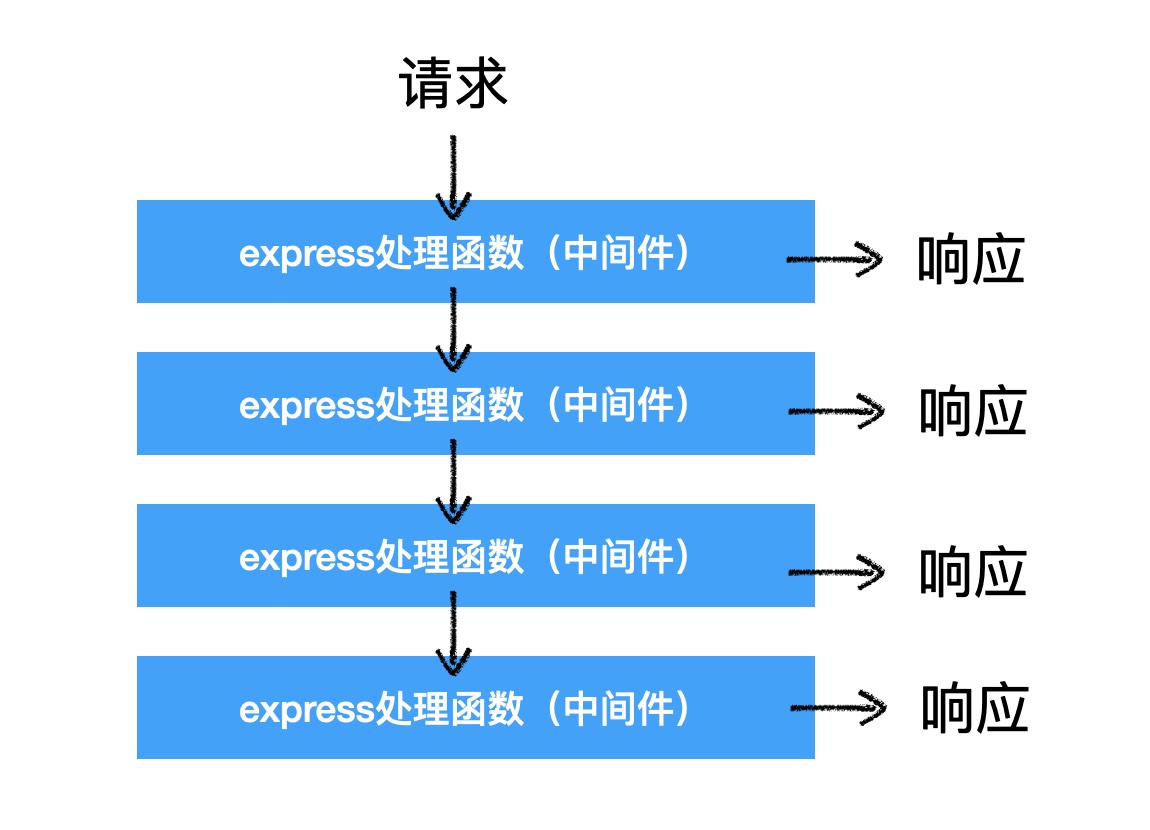
1)中间件的处理模式
- 匹配到请求后
- 交给第一个处理函数处理
- 第一个处理函数中,需要手动地移交给后续中间件处理
- 使用第三个参数
next - 可以在处理函数中任意位置调用 next
- 使用第三个参数
- 中间件通常写成单独的模块
- 所以任意中间件都可以移交
- 尽管后续没有其他中间件
- 当最后一个中间件调用 next 后
- express 会检查是否调用了 end
- 如果没有则判定响应没有结束,响应 404
- 前置中间件响应了请求(调用了 end)
- 后置中间件依旧需要处理
- 后置中间件再次响应请求,则会报错
app.get(
"/news",
(req, res, next) => {
console.log("handler1");
res.status(200);
res.end();
next();
},
(req, res, next) => {
console.log("handler2");
next();
},
);
app.get("/news", (req, res, next) => {
console.log("handler3");
next();
});
- 如果中间件处理过程中发生错误
- 服务器不会停止
- 不需要调用 next
- 相当于调用了
next(错误对象)
- express 会寻找后续的错误处理中间件
- 如果没有,则响应 500
app.get(
"/news/abc",
(req, res, next) => {
console.log("handler1");
// throw new Error("abc");
// // next();
// 相当于
next(new Error("abc"));
},
(err, req, res, next) => {
console.log("handler2");
res.send("服务器错误", err);
next();
},
);
2)自定义处理错误的中间件
// routes/errorMiddleware.js
module.exports = (err, req, res, next) => {
// 获取基地址(调用中间件的use函数的第一个参数)
console.log(req.baseUrl); // /news
if (err) {
const errObj = {
code: 500,
msg: err instanceof Error ? err.message : err,
};
// 发生了错误
res.status(500).send(errObj);
} else {
next();
}
};
3)使用处理错误中间件
// routes/init.js
/**
* 能匹配:
* /news
* /news/abc
* /news/123
* /news/ab/adfs
* 不能匹配:
* /n
* /a
* /
* /newsabc
*/
app.use("/news", require("./errorMiddleware"));
// 匹配任何请求
app.use(require("./errorMiddleware"));
4)自定义处理静态资源的中间件
// routes/staticMiddleware.js
module.exports = (req, res, next) => {
if (req.path.startsWith("/api")) {
// 说明请求的是 API 接口
next();
} else {
// 说明需要的是静态资源
if (true) {
// 静态资源存在
res.send("静态资源");
} else {
next();
}
}
};
5)使用处理静态资源中间件
// routes/init.js
app.use(require("./staticMiddleware"));
4.常用中间件
提示
通常极少自定义中间件,较多使用 express 自带中间件
1)express.static()
- 搭建静态服务器,完成静态资源映射
- 是一个高阶函数
- 当请求时,会根据请求路径(req.path),从指定的目录中寻找是否存在该文件
- 如果存在,直接响应文件内容,而不再移交给后续的中间件
- 如果不存在文件,则直接移交给后续的中间件处理
- 默认情况下,如果映射的结果是一个目录,则会自动使用 index.html 文件
- 可以通过 index 配置项修改
const express = require("express");
const path = require("path");
const staticRoot = path.resolve(__dirname, "../public");
app.use(express.static(staticRoot), {
index: "default.html",
});
// // 只有当路径以 /static 开头时,才会调用中间件
// app.use("/static", express.static(staticRoot));
// // 原理
// // app.use("/static", (req, res) => {
// // console.log(req.baseUrl, req.path);
// // });
2)express.urlencoded()
- 当请求体使用
x-www-form-urlencoded格式发送时- 请求体格式是
name=abc&age=123 - 所以 req.body 返回 undefined
- 因为请求体需要使用流的方式读取
- 读取完毕的字符串再截取后解析为对象
- 请求体格式是
- 除了文件读取可以考虑流的方式传输外,大部分时间都不需要使用流
- 此时可以使用 urlencoded 中间件
- 旧版本使用
querystring库解析 - 新版本使用
qs库解析- 支持的格式更多,官方推荐
- 需要配置 extended
- 旧版本使用
- 当请求体匹配 type 配置项所配置的类型时,自动调用该中间件
- 使用流的方式读取请求体
- 再设置到 req.body 中
{ name: "abc", age: 123 }
app.use(express.urlencoded({ extended: true }));
app.post("/api/student", (req, res) => {
console.log(req.body);
});
3)express.json()
- 当请求体使用
json格式发送时- 请求体格式是
{ name: "abc", age: 123 } - urlencoded 中间件无法处理,转发到下一个中间件
- 请求体格式是
- 可以使用 json 中间件处理
app.use(express.json());
app.post("/api/student", (req, res) => {
console.log(req.body);
});
4)手写 urlencoded 中间件
const qs = require("querystring");
module.exports = (req, res, next) => {
if (req.headers["content-type"] === "application/x-www-form-urlencoded") {
// 自行解析消息体
let result = "";
req.on("data", (chunk) => {
result += chunk.toString("utf-8");
});
req.on("end", () => {
const query = qs.parse(result);
req.body = query;
next();
});
} else {
next();
}
};
// 有配置项时
exports.urlencoded = (options = {}) => {
options.type = options.type || "application/x-www-form-urlencoded";
return (req, res, next) => {
if (req.headers["content-type"] === options.type) {
// 自行解析消息体
let result = "";
req.on("data", (chunk) => {
result += chunk.toString("utf-8");
});
req.on("end", () => {
const query = qs.parse(result);
req.body = query;
next();
});
} else {
next();
}
};
};
前端工程部署
- 可以在根目录下新建
client文件夹,存放前端工程 - 部署方式 1
- 配置前端工程的 build 路径
- 将 build 后的代码存放到
../public(服务器根目录)下
- 部署方式 2
- 配置服务器的静态资源目录
- 改动到
client/dist目录下
5.Express 路由
1)目前 routes 目录基本结构
- 处理 API 请求时有大量重复
- express 提供路由中间件
const express = require("express");
const app = express();
// 映射public目录中的静态资源
const path = require("path");
const staticRoot = path.resolve(__dirname, "../public");
app.use(express.static(staticRoot));
// 解析 application/x-www-form-urlencoded 格式的请求体
app.use(express.urlencoded({ extended: true }));
// 解析 application/json 格式的请求体
app.use(express.json());
// 处理 api 的请求
app.get("/api/student", (req, res) => {
// 获取学生
});
app.post("/api/student", (req, res) => {
// 添加学生
});
app.put("/api/student/:id", (req, res) => {
// 修改学生
});
// 处理错误的中间件
app.use(require("./errorMiddleware"));
const port = 9527;
app.listen(port, () => {
console.log(`server listen on ${port}`);
});
2)使用路由中间件
const studentRouter = express.Router();
studentRouter.get("/", (req, res) => {
// 获取学生
});
studentRouter.post("/", (req, res) => {
// 添加学生
});
studentRouter.put("/:id", (req, res) => {
// 修改学生
});
app.use("/api/student", studentRouter);
3)封装路由中间件
- 统一响应的消息格式
// routes/getSendResult.js
exports.getErr = function (err = "server internal error", errCode = 500) {
return {
code: errCode,
msg: err,
};
};
exports.getResult = function (result) {
return {
code: 0,
msg: "",
data: result,
};
};
exports.asyncHandler = (handler) => {
return async (req, res, next) => {
try {
const result = await handler(req, res, next);
res.send(exports.getResult(result));
} catch (err) {
next(err);
}
};
};
- routes 目录下新建 api 目录
- 存放各个模块的路由中间件
- 模块内部可以连接路由层和服务层
// routes/api/student.js
const express = require("express");
const studentService = require("../../services/studentService");
const { asyncHandler } = require("../getSendResult");
const router = express.Router();
router.get(
"/",
asyncHandler(async (req, res) => {
const page = req.query.page || 1;
const limit = req.query.limit || 10;
const sex = req.query.sex || -1;
const name = req.query.name || "";
return await studentService.getStudents(page, limit, sex, name);
}),
);
router.get(
"/:id",
asyncHandler(async (req, res) => {
return await studentService.getStudentById(req.params.id);
}),
);
router.post(
"/",
asyncHandler(async (req, res, next) => {
return await studentService.addStudent(req.body);
}),
);
router.delete(
"/:id",
asyncHandler(async (req, res, next) => {
return await studentService.deleteStudent(req.params.id);
}),
);
router.put(
"/:id",
asyncHandler(async (req, res, next) => {
return await studentService.updateStudent(req.params.id, req.body);
}),
);
module.exports = router;
- 使用
// routes/init.js
// 处理 api 的请求
app.use("/api/student", require("./api/student"));
app.use("/api/book", require("./api/book"));
app.use("/api/class", require("./api/class"));
app.use("/api/admin", require("./api/admin"));
6.Cookie
1)一个不大不小的问题
- 假设服务器有一个接口,通过请求这个接口,可以添加一个管理员
- 只有登录过的管理员才能添加管理员
- 客户端和服务器的传输使用的是 HTTP 协议
- HTTP 协议是无状态的
- 无状态,就是服务器不知道这一次请求的人,跟之前登录请求成功的人是不是同一个人
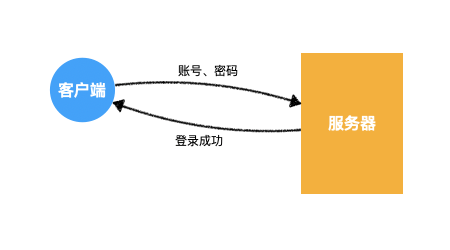
- 由于 HTTP 协议的无状态,服务器忘记了之前的所有请求
- 无法确定这一次请求的客户端,就是之前登录成功的那个客户端
- 于是,服务器想了一个办法,按照下面的流程来认证客户端的身份
- 客户端登录成功后,服务器会给客户端一个出入证(令牌 token)
- 后续客户端的每次请求,都必须要附带这个出入证(令牌 token)
- 服务器发扬了认证不认人的优良传统,就可以很轻松的识别身份了
- 但是,用户不可能只在一个网站登录,于是客户端会收到来自各个网站的出入证
- 因此,就要求客户端要有一个类似于卡包的东西,能够具备下面的功能:
- 能够存放多个出入证
- 这些出入证来自不同的网站
- 也可能是一个网站有多个出入证,分别用于出入不同的地方
- 能够自动出示出入证
- 客户端在访问不同的网站时,能够自动的把对应的出入证附带请求发送出去
- 正确的出示出入证
- 客户端不能将肯德基的出入证发送给麦当劳
- 管理出入证的有效期
- 客户端要能够自动的发现那些已经过期的出入证,并把它从卡包内移除
- 能够存放多个出入证
- 能够满足上面所有要求的,就是 cookie
- cookie 类似于一个卡包,专门用于存放各种出入证,并有着一套机制来自动管理这些证件
- 卡包内的每一张卡片,称之为 一个 cookie
2)Cookie 的组成
- cookie 是浏览器中特有的一个概念,就像浏览器的专属卡包,管理着各个网站的身份信息
- 每个 cookie 就相当于是属于某个网站的一个卡片
| 属性 | 说明 |
|---|---|
| key | 键 |
| value | 值,可以是任何信息 |
| domain | 域,表示这个 cookie 属于哪个网站 |
| path | 路径,表示这个 cookie 属于该网站的哪个基路径 |
| secure | 是否使用安全传输 |
| expire | 过期时间,表示该 cookie 在什么时候过期 |
Cookie 类似 localStorage
- Cookie 其实就是浏览器的一个小文件,保存了一些字符串信息
- Cookie 是自动管理的,一过期就自动删除
- Cookie 保存的 token 是自动发送到服务器的
- 服务器返回的 token 是自动保存到浏览器的
- 存放容量小
- 通常适用于登录认证
- 当浏览器向服务器发送一个请求的时候,会瞄一眼自己的卡包,看看哪些卡片适合附带捎给服务器
- 如果一个 cookie 同时满足 以下条件,则这个 cookie 会自动被浏览器附带到请求中
- cookie 没有过期
- cookie 中的域和这次请求的域是匹配的
如:cookie 中的域是
yuanjin.tech(基域),则可以匹配的请求域是yuanjin.tech、www.yuanjin.tech、blogs.yuanjin.tech等等如:cookie 中的域是
www.yuanjin.tech(二级域),则只能匹配www.yuanjin.tech这样的请求域cookie 不关心端口,只要域匹配即可
- cookie 中的 path 和这次请求的 path 是匹配的
path: '/news',则匹配的请求路径可以是/news、/news/detail、/news/a/b/c等等,但不能匹配/blogspath: '/',则能够匹配所有的路径 - 验证 cookie 的安全传输
如果设置了
secure: true,则请求协议必须是https,否则不会发送该 cookie如果设置了
secure: false,则请求协议可以是http,也可以是https
- 浏览器会将符合条件的 cookie,自动放置到请求头 中
- 如:当在浏览器中访问百度的时候,在请求头中附带了下面的 cookie:
- 打马赛克的地方就是通过请求头
cookie发送到服务器的 - 格式:
键=值; 键=值; 键=值; ... - 每一个键值对就是一个符合条件的 cookie
永远不要把 cookie 泄露给别人
cookie 中包含了重要的身份信息
3)设置 Cookie
- cookie 是保存在浏览器端的
- 很多证件是服务器颁发的
- 所以 cookie 的设置有两种模式
| 模式 | 说明 |
|---|---|
| 服务器响应 | 非常普遍 当服务器决定给客户端颁发一个证件时,会在响应的消息中包含 cookie 浏览器会自动的把 cookie 保存到卡包中 |
| 客户端自行设置 | 少见一些,不过也有可能会发生 如:用户关闭了某个广告,并选择了「以后不要再弹出」 此时就可以把这种小信息直接通过浏览器的 JS 代码保存到 cookie 中 后续请求服务器时,服务器会看到客户端不想要再次弹出广告的 cookie,于是就不会再发送广告过来了 |
4)服务器端设置 Cookie
- 服务器可以通过设置响应头,告诉浏览器应该如何设置 cookie
set-cookie: cookie1
set-cookie: cookie2
set-cookie: cookie3
...
- 通过这种模式,就可以在一次响应中设置多个 cookie
- 每个 cookie 必须设置键值对
- 其他属性都是可选的,并且顺序不限
键=值; path=?; domain=?; expire=?; max-age=?; secure; httponly
- 当这样的响应头到达客户端后,浏览器会 自动地 将 cookie 保存到卡包中
- 如果卡包中已经存在一模一样的卡片(其他 key、path、domain 相同),则会 自动地覆盖之前的设置
a)path
- 设置 cookie 的路径
- 如果不设置,浏览器会将其自动设置为 当前请求的路径
如:浏览器请求的地址是
/login,服务器响应了set-cookie: a=1浏览器会将该 cookie 的 path 设置为请求的路径
/login
b)domain
- 设置 cookie 的域
- 如果不设置,浏览器会自动将其设置为 当前的请求域
- 如果服务器响应了一个 无效的域 ,浏览器同样设置为请求域
如:浏览器请求的地址是
http://www.yuanjin.tech,服务器响应了set-cookie: a=1浏览器会将该 cookie 的 domain 设置为请求的域
www.yuanjin.tech
无效的域
- 响应的域连根域都不一样
- 浏览器请求的域是
yuanjin.tech - 服务器响应的 cookie 是
set-cookie: a=1; domain=baidu.com
- 浏览器请求的域是
- 如果浏览器允许,就意味着张三的服务器,有权利给用户一个 cookie,用于访问李四的服务器
- 这会造成很多安全性的问题
c)expire
- 设置 cookie 的过期时间
- 必须是一个 有效的 GMT 时间,即格林威治标准时间字符串
如:
Fri, 17 Apr 2020 09:35:59 GMT表示格林威治时间2020-04-17 09:35:59即北京时间
2020-04-17 17:35:59当客户端的时间达到这个时间点后,会自动销毁该 cookie
// 获得GMT时间
const gmt = new Date().toGMTString();
d)max-age
- 设置 cookie 的相对有效期
- expire 和 max-age 通常 仅设置一个 即可
- 如果不设置 expire,又没有设置 max-age,则表示 会话结束后过期
- 对于大部分浏览器而言,关闭所有浏览器窗口意味着会话结束
如:设置
max-age为1000浏览器在添加 cookie 时,会自动设置
expire为当前时间加上 1000 秒作为过期时间
e)secure
- 设置 cookie 是否是安全连接
- 如果设置了,则表示该 cookie 后续只能随着
https请求发送 - 如果不设置,则表示该 cookie 会随着所有请求发送
f)httponly
- 设置 cookie 是否仅能用于传输
- 如果设置了,则表示该 cookie 仅能用于传输
- 即不允许在客户端通过 JS 获取,有利于防止跨站脚本攻击(XSS)
5)应用示例
- 客户端通过
post请求服务器http://yuanjin.tech/login - 并在消息体中给予了账号和密码
- 服务器验证登录成功后,在响应头中加入了以下内容:
set-cookie: token=123456; path=/; max-age=3600; httponly
- 当该响应到达浏览器后,浏览器会创建下面的 cookie
key: token
value: 123456
domain: yuanjin.tech
path: /
expire: 2020-04-17 18:55:00 # 假设当前时间是2020-04-17 17:55:00
secure: false # 任何请求都可以附带这个cookie,只要满足其他要求
httponly: true # 不允许JS获取该cookie
- 随着浏览器后续对服务器的请求,只要满足要求,这个 cookie 就会被附带到请求头中传给服务器
cookie: token=123456; 其他cookie...
6)删除浏览器的 cookie
- 只需要让服务器响应一个同样的域、同样的路径、同样的 key,只是时间过期的 cookie 即可
- 删除 cookie 其实就是修改 cookie
cookie: token=; domain=yuanjin.tech; path=/; max-age=-1 # 删除 token
- 浏览器按照要求修改了 cookie 后,会发现 cookie 已经过期,自然就会删除了
注意
- 无论是修改还是删除,都要注意 cookie 的域和路径
- 因为完全可能存在域或路径不同,但 key 相同的 cookie
- 因此无法仅通过 key 确定是哪一个 cookie
// routes/api/admin.js
router.post(
"/login",
asyncHandler(async (req, res) => {
const result = await adminService.login(req.body.loginId, req.body.loginPwd);
if (result) {
// 登录成功
res.header("set-cookie", `token=${result.id}; path=/; domain=localhost; max-age=3600; httponly`);
}
return result;
}),
);
7)客户端设置 Cookie
- cookie 是存放在浏览器端的
- 所以浏览器向 JS 开放了接口,让其可以设置 cookie
document.cookie = "键=值; path=?; domain=?; expire=?; max-age=?; secure";
- 在客户端设置 cookie 和服务器设置 cookie 的格式一样
- 没有 httponly
- httponly 本来就是为了限制在客户端访问的
- path 的默认值
- 在服务器端设置 cookie 时,如果没有写 path,使用的是请求的 path
- 在客户端设置 cookie 时,也许根本没有请求发生
- 因此,path 在客户端设置时的默认值是 当前网页的 path
- domain 的默认值
- 和 path 同理,客户端设置时的默认值是 当前网页的 domain
- 没有 httponly
- 删除 cookie
- 和服务器一样,修改 cookie 的过期时间即可
<form action="/api/admin/login" method="POST">
<p>
<input name="loginId" type="text" />
</p>
<p>
<input name="loginPwd" type="text" />
</p>
<p>
<button>登录</button>
</p>
</form>
8)将 Cookie 用于登录场景
- 登录请求
- 浏览器发送请求到服务器,附带账号密码
- 服务器验证账号密码是否正确
- 如果不正确,响应错误
- 如果正确,在响应头中设置 cookie,附带登录认证信息(如:JWT)
- 客户端收到 cookie,浏览器自动记录下来
- 后续请求
- 浏览器发送请求到服务器,希望添加一个管理员,并将 cookie 自动附带到请求中
- 服务器先获取 cookie,验证 cookie 中的信息是否正确
- 如果不正确,不予以操作
- 如果正确,完成正常的业务流程
7.实现登录和认证
1)使用 cookie-parser 中间件
// 加入cookie-parser 中间件
// 加入之后,会在req对象中注入cookies属性,用于获取所有请求传递过来的cookie
// 加入之后,会在res对象中注入cookie方法,用于设置cookie
const cookieParser = require("cookie-parser");
app.use(cookieParser());
// 应用token中间件
app.use(require("./tokenMiddleware"));
2)登录成功后给予 token
- 通过 cookie 给予
- 适配浏览器
- 通过 header 给予
- 适配其他终端
const cryptor = require("../../util/crypt");
router.post(
"/login",
asyncHandler(async (req, res) => {
const result = await adminService.login(req.body.loginId, req.body.loginPwd);
if (result) {
// // 登录成功
// res.header(
// "set-cookie",
// `token=${result.id}; path=/; domain=localhost; max-age=3600; httponly`
// );
let value = result.id;
value = cryptor.encrypt(value.toString());
// 登录成功
res.cookie("token", value, {
path: "/",
domain: "localhost",
maxAge: 7 * 24 * 3600 * 1000, // 毫秒数
});
res.header("authorization", value);
}
return result;
}),
);
3)对后续请求进行认证
- 解析 cookie 或 header 中的 token
- 验证 token
- 通过,继续后续处理
- 未通过,给予错误
const { pathToRegexp } = require("path-to-regexp");
const { getErr } = require("./getSendResult");
const cryptor = require("../util/crypt");
const needTokenApi = [
{ method: "POST", path: "/api/student" },
{ method: "PUT", path: "/api/student/:id" },
{ method: "GET", path: "/api/student" },
];
// 用于解析token
module.exports = (req, res, next) => {
// /api/student/:id 和 /api/student/1771
const apis = needTokenApi.filter((api) => {
const reg = pathToRegexp(api.path);
return api.method === req.method && reg.test(req.path);
});
if (apis.length === 0) {
next();
return;
}
let token = req.cookies.token;
if (!token) {
// 从header的authorization中获取
token = req.headers.authorization;
}
if (!token) {
// 没有认证
handleNonToken(req, res, next);
return;
}
const userId = cryptor.decrypt(token);
req.userId = userId;
next();
};
// 处理没有认证的情况
function handleNonToken(req, res, next) {
res.status(403).send(getErr("you dont have any token to access the api", 403));
}
4)token 对称加密
- 使用对称加密算法:aes 128
- 密钥固定,向量不固定
// 128位的密钥
const secret = Buffer.from("mm7h3ck87ugk9l4a");
const crypto = require("crypto");
// 准备一个iv,随机向量
const iv = Buffer.from("jxkvxz97409u3m8c");
exports.encrypt = function (str) {
const cry = crypto.createCipheriv("aes-128-cbc", secret, iv);
let result = cry.update(str, "utf-8", "hex");
result += cry.final("hex");
return result;
};
exports.decrypt = function (str) {
const decry = crypto.createDecipheriv("aes-128-cbc", secret, iv);
let result = decry.update(str, "hex", "utf-8");
result += decry.final("utf-8");
return result;
};
// 保证加密解密的随机向量一致
// module.exports = function () {
// // 准备一个iv,随机向量
// const iv = Buffer.from(
// Math.random().toString(36).slice(-8) + Math.random().toString(36).slice(-8)
// );
// return {
// encrypt(str) {
// const cry = crypto.createCipheriv("aes-128-cbc", secret, iv);
// let result = cry.update(str, "utf-8", "hex");
// result += cry.final("hex");
// return result;
// },
// decrypt(str) {
// const decry = crypto.createDecipheriv("aes-128-cbc", secret, iv);
// let result = decry.update(str, "hex", "utf-8");
// result += decry.final("utf-8");
// return result;
// },
// };
// };
8.断点调试
- node 进程会监听 9229 端口
- 其他进程通过向该端口发送信息与 Node 交互
- 使得 Node 进程可以暂停执行、恢复执行、执行下一步后暂停等
- 同时 Node 进程可以将执行栈信息、变量信息等发送给交互进程
- 于是其他应用程序可以调试 Node 程序
node --inspect 启动模块
- vscode 创建 launch.json 可以调试
{
// Use IntelliSense to learn about possible attributes.
// Hover to view descriptions of existing attributes.
// For more information, visit: https://go.microsoft.com/fwlink/?linkid=830387
"version": "0.2.0",
"configurations": [
{
"type": "node",
"request": "attach",
"name": "调试node",
"port": 9229
}
]
}
9.跨域 —— JSONP
1)同源策略
- 同源,协议、端口、主机名完全相同
- 浏览器不允许使用非同源的数据
2)解决方案
- JSONP
- CORS
3)JSONP
- 浏览器端生成一个 script 元素,访问数据接口
function jsonp(url) {
const script = document.createElement("script");
script.src = url;
document.body.appendChild(script);
script.onload = function () {
script.remove();
};
}
function callback(data) {
console.log(data);
}
jsonp("http://localhost:9527/api/student");
- 服务器响应一段 JS 代码,调用某个函数,并把响应的数据传入
router.get("/", async (req, res) => {
const page = req.query.page || 1;
const limit = req.query.limit || 10;
const sex = req.query.sex || -1;
const name = req.query.name || "";
const result = await studentService.getStudents(page, limit, sex, name);
const json = JSON.stringify(result);
const script = `callback(${json})`;
res.header("content-type", "application/javascript").send(script);
});
4)缺陷
- 会严重影响服务器的正常响应格式
- JSONP 要求服务器响应一段 JS 代码
- 但在非跨域的情况下,服务器又需要响应一个正常的 JSON 格式
- 只能使用 GET 请求
script元素发出的请求只能是GET请求
10.跨域 —— CORS
- CORS,Cross-Origin Resource Sharing 跨域资源共享
- 是基于 HTTP1.1 的一种跨域解决方案
- 如果浏览器要跨域访问服务器的资源,需要获得服务器的允许
1)交互模式
- 一个请求可以附带很多信息,从而会对服务器造成不同程度的影响
- 如:有的请求只是获取一些新闻,有的请求会改动服务器的数据
- 针对不同的请求,CORS 规定了三种不同的交互模式
- 简单请求
- 需要预检的请求
- 附带身份凭证的请求
- 这三种模式从上到下层层递进
- 请求可以做的事越来越多,要求也越来越严格
- 当浏览器端运行了一段 Ajax 代码
- 无论是使用 XMLHttpRequest 还是 Fetch API
- 浏览器会首先判断它属于哪一种请求模式
2)简单请求的判定
- 当请求 同时满足 以下条件时,浏览器会认为是一个简单请求
| 条件 | 取值 |
|---|---|
| 请求方法 | GET POST HEAD |
| 请求头仅包含安全的字段 | AcceptAccept-LanguageContent-LanguageContent-TypeDPRDownlinkSave-DataViewport-WidthWidth |
请求头如果包含 Content-Type | text/plainmultipart/form-dataapplication/x-www-form-urlencoded |
// 简单请求
fetch("http://crossdomain.com/api/news");
// 请求方法不满足要求,不是简单请求
fetch("http://crossdomain.com/api/news", {
method: "PUT",
});
// 加入了额外的请求头,不是简单请求
fetch("http://crossdomain.com/api/news", {
headers: {
a: 1,
},
});
// 简单请求
fetch("http://crossdomain.com/api/news", {
method: "post",
});
// content-type不满足要求,不是简单请求
fetch("http://crossdomain.com/api/news", {
method: "post",
headers: {
"content-type": "application/json",
},
});
3)简单请求的交互规范
- 当浏览器判定某个 ajax 跨域请求是简单请求时
- 请求头中会自动添加
Origin字段
// 在页面 `http://my.com/index.html` 中有以下代码造成了跨域
// 简单请求
fetch("http://crossdomain.com/api/news");
# 请求头
GET /api/news/ HTTP/1.1
Host: crossdomain.com
Connection: keep-alive
...
Referer: http://my.com/index.html
Origin: http://my.com # 告诉服务器是哪个源地址在跨域请求
- 服务器响应头中应包含
Access-Control-Allow-Origin*:表示允许所有源地址跨域访问- 具体的源:如:
http://my.com表示仅允许该源地址跨域访问
相关信息
- 实际上,这两个值对于客户端
http://my.com而言都一样- 因为客户端才不会管其他源服务器允不允许,就关心自己是否被允许
- 当然,服务器也可以维护一个可被允许的源列表
- 如果请求的
Origin命中该列表,就响应*或具体的源
- 如果请求的
- 为了避免后续的麻烦,强烈推荐响应具体的源
HTTP/1.1 200 OK
Date: Tue, 21 Apr 2020 08:03:35 GMT
...
Access-Control-Allow-Origin: http://my.com
...
消息体中的数据
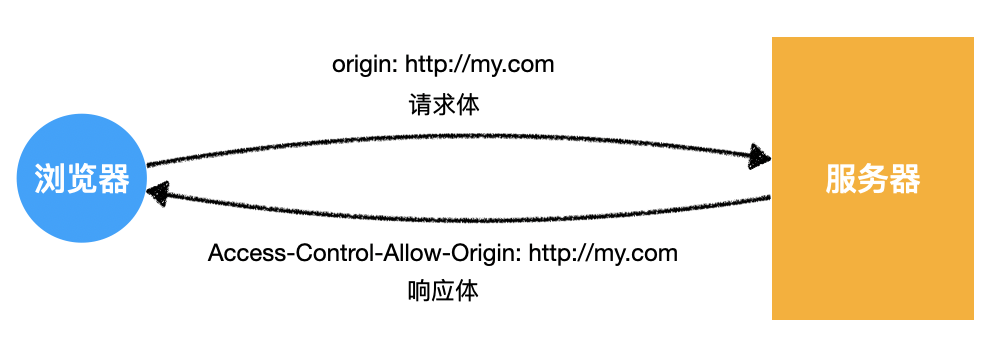
4)需要预检的请求
- 简单的请求对服务器的威胁不大,所以允许使用上述的简单交互即可完成
- 但是如果浏览器不认为这是一种简单请求,就会按照下面的流程进行
- 浏览器发送预检请求,询问服务器是否允许
- 服务器允许
- 浏览器发送真实请求
- 服务器完成真实的响应
// 在页面 `http://my.com/index.html` 中有以下代码造成了跨域
// 需要预检的请求
fetch("http://crossdomain.com/api/user", {
method: "POST", // post 请求
headers: {
// 设置请求头
a: 1,
b: 2,
"content-type": "application/json",
},
body: JSON.stringify({ name: "袁小进", age: 18 }), // 设置请求体
});
5)预检请求的交互规范
- 浏览器发送预检请求,询问服务器是否允许
- 这并非要发出的真实请求,请求中不包含响应头,也没有消息体
- 这是一个预检请求,目的是询问服务器,是否允许后续的真实请求
- 预检请求 没有请求体,包含了后续真实请求要做的事情
- 请求方法为
OPTIONS - 没有请求体
- 请求头中包含
Origin:请求的源,和简单请求的含义一致Access-Control-Request-Method:后续的真实请求将使用的请求方法Access-Control-Request-Headers:后续的真实请求会改动的请求头
- 请求方法为
OPTIONS /api/user HTTP/1.1
Host: crossdomain.com
...
Origin: http://my.com
Access-Control-Request-Method: POST
Access-Control-Request-Headers: a, b, content-type
- 服务器允许
- 服务器收到预检请求后,可以检查预检请求中包含的信息
- 如果允许这样的请求,需要响应下面的消息格式
- 对于预检请求,不需要响应任何的消息体,只需要在响应头中添加:
Access-Control-Allow-Origin:和简单请求一样,表示允许的源Access-Control-Allow-Methods:表示允许的后续真实的请求方法Access-Control-Allow-Headers:表示允许改动的请求头Access-Control-Max-Age:告诉浏览器,多少秒内,对于同样的请求源、方法、头,都不需要再发送预检请求了
HTTP/1.1 200 OK
Date: Tue, 21 Apr 2020 08:03:35 GMT
...
Access-Control-Allow-Origin: http://my.com
Access-Control-Allow-Methods: POST
Access-Control-Allow-Headers: a, b, content-type
Access-Control-Max-Age: 86400
...
- 浏览器发送真实请求
- 预检被服务器允许后,浏览器就会发送真实请求了
POST /api/user HTTP/1.1
Host: crossdomain.com
Connection: keep-alive
...
Referer: http://my.com/index.html
Origin: http://my.com
{"name": "袁小进", "age": 18 }
- 服务器响应真实请求
HTTP/1.1 200 OK
Date: Tue, 21 Apr 2020 08:03:35 GMT
...
Access-Control-Allow-Origin: http://my.com
...
添加用户成功
- 当完成预检之后,后续的处理与简单请求相同
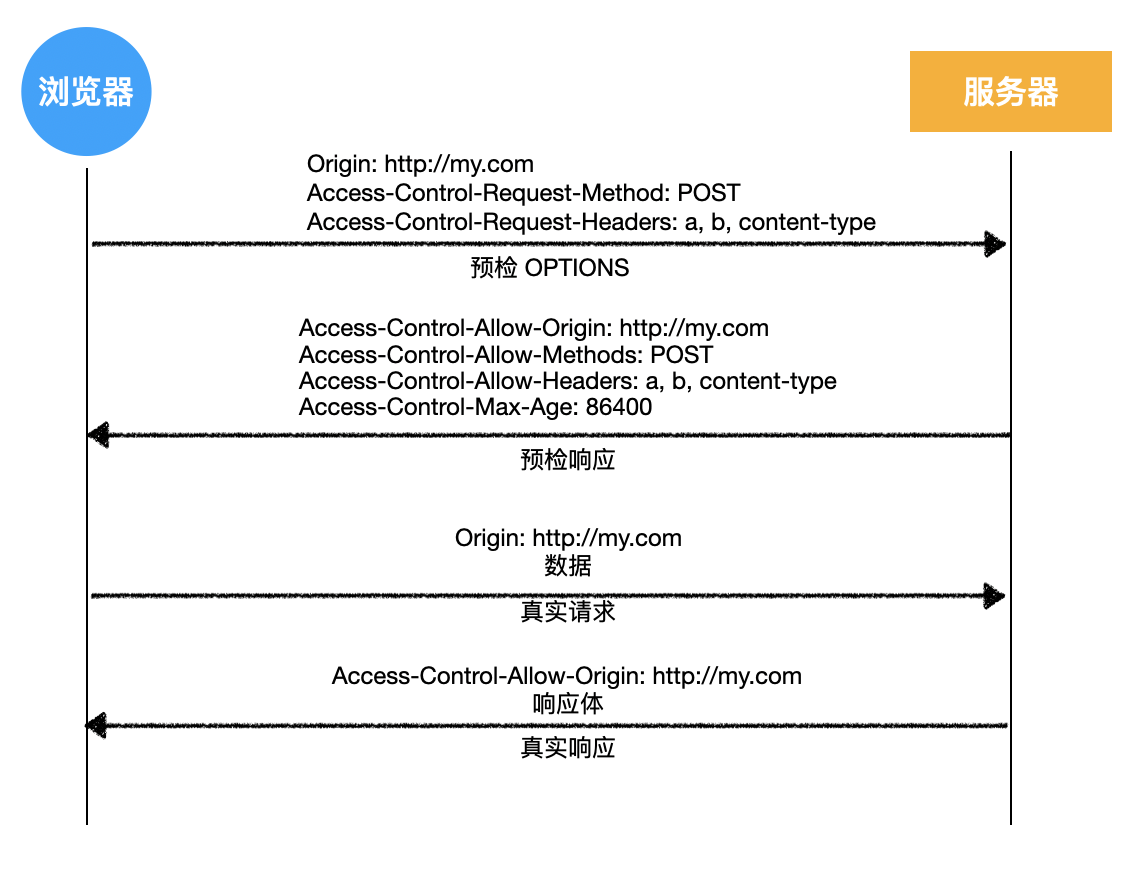
6)附带身份凭证的请求
- 默认情况下,ajax 的跨域请求并不会附带 cookie
- 某些需要权限的操作就无法进行
- 可以通过简单的配置实现附带 cookie
// xhr
var xhr = new XMLHttpRequest();
xhr.withCredentials = true;
// fetch api
fetch(url, {
credentials: "include",
});
- 此时,该跨域的 ajax 请求就是一个附带身份凭证的请求
- 当一个请求需要附带 cookie 时,无论是简单请求,还是预检请求,都会在请求头中添加
cookie字段- 而服务器响应时,需要明确告知客户端:服务器允许这样的凭据
- 只需要在响应头中添加
Access-Control-Allow-Credentials: true即可 - 对于一个附带身份凭证的请求,若服务器没有明确告知,浏览器仍然视为跨域被拒绝
注意
对于附带身份凭证的请求,服务器不得设置 Access-Control-Allow-Origin: *,所以不推荐使用 *
7)JS 访问指定的响应头
- 在跨域访问时,JS 只能拿到一些最基本的响应头
- 如:Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma
- 如果要访问其他头,则需要服务器设置
Access-Control-Expose-Headers- 让服务器把允许浏览器访问的头放入白名单
Access-Control-Expose-Headers: authorization, a, b
11.CORS 中间件
1)自定义中间件基础原理
// routes/corsMiddleware.js
const allowOrigins = ["http://127.0.0.1:5500", "null"];
module.exports = function (req, res, next) {
// 处理预检请求
if (req.method === "OPTIONS") {
res.header(`Access-Control-Allow-Methods`, req.headers["access-control-request-method"]);
res.header(`Access-Control-Allow-Headers`, req.headers["access-control-request-headers"]);
}
// 处理附带身份凭证的请求
res.header("Access-Control-Allow-Credentials", true);
// 处理简单请求
if ("origin" in req.headers && allowOrigins.includes(req.headers.origin)) {
res.header("access-control-allow-origin", req.headers.origin);
}
next();
};
2)使用第三方中间件
const cors = require("cors");
// app.use(cors());
const whiteList = ["http://127.0.0.1:5500", "http://localhost:9527", "null"];
app.use(
cors({
origin(origin, callback) {
if (!origin) {
callback(null, "*");
return;
}
if (whiteList.includes(origin)) {
callback(null, origin);
} else {
callback(new Error("not allowed"));
}
},
credentials: true,
}),
);
12.Session
1)Cookie 和 Session 对比
- 通常项目都是 Cookie、Session、JWT 相互配合存储信息
- 不存在谁取代谁
| 对比项 | Cookie | Session |
|---|---|---|
| 存储位置 | 客户端 | 服务器端 |
| 存储格式 | 只能是字符串格式 | 可以是任何格式 |
| 存储量 | 存储量有限(多数浏览器只提供 4KB) | 存储量理论上是无限的 |
| 数据安全 | 数据容易被获取、被篡改,容易丢失 | 数据难以被获取、被篡改,不易丢失 |
Cookie 存储量有限解决方案
- 可用 sessionStorage、localStorage 替换
- 存储量可达 10MB 左右
- 但是不会自动发送给服务器
- 且无法设置 cookie 的一些配置项
2)Session 原理
- 服务器存储的 sessionID 基本用的都是 UUID
- UUID,Universal Unique Identity,全球唯一 ID
- 需要保证唯一性
3)使用中间件
- 配置项的 secret 用于加密 cookie
- 使用 cookie 中间件时应该用相同的密钥解密
const session = require("express-session");
app.use(
session({
secret: "yuanjin",
name: "sessionid",
}),
);
4)使用 session 完成登录认证
- 客户端发送请求
login.onclick = function () {
fetch("http://localhost:9527/api/admin/login", {
method: "POST",
headers: {
"content-type": "application/json",
},
body: JSON.stringify({
loginId: "abc",
loginPwd: "123456",
}),
})
.then((resp) => resp.json())
.then((resp) => {
console.log(resp);
});
};
updateStu.onclick = function () {
fetch("http://localhost:9527/api/student/1201", {
method: "PUT",
headers: {
"content-type": "application/json",
},
body: JSON.stringify({
name: "123",
}),
})
.then((resp) => resp.json())
.then((resp) => {
console.log(resp);
});
};
- 服务器 API 接口保存 session
router.post(
"/login",
asyncHandler(async (req, res) => {
const result = await adminService.login(req.body.loginId, req.body.loginPwd);
if (result) {
let value = result.id;
value = cryptor.encrypt(value.toString());
//登录成功
req.session.loginUser = result;
}
return result;
}),
);
- token 中间件判断 session
// 用于解析token
module.exports = (req, res, next) => {
// /api/student/:id 和 /api/student/1771
const apis = needTokenApi.filter((api) => {
const reg = pathToRegexp(api.path);
return api.method === req.method && reg.test(req.path);
});
if (apis.length === 0) {
next();
return;
}
if (req.session.loginUser) {
//说明已经登录过了
next();
} else {
handleNonToken(req, res, next);
}
};
13.JWT
1)背景
- 随着前后端分离的发展,以及数据中心的建立,越来越多的公司会创建一个中心服务器,服务于各种产品线
- 而这些产品线上的产品可能有着各种终端设备
- 包括但不仅限于浏览器、桌面应用、移动端应用、平板应用、甚至智能家居
- 实际上,不同的产品线通常有自己的服务器,产品内部的数据一般和自己的服务器交互
- 但中心服务器仍然有必要存在,因为同一家公司的产品总是会存在共享的数据
- 比如用户数据
- 这些设备与中心服务器之间会进行 HTTP 通信
- 一般来说,中心服务器至少承担着 认证和授权 的功能
- 如:登录
- 各种设备发送消息到中心服务器,然后中心服务器响应一个身份令牌
- 参见 cookie 原理详解
- 这种结构也可以继续使用传统的 cookie 方式传递令牌信息
- cookie 在传输中无非是一个消息头而已
- 只不过浏览器对这个消息头有特殊处理罢了
- 但浏览器之外的设备肯定不喜欢 cookie
- 因为浏览器有着对 cookie 完善的管理机制
- 但是在其他设备上,就需要开发者自己手动处理了
- JWT 的出现就是为了解决这个问题
2)简介
- JWT, JSON Web Token
- 为多种终端设备提供统一的、安全的令牌格式
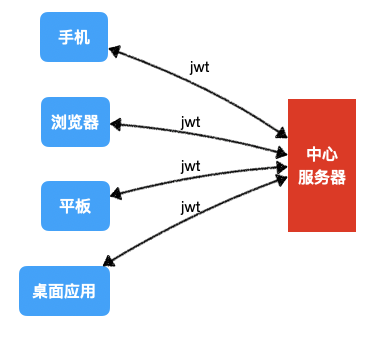
- 可以存储到 cookie,也可以存储到 localStorage
- 可以使用任何传输方式来传输
- 一般来说,会使用 消息头
- 如:当登录成功后,服务器可以给客户端响应一个 JWT
HTTP/1.1 200 OK
---
set-cookie:token=JWT令牌
authorization:JWT令牌
---
{ ..., token:JWT令牌 }
- 可以出现在响应的任何一个地方
- 客户端和服务器自行约定即可
- 可以出现在响应的多个地方
- 如:为了充分利用浏览器的 cookie,同时为了照顾其他设备
- 可以让 JWT 出现在
set-cookie和authorization或body中- 会增加额外的传输量
- 可以存储到任何位置
- 如:手机文件、PC 文件、localStorage、cookie
- 当后续请求发生时,只需要将它作为请求的一部分发送到服务器即可
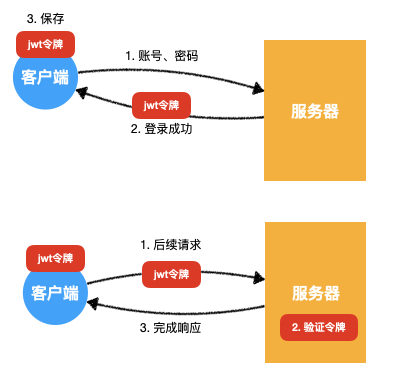
JWT 格式
- JWT 没有明确要求附带到请求的格式
- 通常会使用如下的格式
- 这种格式是 OAuth2 附带 token 的一种规范格式
GET /api/resources HTTP/1.1
---
authorization: bearer JWT令牌
3)令牌的组成
- 为了保证令牌的安全性,JWT 令牌由三个部分组成
- 完整格式:
header.payload.signature
| 组成 | 说明 |
|---|---|
| header | 令牌头部,记录了整个令牌的类型和签名算法 |
| payload | 令牌负荷,记录了保存的主体信息 如:要保存的用户信息 |
| signature | 令牌签名,按照头部固定的签名算法对整个令牌进行签名 该签名的作用是:保证令牌不被伪造和篡改 |
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9.BCwUy3jnUQ_E6TqCayc7rCHkx-vxxdagUwPOWqwYCFc
# header:eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9
# payload:eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9
# signature: BCwUy3jnUQ_E6TqCayc7rCHkx-vxxdagUwPOWqwYCFc
4)header
- 令牌头部,记录了整个令牌的类型和签名算法
- 格式是一个 JSON 对象
- alg(algorithm)
- signature 部分使用的签名算法,通常可以取两个值
- HS256:一种对称加密算法,使用同一个秘钥对 signature 加密解密
- RS256:一种非对称加密算法,使用私钥加密,公钥解密
- typ(type)
- 整个令牌的类型,固定写
JWT即可
- 整个令牌的类型,固定写
{
"alg": "HS256",
"typ": "JWT"
}
- 设置好
header后就可以生成header部分了 - 把
header部分使用base64 url编码即可base64 url不是一个加密算法,而是一种编码方式- 是在
base64算法的基础上对+、=、/三个字符做出特殊处理的算法 - 而
base64是使用 64 个可打印字符来表示一个二进制数据 - 具体的做法参考 百度百科
- 浏览器提供了
btoa函数对 header 编码
window.btoa(
JSON.stringify({
alg: "HS256",
typ: "JWT",
}),
);
// eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9
- 同样的,浏览器也提供了
atob函数对其解码
window.atob("eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9");
// {"alg":"HS256","typ":"JWT"}
提示
- NodeJS 中没有提供这两个函数,可以安装第三方库
atob和bota - 或者手动编码解码
5)payload
- JWT 的主体信息,仍然是一个 JSON 对象
- 可以包含以下内容
{
"ss":"发行者",
"iat":"发布时间",
"exp":"到期时间",
"sub":"主题",
"aud":"听众",
"nbf":"在此之前不可用",
"jti":"JWT ID"
}
- 可以全写,也可以一个都不写,只是一个规范
- 就算写了,也需要在将来验证这个 JWT 令牌时手动处理才能发挥作用
| 属性 | 含义 |
|---|---|
ss | 发行该 JWT 的是谁 可以写公司名字,也可以写服务名称 |
iat | 该 JWT 的发放时间 通常写当前时间的时间戳 |
exp | 该 JWT 的到期时间 通常写时间戳 |
sub | 该 JWT 是用于干嘛的 |
aud | 该 JWT 是发放给哪个终端的 可以是终端类型,也可以是用户名称,随意一点 |
nbf | 一个时间点 在该时间点到达之前,这个令牌是不可用的 |
jti | JWT 的唯一编号 设置此项的目的,主要是为了防止重放攻击 |
重放攻击
在某些场景下,用户使用之前的令牌发送到服务器,被服务器正确的识别,从而导致不可预期的行为发生
- payload 这一部分只是一个 json 对象而已
- 可以向对象中加入任何想要加入的信息
foo: bar是自定义的信息iat: 1587548215是 JWT 规范中的信息
{
"foo": "bar",
"iat": 1587548215
}
- payload 部分和 header 一样,需要通过
base64 url编码
window.btoa(
JSON.stringify({
foo: "bar",
iat: 1587548215,
}),
);
// eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9
6)signature
- JWT 的签名,保证了整个 JWT 不被篡改
- 这部分的生成,是对前面两个部分的编码结果,按照头部指定的方式进行加密
- 如:头部指定的加密方法是
HS256,前面两部分的编码结果是eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9 - 则第三部分就是用对称加密算法
HS256对字符串eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9进行加密 - 当然需要指定一个秘钥,比如
shhhhh
- 如:头部指定的加密方法是
HS256(`eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9`, "shhhhh");
// BCwUy3jnUQ_E6TqCayc7rCHkx-vxxdagUwPOWqwYCFc
- 将三部分组合在一起,就得到了完整的 JWT
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJmb28iOiJiYXIiLCJpYXQiOjE1ODc1NDgyMTV9.BCwUy3jnUQ_E6TqCayc7rCHkx-vxxdagUwPOWqwYCFc
- 由于签名使用的秘钥保存在服务器,客户端就无法伪造出签名,因为拿不到秘钥
- 之所以说无法伪造 JWT,就是因为第三部分 signature 的存在
- 而前面两部分并没有加密,只是一个编码结果而已,可以认为几乎是明文传输
- 不要把敏感的信息存放到 JWT 中,如:密码
7)令牌的验证
- 令牌在服务器组装完成后,会以任意的方式发送到客户端
- 客户端会把令牌保存起来,后续的请求会将令牌发送给服务器
- 而服务器需要验证令牌是否正确
- 对
header + payload用同样的秘钥和加密算法进行重新加密 - 把加密的结果和传入 JWT 的
signature进行对比 - 如果完全相同,则表示 JWT 没有被篡改
- 如果不同,肯定是被篡改过了
- 对
传入的header.传入的payload.传入的signature
新的signature = header中的加密算法(传入的header.传入的payload, 秘钥)
验证:新的signature === 传入的signature
- 当令牌验证为没有被篡改后,服务器可以进行其他验证
- 如:是否过期、听众是否满足要求等等
- 这些验证都需要服务器手动完成,没有哪个服务器会自动验证
- 可以借助第三方库来完成
8)JWT 的特点
- JWT 本质上是一种令牌格式
- 和终端设备无关,同样和服务器无关,甚至与如何传输无关,只是规范了令牌的格式而已
- JWT 由三部分组成:header、payload、signature
- 主体信息在 payload
- JWT 难以被篡改和伪造
- 因为有第三部分的签名存在
14.登录和认证 —— 服务器开发
- jsonwebtoken
- Express 依赖 jsonwebtoken 库封装了 express-jwt 中间件
1)颁发 JWT
- 确定过期时间
- 确定主体
- 确定密钥
- 确定传输方式
- Cookie
- Authorization
// routes/jwt.js
exports.publish = function (res, maxAge = 3600 * 24, info = {}) {
const token = jwt.sign(info, secrect, {
expiresIn: maxAge,
});
// 添加到cookie
res.cookie(cookieKey, token, {
maxAge: maxAge * 1000,
path: "/",
});
// 添加其他传输
res.header("authorization", token);
};
2)认证 JWT
- 获取 JWT
- 从 Cookie 中
- 从 Authorization 中
- 带 Bearer
- 不带 Bearer
- 验证 JWT
// routes/jwt.js
exports.verify = function (req) {
let token;
// 尝试从cookie中获取
token = req.cookies[cookieKey]; // cookie中没有
if (!token) {
// 尝试中header中
token = req.headers.authorization;
if (!token) {
// 没有token
return null;
}
// authorization: bearer token
token = token.split(" ");
token = token.length === 1 ? token[0] : token[1];
}
try {
const result = jwt.verify(token, secrect);
return result;
} catch (err) {
return null;
}
};
3)服务器 API 登录接口保存 JWT
router.post(
"/login",
asyncHandler(async (req, res) => {
const result = await adminService.login(req.body.loginId, req.body.loginPwd);
if (result) {
let value = result.id;
// 登录成功
jwt.publish(res, undefined, { id: value });
}
return result;
}),
);
4)token 中间件解析 JWT
module.exports = (req, res, next) => {
// /api/student/:id 和 /api/student/1771
const apis = needTokenApi.filter((api) => {
const reg = pathToRegexp(api.path);
return api.method === req.method && reg.test(req.path);
});
if (apis.length === 0) {
next();
return;
}
const result = jwt.verify(req);
if (result) {
// 认证通过
req.userId = result.id;
next();
} else {
// 认证失败
handleNonToken(req, res, next);
}
};
5)添加 whoami 接口
- API 接口
router.get(
"/whoami",
asyncHandler(async (req, res) => {
return await adminService.getAdminById(req.userId);
}),
);
- token 中间件白名单
const needTokenApi = [
{ method: "POST", path: "/api/student" },
{ method: "PUT", path: "/api/student/:id" },
{ method: "GET", path: "/api/student" },
{ method: "GET", path: "/api/admin/whoami" },
];
15.登录和认证 —— 客户端开发
1)工程结构
- client 目录
- 存放前端 Vue 工程
- public 目录
- 存放前端 Vue 工程打包后的 dist 目录下的文件
- 根目录
- 后端 Node 工程
2)服务端准备
- nodemon 忽略 client 目录
{
"env": {
"NODE_ENV": "development"
},
"watch": ["*.js", "*.json"],
"ignore": ["package*.json", "nodemon.json", "node_modules", "public", "client"]
}
- 取消服务端路由的白名单限制
// routes/init.js
app.use(
cors({
origin(origin, callback) {
if (!origin) {
callback(null, "*");
return;
}]
callback(null, origin);
},
credentials: true,
})
);
- JWT 配置代码取消使用 Cookie
- 真实开发环境下后端不会管理 Cookie
// routes/jwt.js
// 颁发jwt
exports.publish = function (res, maxAge = 3600 * 24, info = {}) {
const token = jwt.sign(info, secrect, {
expiresIn: maxAge,
});
res.header("authorization", token);
};
// 认证jwt
exports.verify = function (req) {
let token;
token = req.headers.authorization;
if (!token) {
// 没有token
return null;
}
// authorization: bearer token
token = token.split(" ");
token = token.length === 1 ? token[0] : token[1];
try {
const result = jwt.verify(token, secrect);
return result;
} catch (err) {
return null;
}
};
3)搭建 Vue 工程
vue create client
- package.json
{
"name": "client",
"version": "0.1.0",
"private": true,
"scripts": {
"serve": "vue-cli-service serve",
"build": "vue-cli-service build"
},
"dependencies": {
"axios": "^0.19.2",
"core-js": "^3.6.4",
"vue": "^2.6.11",
"vue-router": "^3.1.6",
"vuex": "^3.1.3"
},
"devDependencies": {
"@vue/cli-plugin-babel": "~4.3.0",
"@vue/cli-plugin-router": "~4.3.0",
"@vue/cli-plugin-vuex": "~4.3.0",
"@vue/cli-service": "~4.3.0",
"vue-template-compiler": "^2.6.11"
}
}
4)配置 API 代理
// vue.config.js
const path = require("path");
module.exports = {
devServer: {
proxy: {
"/api": {
target: "http://localhost:9527",
},
},
},
};
5)封装 axios 配置
// service/request.js
/**
* 1. 发送请求的时候,如果有token,需要附带到请求头中
* 2. 响应的时候,如果有token,保存token到本地(localStorage)
* 3. 响应的时候,如果响应的消息码是403(没有token,token失效),在本地删除token
*/
import axios from "axios";
export default function () {
// 发送请求
const token = localStorage.getItem("token");
let instance = axios;
if (token) {
instance = axios.create({
headers: {
authorization: "bearer " + token,
},
});
}
instance.interceptors.response.use(
(resp) => {
// 保存token到本地
if (resp.headers.authorization) {
localStorage.setItem("token", resp.headers.authorization);
}
return resp;
},
(err) => {
// 本地删除token
if (err.response.status === 403) {
localStorage.removeItem("token");
}
return Promise.reject(err);
},
);
return instance;
}
6)封装 API 请求接口
// service/loginService.js
import request from "./request";
// 模拟网络延迟
const delay = (duration) => {
return new Promise((resolve) => {
setTimeout(() => {
resolve();
}, duration);
});
};
export const login = async (loginId, loginPwd) => {
await delay(2000);
const resp = await request().post("/api/admin/login", {
loginId,
loginPwd,
});
return resp.data;
};
export const loginOut = () => {
localStorage.removeItem("token");
};
export const whoAmI = async () => {
await delay(2000);
const resp = await request().get("/api/admin/whoami");
return resp.data;
};
7)封装登录用户的数据仓库模块
// store/loginUser.js
import * as loginService from "../service/loginService";
export default {
namespaced: true,
state: {
data: null,
isLoading: false,
},
mutations: {
setData(state, payload) {
state.data = payload;
},
setIsLoading(state, payload) {
state.isLoading = payload;
},
},
actions: {
async login({ commit }, { loginId, loginPwd }) {
commit("setIsLoading", true);
const resp = await loginService.login(loginId, loginPwd);
commit("setData", resp.data);
commit("setIsLoading", false);
return resp.data;
},
loginOut({ commit }) {
commit("setData", null);
loginService.loginOut();
},
async whoAmI({ commit }) {
commit("setIsLoading", true);
try {
const resp = await loginService.whoAmI();
commit("setData", resp.data);
} catch {
commit("setData", null);
}
commit("setIsLoading", false);
},
},
};
8)使用数据仓库
- 导出数据仓库和模块
// store/index.js
import Vue from "vue";
import Vuex from "vuex";
import loginUser from "./loginUser";
Vue.use(Vuex);
export default new Vuex.Store({
modules: {
loginUser,
},
});
- 页面初始化后先判断是否已登录
// main.js
import store from "./store";
// 在网站被访问时,需要用token去换取用户的身份
store.dispatch("loginUser/whoAmI");
new Vue({
router,
store,
render: (h) => h(App),
}).$mount("#app");
9)登录功能
// views/Login.vue
async handleClick() {
const user = await this.$store.dispatch("loginUser/login", {
loginId: this.loginId,
loginPwd: this.loginPwd,
});
if (user) {
// 成功
this.$router.push("/");
} else {
alert("账号密码错误");
}
},
10)配置路由守卫
// router/index.js
const routes = [
{
path: "/",
component: Home,
},
{
path: "/protect",
component: () => import("../views/Protect.vue"),
beforeEnter(to, from, next) {
if (store.state.loginUser.data) {
// 有用户
next();
} else {
next("/login");
}
},
},
{
path: "/login",
component: () => import("../views/Login.vue"),
},
];
11)打包
- 打包到服务器静态资源目录 public
- 访问 http://localhost:9527
// vue.config.js
const path = require("path");
module.exports = {
devServer: {
proxy: {
"/api": {
target: "http://localhost:9527",
},
},
},
outputDir: path.resolve(__dirname, "../public"),
};
- 解决服务器刷新后 404 问题
- History API Fallback
// routes/init.js
const history = require("connect-history-api-fallback");
app.use(history());
16.场景 —— 日志记录
1)修改日志配置文件
// logger.js
const log4js = require("log4js");
const path = require("path");
// 封装sql和api公共appenders
const getCommonAppenders = (pathName) => {
return {
// 定义一个sql日志出口
type: "dateFile",
filename: path.resolve(__dirname, "logs", pathName, "logging.log"),
maxLogSize: 1024 * 1024, // 配置文件的最大字节数
keepFileExt: true,
numBackups: 3, // 日志文件保留三天
layout: {
type: "pattern",
pattern: "%c [%d{yyyy-MM-dd hh:mm:ss}] [%p]: %m%n",
},
};
};
log4js.configure({
appenders: {
sql: getCommonAppenders("sql"),
default: {
type: "stdout",
},
api: getCommonAppenders("api"),
},
categories: {
sql: {
appenders: ["sql"],
level: "all",
},
default: {
appenders: ["default"],
level: "all",
},
api: {
appenders: ["api"],
level: "all",
},
},
});
// 程序正/异常退出时,还没记录完成的日志记录完
process.on("exit", () => {
log4js.shutdown();
});
const sqlLogger = log4js.getLogger("sql");
const apiLogger = log4js.getLogger("api");
const defaultLogger = log4js.getLogger();
exports.sqlLogger = sqlLogger;
exports.apiLogger = apiLogger;
exports.logger = defaultLogger;
2)定义记录 API 请求日志中间件
// routes/apiLoggerMiddleware.js
const { apiLogger } = require("../logger.js");
const log4js = require("log4js");
// 手动记录
// module.exports = (req, res, next) => {
// next();
// apiLogger.debug(`${req.method} ${req.path} ${req.ip}`);
// };
// 自动记录
module.exports = log4js.connectLogger(apiLogger, {
level: "auto",
});
3)请求 API 接口前使用中间件
// routes/init.js
app.use(require("./apiLoggerMiddleware"));
17.场景 —— 文件上传
1)文件上传使用的 HTTP 报文格式
- 消息体使用 form-data 格式传输
----WebKitFormBoundary7MA4YWxkTrZu0gW是分界线- 分割表单中每一个数据
- 随机生成的字符串
- 表单数据是键值对
- 该格式适合传输大数据
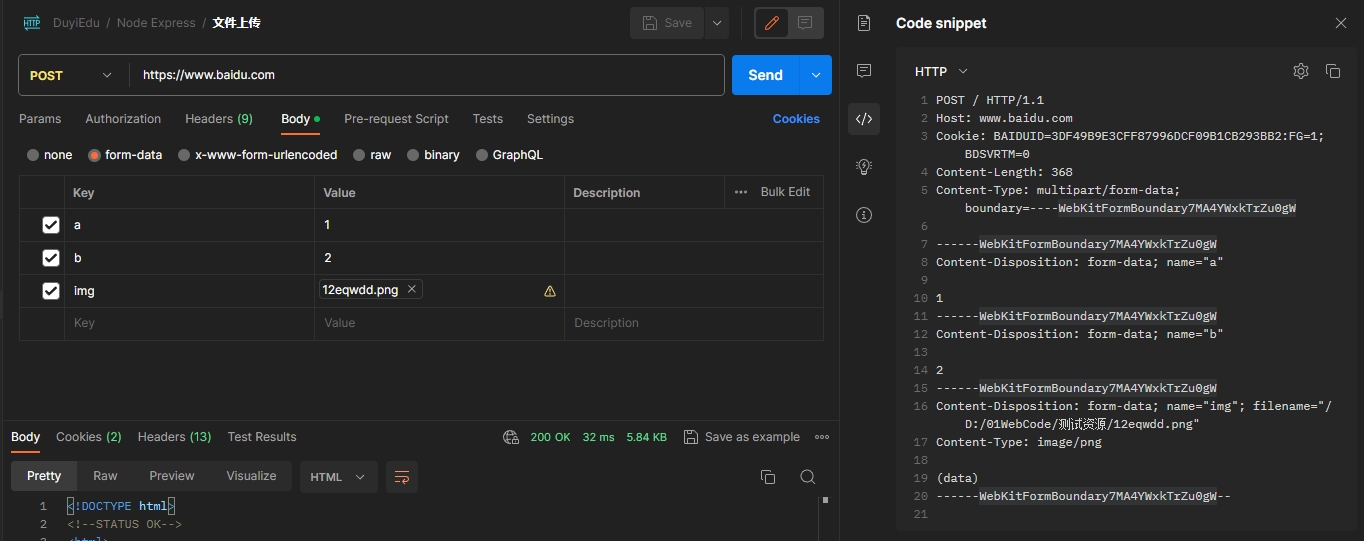
POST / HTTP/1.1
Host: www.baidu.com
Cookie: BAIDUID=3DF49B9E3CFF87996DCF09B1CB293BB2:FG=1; BDSVRTM=0
Content-Length: 368
Content-Type: multipart/form-data; boundary=----WebKitFormBoundary7MA4YWxkTrZu0gW
------WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="a"
1
------WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="b"
2
------WebKitFormBoundary7MA4YWxkTrZu0gW
Content-Disposition: form-data; name="img"; filename="/D:/01WebCode/测试资源/12eqwdd.png"
Content-Type: image/png
(data)
------WebKitFormBoundary7MA4YWxkTrZu0gW--
2)客户端使用传统 form 表单上传文件
<form action="/api/upload" method="POST" enctype="multipart/form-data">
<p>
<input name="a" type="text" />
</p>
<p>
<input name="img" type="file" />
</p>
<p>
<button>提交</button>
</p>
</form>
- 服务器定义 API 接口
// routes/api/upload.js
const express = require("express");
const router = express.Router();
router.post("/", (req, res) => {
res.send("服务器完成了图片处理");
});
module.exports = router;
// routes/init.js
app.use("/api/upload", require("./api/upload"));
3)客户端使用 ajax 创建 FormData 对象上传文件
<p>
<input name="a" type="text" />
</p>
<p>
<input name="img" type="file" accept="image/*" multiple />
</p>
<p>
<button>提交</button>
</p>
<img src="" alt="" />
<script>
function upload() {
const inpA = document.querySelector("[name=a]");
const inpFile = document.querySelector("[name=img]");
const img = document.querySelector("img");
const formData = new FormData(); // 构建form-data格式的消息体
formData.append("a", inpA.value);
for (const file of inpFile.files) {
formData.append("img", file, file.name);
}
fetch("/api/upload", {
body: formData,
method: "POST",
})
.then((resp) => resp.json())
.then((resp) => {
console.log(resp);
if (resp.code) {
// 有错误
alert(resp.msg);
} else {
img.src = resp.data;
}
});
}
document.querySelector("button").onclick = upload;
</script>
4)服务器解析处理请求体
// routes/api/upload.js
const express = require("express");
const router = express.Router();
const multer = require("multer");
const path = require("path");
// 保存的文件没有后缀名,会自动创建目录
// const upload = multer({
// dest: path.resolve(__dirname, "../../public", "upload"),
// });
// 配置磁盘存储引擎,使保存的文件有后缀名,需要手动创建目录
const storage = multer.diskStorage({
// 上传的文件存储的目录,一般在gitignore中忽略,服务器本身有自己的目录存放用户上传的文件
destination: function (req, file, cb) {
cb(null, path.resolve(__dirname, "../../public/upload"));
},
filename: function (req, file, cb) {
// 时间戳-6位随机字符.文件后缀
const timeStamp = Date.now();
const randomStr = Math.random().toString(36).slice(-6);
const ext = path.extname(file.originalname);
const filename = `${timeStamp}-${randomStr}${ext}`;
cb(null, filename);
},
});
const upload = multer({
storage,
limits: {
fileSize: 150 * 1024,
},
fileFilter(req, file, cb) {
// 验证文件后缀名
const extname = path.extname(file.originalname);
const whitelist = [".jpg", ".gif", "png"];
if (whitelist.includes(extname)) {
cb(null, true);
} else {
cb(new Error(`your ext name of ${extname} is not support`));
}
},
});
router.post("/", upload.single("img"), (req, res) => {
const url = `/upload/${req.file.filename}`;
res.send({
code: 0,
msg: "",
data: url,
});
});
module.exports = router;
5)错误处理
// routes/errorMiddleware.js
const getMsg = require("./getSendResult");
const multer = require("multer");
module.exports = (err, req, res, next) => {
// 获取基地址(调用中间件的use函数的第一个参数)
console.log(req.baseUrl);
if (err) {
// const errObj = {
// code: 500,
// msg: err instanceof Error ? err.message : err,
// };
// // 发生了错误
// res.status(500).send(errObj);
if (err instanceof multer.MulterError) {
res.status(200).send(getMsg.getErr(err.message));
return;
}
const errObj = err instanceof Error ? err.message : err;
res.status(500).send(getMsg.getErr(errObj));
} else {
next();
}
};
18.场景 —— 文件下载
1)API 接口
- 约定请求
GET /download/文件名时 - 请求 API,获取 resources 目录下对应的文件
app.use("/download", require("./api/download"));
- 请求服务器目录下的文件
res.download(绝对路径,下载时的默认文件名,错误处理对象)
// routes/api/download.js
const express = require("express");
const path = require("path");
const router = express.Router();
router.get("/:filename", (req, res) => {
const absPath = path.resolve(__dirname, "../../resources", req.params.filename);
res.download(absPath, req.params.filename);
});
module.exports = router;
2)原理
- 响应头中的关键字段
Content-Disposition - 告诉客户端如何处理响应的数据/文件
attachment:将响应体作为附件处理- 附件格式触发浏览器下载行为
{
"Content-Disposition": "attachment; filename='test.png'",
"Content-Type": "image/png", // 文件类型
"Content-Length": "22620", // 文件字节数
"Accept-Ranges": "bytes" // 是否支持断点续传,表示服务器支持断点续传的单位,没有该属性或值为null则不支持
}
3)迅雷下载协议
- 得到完整的下载地址
- 格式转换为
AA地址ZZ - 然后转换为 base64 编码
- 最后拼接协议头
thunder://base64编码
<a resrole="thunder" href="/res/hill.zip">下载</a>
<script>
const a = document.querySelector("a[resrole=thunder]");
let thunderLink = `AA${a.href}ZZ`;
thunderLink = btoa(thunderLink);
thunderLink = "thunder://" + thunderLink;
a.href = thunderLink;
</script>
4)断点续传
- 发送请求时,请求头携带
Ranges - 实现读取流指定范围的数据
- 有些下载器在发送下载请求前会先发送
HEAD请求- 通过该请求响应头中的
Accept-Ranges判断是否支持断点续传 - 如果支持,后续下载请求再携带
Ranges
- 通过该请求响应头中的
19.场景 —— 图片水印
1)加水印方案一:上传时加水印
- 用户上传原始图片
- 服务器保存原始图片和水印图片
- 用户请求图片时返回水印图片
- 请求响应速度快,修改水印较麻烦
2)加水印方案二:动态水印
- 用户上传原始图片
- 服务器只保存原始图片
- 用户请求图片时服务器动态加水印
- 请求响应速度慢,修改水印较方便
3)原理
- 其实就是修改图片数据
// routes/util/watermark.js
const path = require("path");
const jimp = require("jimp");
// 给一张图片加水印
export const mark = async (
waterFile,
originFile,
targetFile,
proportion = 5, // 原始图片宽高比例(目标比例)
marginProportion = 0.01,
) => {
const [water, origin] = await Promise.all([jimp.read(waterFile), jimp.read(originFile)]);
// 对水印图片进行缩放
const curProportion = origin.bitmap.width / water.bitmap.width;
water.scale(curProportion / proportion);
// 计算位置
const right = origin.bitmap.width * marginProportion;
const bottom = origin.bitmap.height * marginProportion;
const x = origin.bitmap.width - right - water.bitmap.width;
const y = origin.bitmap.height - bottom - water.bitmap.height;
// 写入水印
origin.composite(water, x, y, {
mode: jimp.BLEND_SOURCE_OVER,
opacitySource: 0.3,
});
await origin.write(targetFile);
};
module.exports = mark;
4)上传图片时加水印
const watermark = require("../../util/watermark");
const waterPath = path.resolve(__dirname, "../../public/img/water.jpg");
const storage = multer.diskStorage({
destination: function (req, file, cb) {
cb(null, path.resolve(__dirname, "../../public/origin"));
},
});
router.post("/", upload.single("img"), async (req, res) => {
const url = `/upload/${req.file.filename}`;
// 加水印
const newPath = path.resolve(__dirname, "../../public/upload", req.file.filename);
await watermark(waterPath, req.file.path, newPath);
res.send({
code: 0,
msg: "",
data: url,
});
});
20.场景 —— 图片防盗链
- 根据浏览器请求头的字段
referer - 判断当前请求的主机是否是服务器
// routes/imgProtectMiddleware.js
const url = require("url");
const path = require("path");
module.exports = (req, res, next) => {
const host = req.headers.host; // 获取本网站的主机名(包括端口号)
let referer = req.headers.referer;
// 只处理图片
const extname = path.extname(req.path);
if (![".jpg", ".jpeg", ".png", ".gif"].includes(extname)) {
next();
return;
}
if (referer) {
referer = url.parse(referer).host;
}
if (referer && host !== referer) {
req.url = "/img/logo.jpg"; // url rewrite
}
next();
};
21.场景 —— 代理【重要】
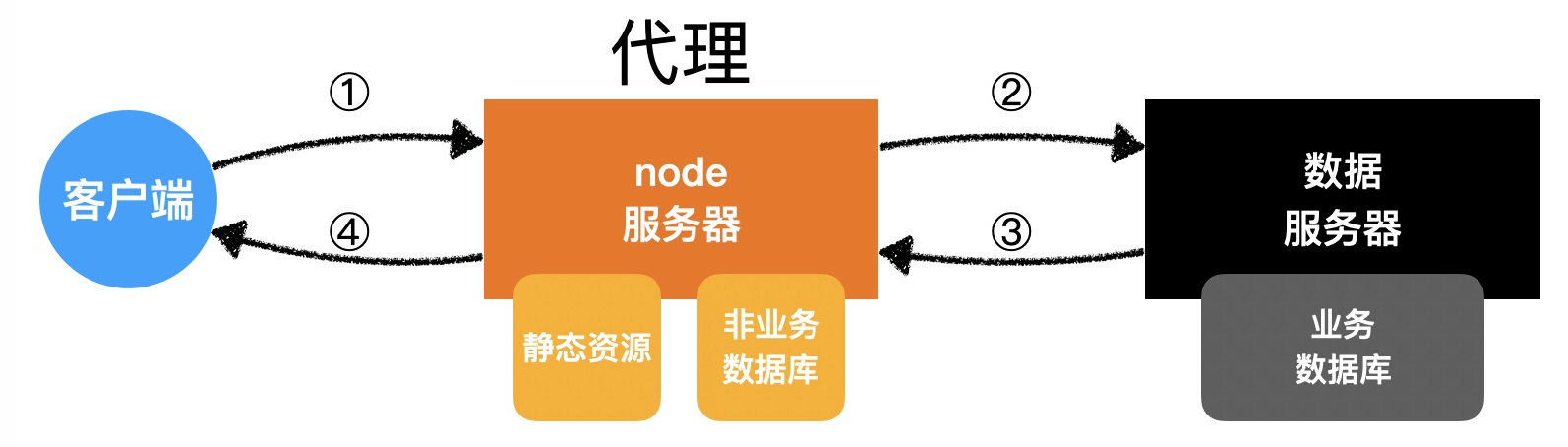
1)手写代理中间件
- 请求
http://localhost:9527/data/api/local - 代理到服务器
http://yuanjin.tech:5100/api/local
// routes/proxyMiddleware.js
const http = require("http");
module.exports = (req, res, next) => {
const context = "/data";
if (!req.path.startsWith(context)) {
// 不需要代理
next();
return;
}
// 需要代理
const path = req.path.substr(context.length);
// 创建代理请求对象 request
const request = http.request(
{
host: "yuanjin.tech",
port: 5100,
path: path,
method: req.method,
headers: req.headers,
},
(response) => {
// 代理响应对象 response
res.status(response.statusCode);
for (const key in response.headers) {
res.setHeader(key, response.headers[key]);
}
response.pipe(res);
},
);
req.pipe(request); // 把请求体写入到代理请求对象的请求体中
};
2)使用第三方中间件
- vue 中的代理配置使用的就是该中间件
const { createProxyMiddleware } = require("http-proxy-middleware");
// 不配置context,默认该服务器所有请求都会走代理
const context = "/data";
module.exports = createProxyMiddleware(context, {
target: "http://yuanjin.tech:5100",
pathRewrite: function (path, req) {
console.log(path.substr(context.length));
return path.substr(context.length);
},
});
22.场景 —— 模版引擎【扩展】
1)两种渲染方式
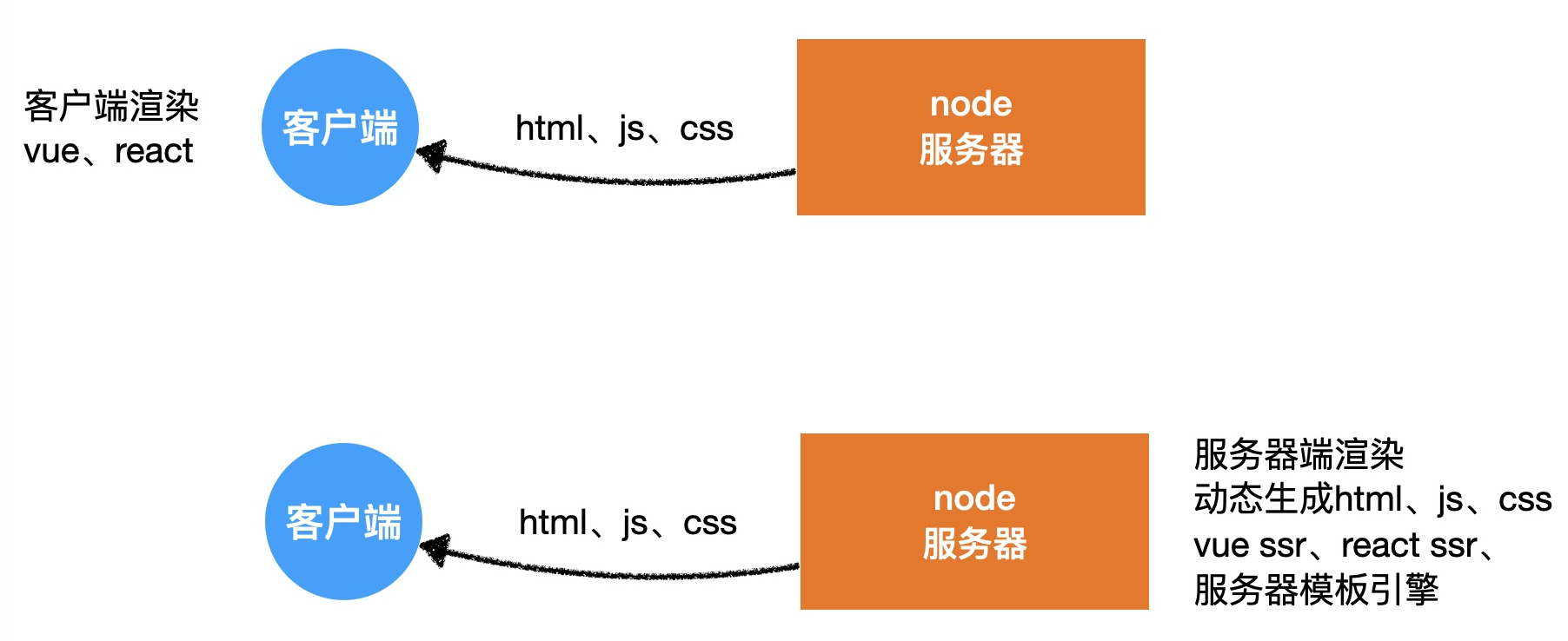
2)模板引擎
- 在静态内容中插入动态内容
- 常见模板引擎
- mustache(Vue)
- ejs
const ejs = require("ejs");
ejs
.renderFile("./test.ejs", {
number: Math.random(),
})
.then((result) => {
console.log(result);
});
const str = `
生成的数字是:<%= number %>
`;
const result = ejs.render(str, {
number: Math.random(),
});
console.log(result); // 0.31928499351079287
3)模板引擎生成学生数据
- 客户端请求
http://localhost:9527/student
<!-- routes/views/students.ejs -->
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<title>Document</title>
</head>
<body>
<h1>学生列表页</h1>
<p>学生总数: <%= total %> , 当前第<%= page %>页,每页<%= limit %>条数据</p>
<ul>
<% datas.forEach(stu => { %>
<li><%= stu.name %></li>
<% }) %>
</ul>
<a href="?page=<%=+page-1%>">上一页</a>
<a href="?page=<%=+page+1%>">下一页</a>
</body>
</html>
- 控制器 Controller 处理请求
- 向模板页面传递数据(模型 Model)到视图 View
- 模板响应请求
- 这个过程其实就是 MVC
// routes/controller/student.js
const express = require("express");
const router = express.Router();
const studentService = require("../../services/studentService");
router.get("/", async (req, res) => {
const page = req.query.page || 1;
const limit = req.query.limit || 10;
const sex = req.query.sex || -1;
const name = req.query.name || "";
// total datas
const result = await studentService.getStudents(page, limit, sex, name);
res.render("./students.ejs", {
...result,
page,
limit,
});
});
module.exports = router;
- 使用模板引擎
// routes/init.js
app.set("views", path.resolve(__dirname, "./views"));
app.use("/student", require("./controller/student"));
23.场景 —— 生成二维码
- 表示为字符串
1)矩阵点
- 通常是黑色或白色的小点
- 深色表示 1
- 白色表示 0
2)位置探测组
- 三个位于角落的嵌套矩形
- 用于定位二维码图片的方向
3)Version
- 1 ~ 40 的数字
- 数字越大,表示整个二维码的矩阵越大
- 1 表示
21 * 21 - 40 表示
177 * 177
- 1 表示
4)mode
- 字符编码方式
- 使用 ASCII 编码会占用过多字节
- 一个字符占一个字节(8bytes)
- Numeric
- 只编码数字
- Alphanumeric
- 可编码数字、字母
- Kanji
- 可编码中文、日文
- Byte
- 一个字符占一个字节(8bytes)
5)纠错等级
- L:Low
- M:Midium
- Q:Quartile
- H:High
- 纠错等级越高
- 冗余信息越多
- 能够表达的字符量越少
6)生成二维码
- 服务端生成
const QRCode = require("qrcode");
QRCode.toDataURL("https://duyi.ke.qq.com/?tuin=a5d48d54", (err, url) => {
if (err) {
console.log(err);
} else {
console.log(url);
}
});
- 客户端生成
<div id="divcode"></div>
<script src="https://cdn.bootcdn.net/ajax/libs/qrcodejs/1.0.0/qrcode.js"></script>
<script>
new QRCode(divcode, {
text: "http://yuanjin.tech",
width: 128,
height: 128,
colorDark: "blue",
colorLight: "#fff",
correctLevel: QRCode.CorrectLevel.H,
src: "./img/logo.jpg",
});
</script>
24.场景 —— 生成验证码
- 防止机器提交
1)类型
- 普通验证码
- 行为验证码
2)流程
- 获取验证码图片
- 客户端通过 img 元素的 src 地址获取验证码图片
- 服务器生成 随机图片
- 服务器保存随机图片中的文字
function refreshCaptcha() {
imgCaptcha.src = `/captcha?rad=${Math.random()}`;
}
imgCaptcha.onclick = refreshCaptcha;
document.querySelector("button").onclick = async function () {
const body = {
loginId: loginId.value,
loginPwd: loginPwd.value,
};
if (captchaArea.style.display !== "none") {
body.captcha = captcha.value;
}
const resp = await fetch("/api/admin/login", {
method: "POST",
headers: {
"content-type": "application/json",
},
body: JSON.stringify(body),
}).then((resp) => resp.json());
if (resp.code === 401) {
console.log("验证码错误");
captchaArea.style.display = "block";
refreshCaptcha();
} else if (resp.data) {
console.log("登录成功");
} else {
console.log("登录失败");
}
};
- 验证
- 服务器判断是否对验证码进行验证
- 验证客户端传递的验证码是否和服务器保存的一致
// routes/captchaMiddleware.js
const express = require("express");
var svgCaptcha = require("svg-captcha");
const router = express.Router();
router.get("/captcha", (req, res) => {
var captcha = svgCaptcha.create({
size: 6,
ignoreChars: "iIl10oO",
noise: 6,
color: true,
});
// 把验证码中的文本存放到session中
req.session.captcha = captcha.text.toLowerCase();
res.type("svg");
res.status(200).send(captcha.data);
});
function validateCaptcha(req, res, next) {
// 用户传递的验证码
const reqCaptcha = req.body.captcha ? req.body.captcha.toLowerCase() : "";
if (reqCaptcha !== req.session.captcha) {
// 验证码有问题
res.send({
code: 401,
msg: "验证码有问题",
});
} else {
next();
}
req.session.captcha = "";
}
function captchaHandler(req, res, next) {
// 如果session中没有访问记录
if (!req.session.records) {
req.session.records = [];
}
// 把这一次请求的访问时间记录下来
const now = new Date().getTime();
req.session.records.push(now);
// 如果在一小段时间中请求达到了一定的数量,就可能是机器
const duration = 10000;
const repeat = 3;
req.session.records = req.session.records.filter((time) => now - time <= duration);
if (req.session.records.length >= repeat || "captcha" in req.body) {
// 验证验证码
validateCaptcha(req, res, next);
} else {
next();
}
}
router.post("*", captchaHandler);
router.put("*", captchaHandler);
module.exports = router;
25.场景 —— 客户端缓存
- 在一个 C/S 结构中,最基本的缓存分为两种
- 客户端缓存
- 服务器缓存
1)缓存的基本原理
- 客户端缓存,将某一次的响应结果保存在客户端(如:浏览器)中
- 后续的请求仅需要从缓存中读取即可
- 极大地降低了服务器的处理压力
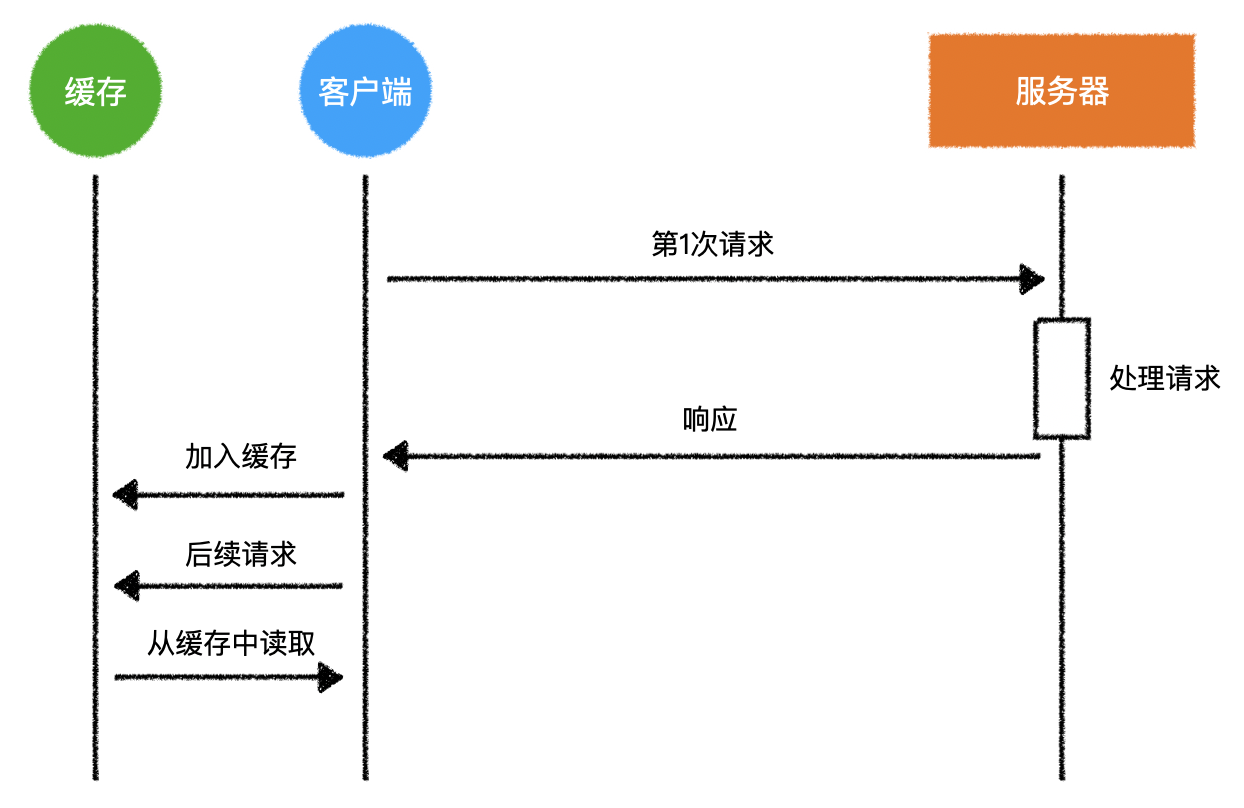
这只是一个简易的原理图,实际情况可能有差异
这里就涉及到缓存策略的问题
哪些资源需要加入到缓存,哪些不需要?
缓存的时间是多久呢?
如果服务器的资源有改动,客户端如何更新缓存呢?
如果缓存过期了,可是服务器上的资源并没有发生变动,又该如何处理呢?
.......
要回答这些问题,就必须要清楚
HTTP中关于缓存的协议
2)来自服务器的缓存指令
当客户端发出一个 GET 请求到服务器,服务器可能有以下的内心活动
你请求的这个资源,我很少会改动它,干脆你把它缓存起来吧,以后就不要来烦我了
- 为了表达这个美好的愿望,服务器在 响应头 中加入了以下内容
Cache-Control: max-age=3600 # 需要缓存该资源,缓存时间是 3600 秒(1 小时)
ETag: W/"121-171ca289ebf" # 资源编号
Date: Thu, 30 Apr 2020 12:39:56 GMT # 响应该资源的服务器格林威治时间
Last-Modified: Thu, 30 Apr 2020 08:16:31 GMT # 该资源上次修改的格林威治时间
- 如果客户端是其他应用程序
- 可能根本不会缓存任何东西
- 如果客户端是一个浏览器
- 浏览器把这次请求得到的响应体缓存到本地文件中
- 浏览器标记这次请求的请求方法和请求路径
- 浏览器标记这次缓存的时间是 3600 秒
- 浏览器记录服务器的响应时间是格林威治时间
2020-04-30 12:39:56 - 浏览器记录服务器给予的资源编号
W/"121-171ca289ebf" - 浏览器记录资源的上一次修改时间是格林威治时间
2020-04-30 08:16:31
- 这一次的记录非常重要,为以后浏览器要不要去请求服务器提供了各种依据
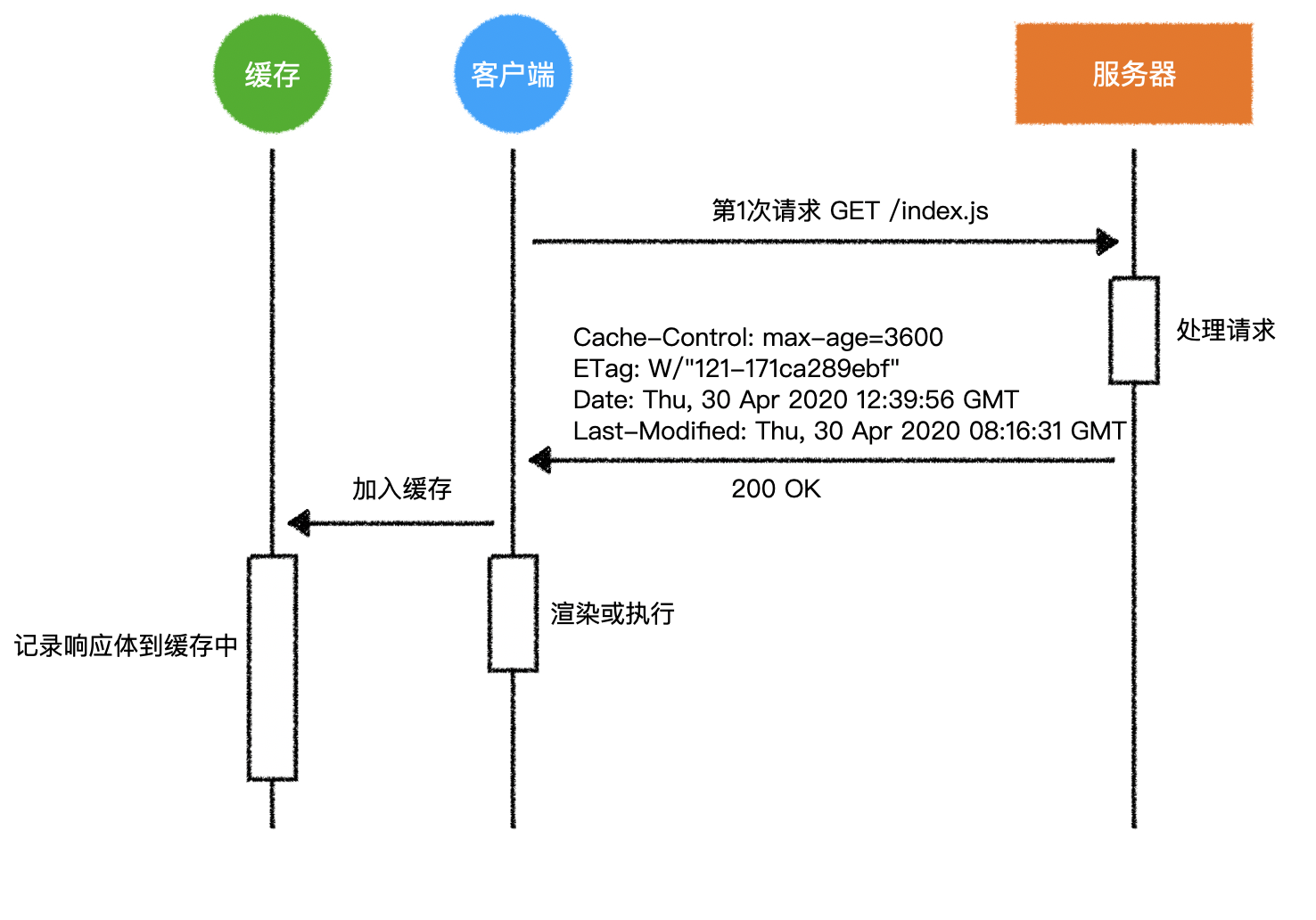
3)来自客户端的缓存指令
- 当客户端再次请求
GET /index.js时 - 会有一个决策过程,到缓存中去寻找是否有缓存的资源【缓存策略】
- 缓存中是否有匹配的请求方法和路径
- 如果有,该缓存资源是否还有效
- 以上两个验证会导致浏览器产生不同的行为
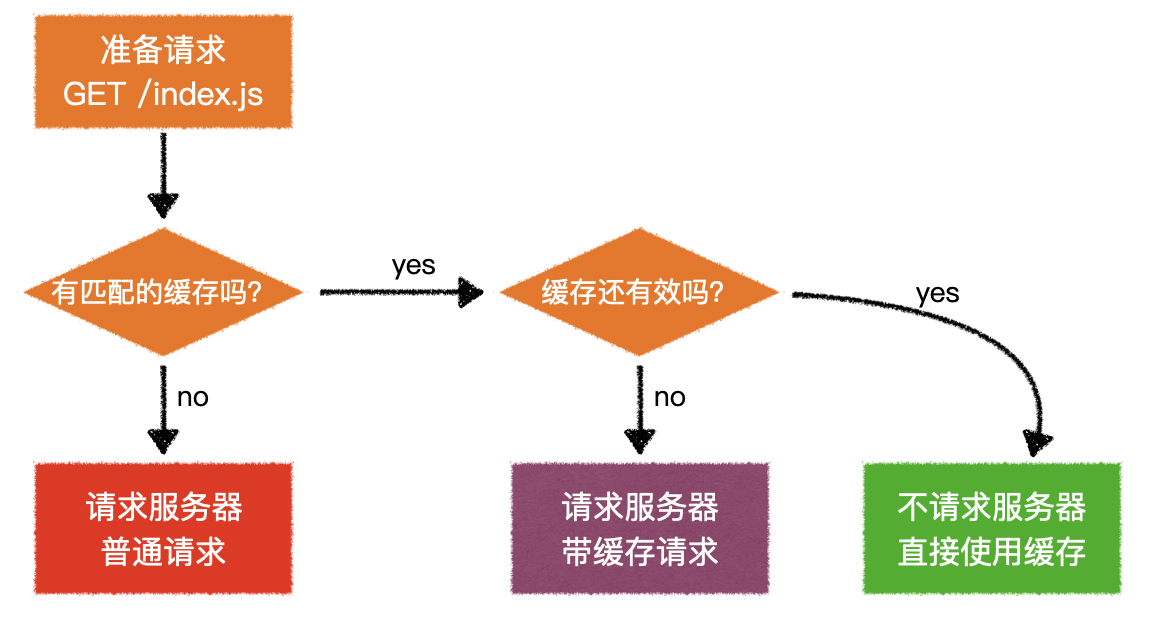
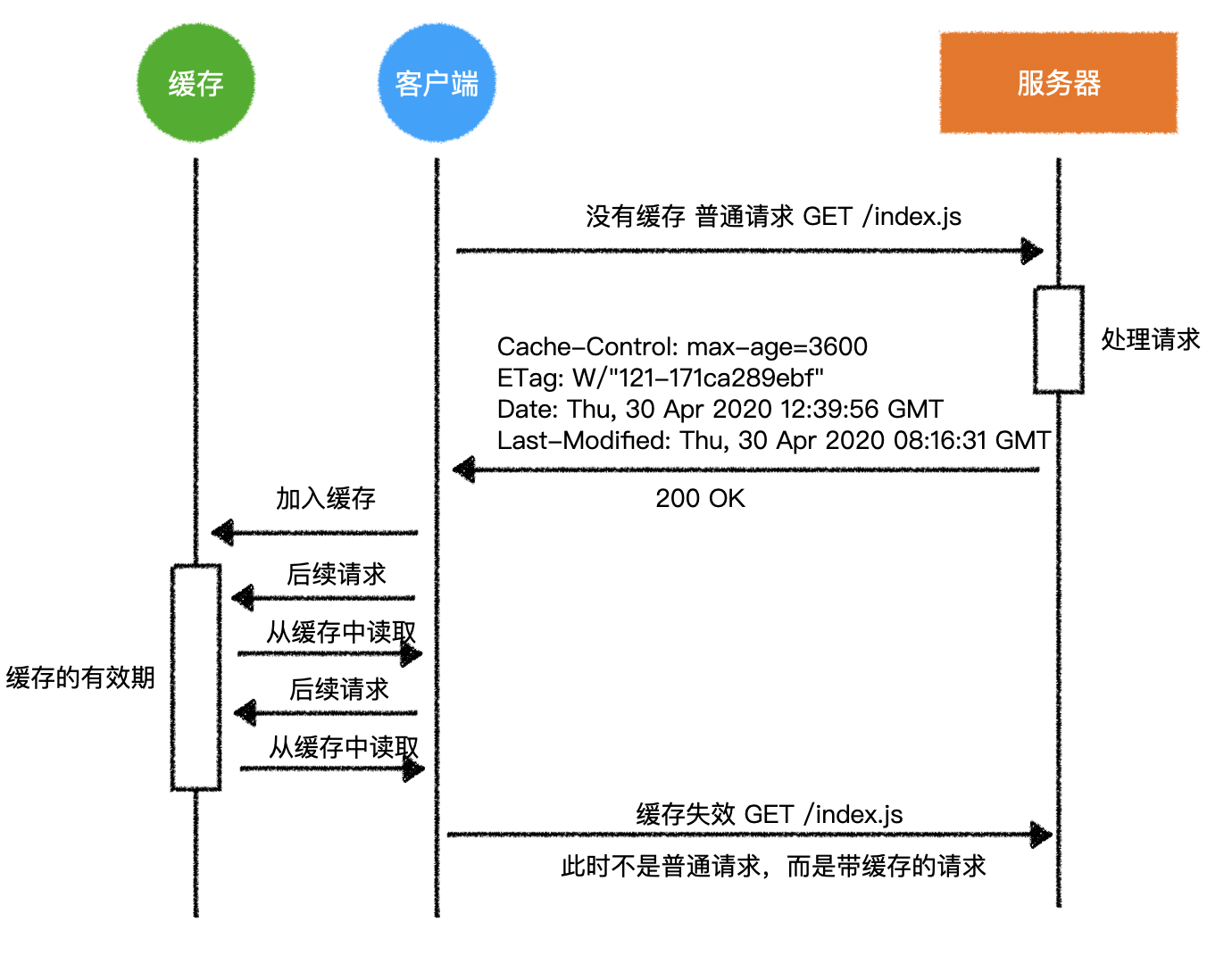
- 验证是否有匹配的缓存
- 只需要验证当前的请求方法
GET和当前的请求路径/index.js是否有对应的缓存存在即可 - 如果没有,就直接请求服务器,和第一次请求服务器时一样
- 只需要验证当前的请求方法
- 关键在于 验证缓存是否有效
max-age + Date得到一个过期时间,看看这个过期时间是否大于当前时间- 如果是,则表示缓存还没有过期,仍然有效
- 如果不是,则表示缓存失效
a)缓存有效
- 当浏览器发现缓存有效时,完全不会请求服务器,直接使用缓存即可得到结果
- 此时,如果断开网络,会发现资源仍然可用,极大地降低服务器压力
- 但当服务器更改了资源后,浏览器不知道,只要缓存有效,就会直接使用缓存
b)缓存无效
- 当浏览器发现缓存已经过期,并不会直接把缓存删除
- 而是再次请求服务器确认这个缓存能否继续使用【缓存确认】
- 于是,浏览器向服务器发出了一个 带缓存的请求
- 即加入了以下的请求头
If-Modified-Since: Thu, 30 Apr 2020 08:16:31 GMT # 该资源上次修改的格林威治时间
If-None-Match: W/"121-171ca289ebf" # 该资源的编号,变动则缓存无效
- 之所以要发两个信息,是为了兼容不同的服务器
- 有些服务器只认
If-Modified-Since - 有些服务器只认
If-None-Match - 有些服务器两个都认
- 有些服务器只认
- 目前的很多服务器,只要发现
If-None-Match存在,就不会看If-Modified-Since If-Modified-Since是HTTP 1.0版本的规范If-None-Match是HTTP 1.1的规范- 服务器可能会产生两个情况
- 缓存已经失效
- 服务器再次给予一个正常的响应:响应码 200,带响应体
- 同时可以附带上新的缓存指令
- 客户端就会重新缓存新的内容
- 缓存仍然有效
- 服务器给予一个简单的响应:响应码
304 Not Modified,无响应体 - 响应头带上新的缓存指令
- 服务器给予一个简单的响应:响应码
- 缓存已经失效
相当于告诉客户端
你的缓存资源仍然可用,我给你一个新的缓存时间,你那边更新一下就可以了
- 可以最大程度的减少网络传输
- 因为如果资源还有效,服务器就不会传输消息体
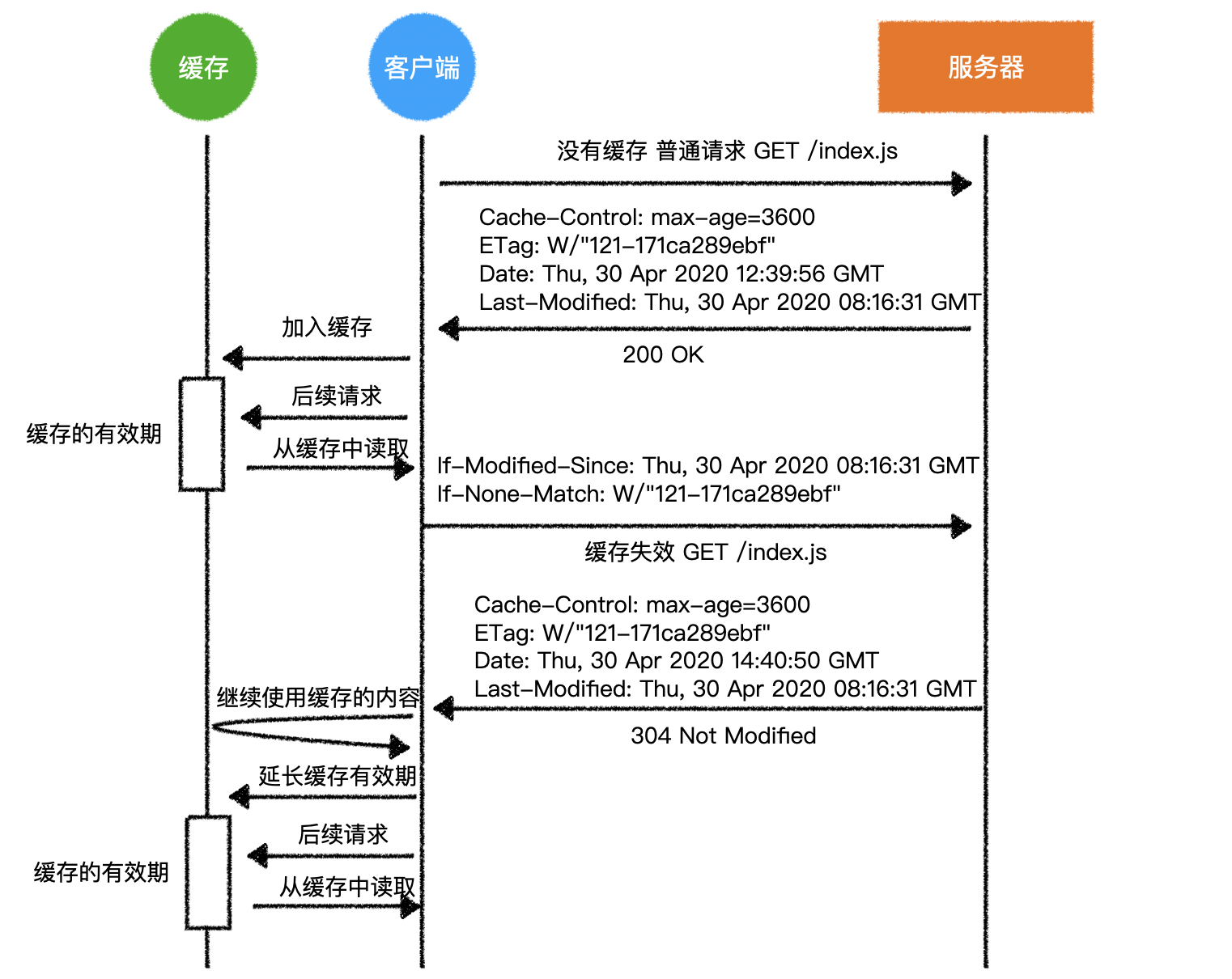
4)Cache-Control
- 服务器向客户端响应的一个消息头
- 提供了一个
max-age用于指定缓存时间 - 还可以设置下面一个或多个值
| 属性 | 含义 | 说明 |
|---|---|---|
public | 指示服务器资源是公开的 | 如:有一个页面资源,所有人看到的都是一样的 这个值对于浏览器而言没有什么意义,但可能在某些场景可能有用 本着「我告知,你随意」的原则, http 协议中很多时候都是客户端或服务器告诉另一端详细的信息,至于另一端用不用,完全看它自己 |
private | 指示服务器资源是私有的 | 如:有一个页面资源,每个用户看到的都不一样 这个值对于浏览器而言没有什么意义,但可能在某些场景可能有用 本着「我告知,你随意」的原则, http 协议中很多时候都是客户端或服务器告诉另一端详细的信息,至于另一端用不用,完全看它自己 |
no-cache | 告知客户端可以缓存这个资源,但不要 直接 使用它 | 缓存之后,后续的每一次请求都需要附带缓存指令,让服务器验证这个资源有没有过期 |
no-store | 告知客户端不要对这个资源做任何的缓存,之后的每一次请求都按照正常的普通请求进行 | 若设置了这个值,浏览器将不会对该资源做出任何的缓存处理 |
max-age |
Cache-Control: public, max-age=3600 # 表示这是一个公开资源,请缓存1个小时
5)Expire
- 在
HTTP1.0版本中,是通过Expire响应头来指定过期时间点的 HTTP1.1版本更改为通过Cache-Control的max-age来记录
Expire: Thu, 30 Apr 2020 23:38:38 GMT
6)记录缓存时的有效期
- 浏览器会按照服务器响应头的要求,自动记录缓存到本地文件,并设置各种相关信息
- 在这些信息中, 有效期 尤为关键,决定了这个缓存可以使用多久
- 浏览器会根据服务器不同的响应情况,设置不同的有效期
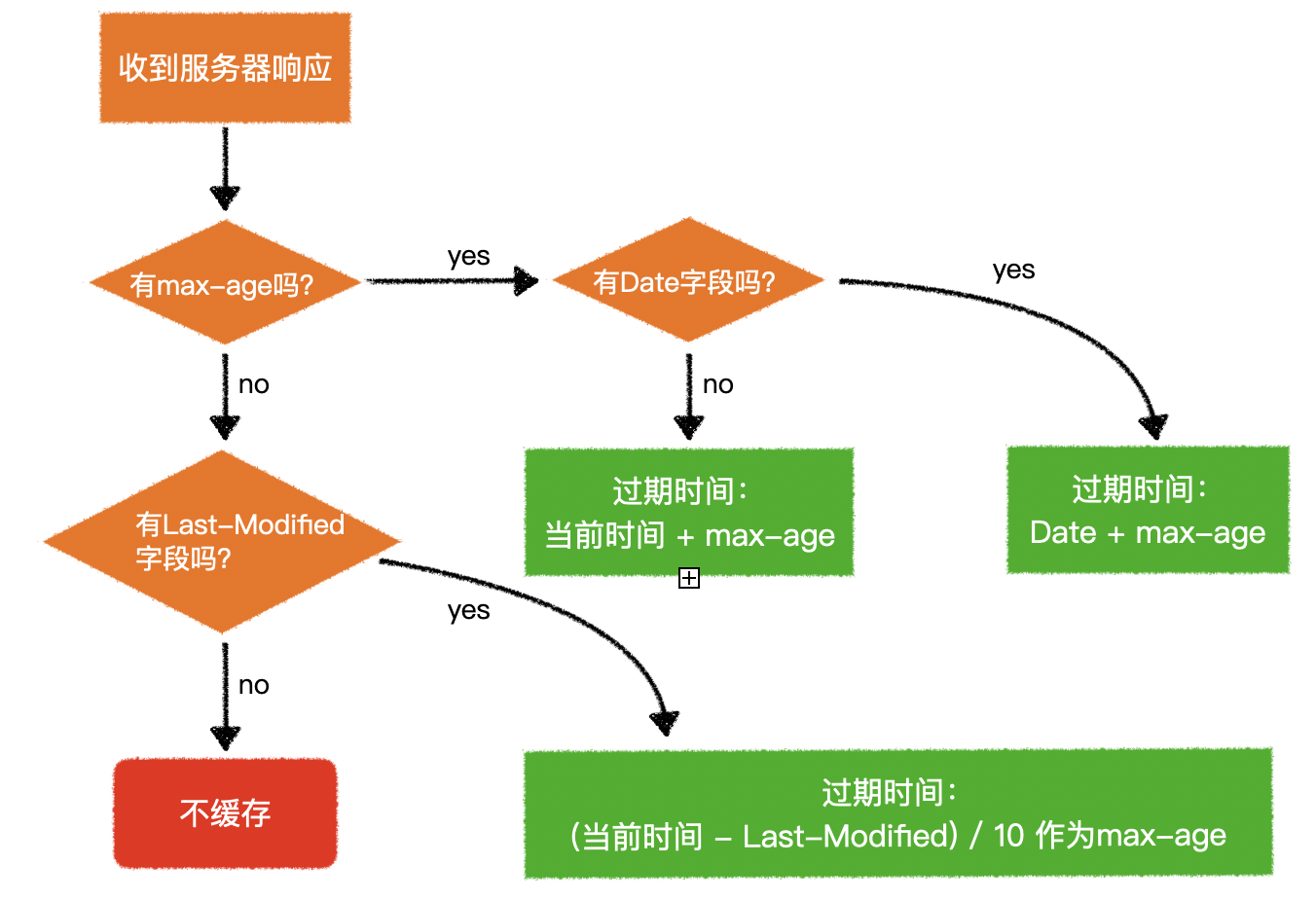
- 如:当
max-age设置为 0 时,缓存立即过期- 虽然立即过期,但缓存仍然被记录下来
- 后续的请求通过缓存指令发送到服务器,来确认资源是否被更改
- 因此
Cache-Control: max-age=0类似于Cache-Control: no-cache
7)Pragma
HTTP1.0版本的消息头- 当该消息头出现在请求中时,是向服务器表达:不要考虑任何缓存,返回一个正常的结果
- 在
HTTP1.1版本中,可以在 请求头 中加入Cache-Control: no-cache实现 - 在 Chrome 浏览器中调试时,如果勾选了
Disable Cache,则发送的请求中会附带该信息
8)Vary
- 有时是否有缓存,不仅仅是判断请求方法和请求路径是否匹配,可能还要判断头部信息是否匹配
- 此时,就可以使用
Vary字段来指定要区分的消息头 - 如:当使用
GET /personal.html请求服务器时,请求头中 cookie 的值不一样,得到的页面也不一样- 如果还按照之前的做法,仅仅匹配请求方法和请求路径,如果 cookie 变动,可能得到的仍然是之前的页面
- 正确的做法如下
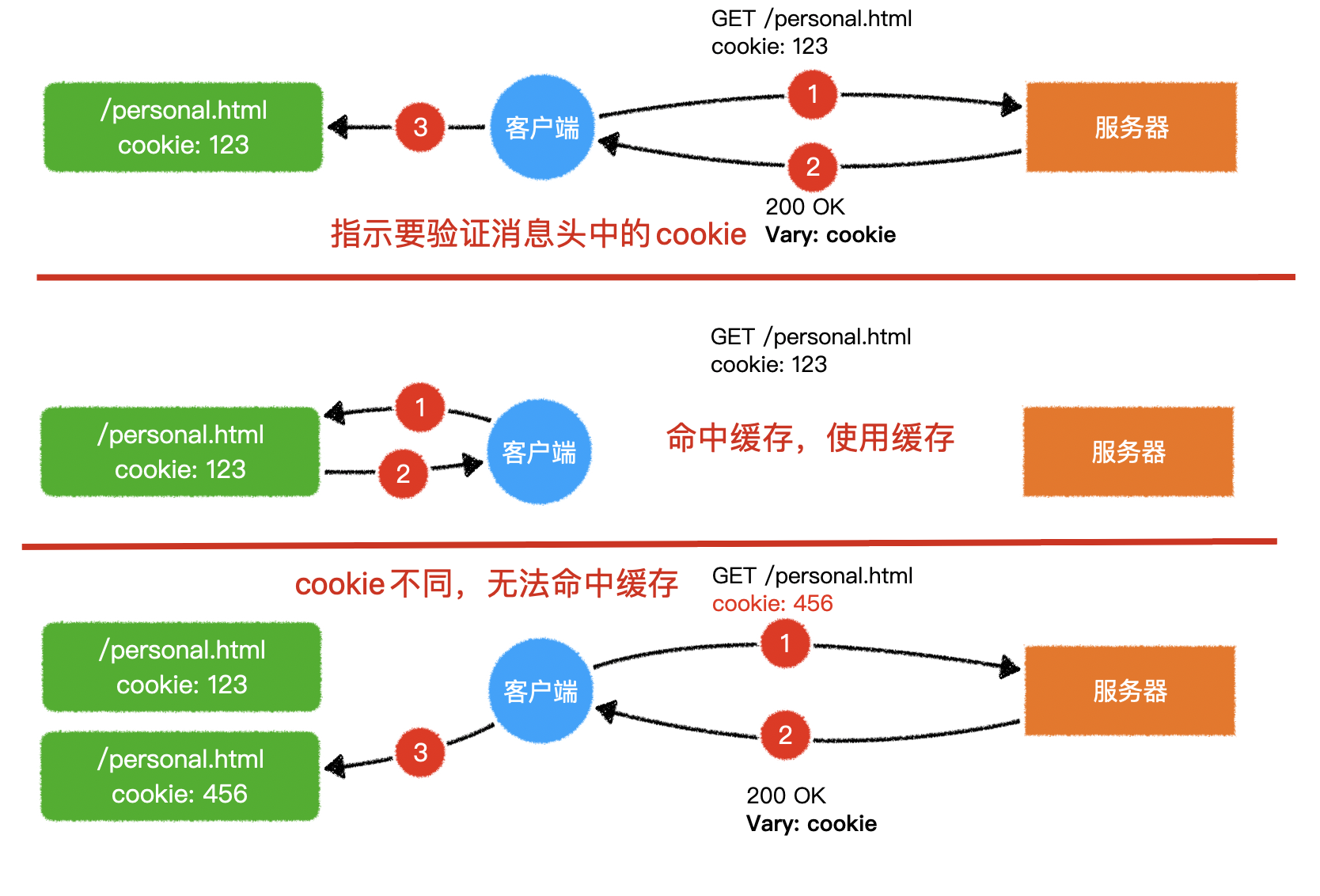
9)使用版本号或 hash
- vue 或其他基于 webpack 搭建的工程中,打包的结果很多文件名类似于
app.68297cd8.css - 文件的中间部分使用了
hash值 - 可以让客户端长时间地缓存该文件,减轻服务器的压力
- 当文件改动后,文件 hash 值也会随之而变,如:
app.446fccb8.css - 客户端要请求新的文件时,就会发现路径从
app.68297cd8.css变成了app.446fccb8.css- 由于之前的缓存路径无法匹配到,因此就会发送新的请求来获取新资源
- 当文件改动后,文件 hash 值也会随之而变,如:
- 在构建工具出现前,通常是在资源路径后面加入版本号来获取新版本的文件
- 如:页面中引入了一个 css 资源
app.css
- 如:页面中引入了一个 css 资源
<link href="/app.css?v=1.0.0" />
- 缓存的路径是
/app.css?v=1.0.0 - 当服务器的版本发生变化时,可以给予新的版本号,让 html 中的路径发生变动
<link href="/app.css?v=1.0.1" />
- 由于新的路径无法命中缓存,于是浏览器就会发送新的普通请求来获取这个资源
// routes/init.js
// 映射public目录中的静态资源
const path = require("path");
const staticRoot = path.resolve(__dirname, "../public");
// app.use(express.static(staticRoot));
app.use(
express.static(staticRoot, {
setHeaders(res, path) {
if (!path.endsWith(".html")) {
res.header("Cache-Control", `max-age=${3600 * 24 * 365 * 100}`);
}
},
}),
);
10)总结
- 服务器无法知道客户端到底有没有像浏览器那样缓存文件
- 只管根据请求的情况来决定如何响应
- 很多后端语言搭建的服务器都会自带默认缓存规则,支持不同程度的修改
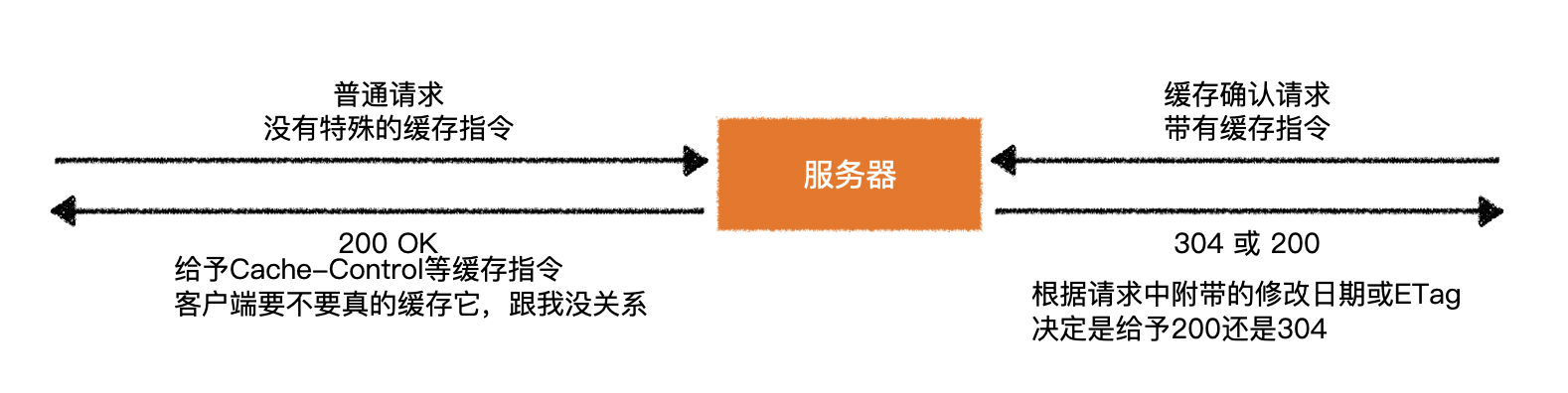
- 浏览器在发出请求时会判断要不要使用缓存
- 当收到服务器响应时,会自动根据缓存指令进行处理
26.场景 —— 富文本框
- 一个可以被编辑的 div
- 编辑后得到的结果是一个 html 字符串
1)模式 1
- 用户点击上传图片,选择图片
- 富文本框将图片信息发送到服务器(配置接口)
- 服务器会返回一个图片的 url 路径
- 富文本框生成一个 img 元素,使用该 url 路径插入到富文本框内部
2)模式 2
- 用户点击上传图片,选择图片
- 在客户端生成图片的 base64 格式
- 富文本框生成一个 img 元素,使用该 base64 路径插入到富文本框内部
- 图片不会上传到服务器
(五)补充
1.WebSocket 原理
1)Socket
相关信息
- 抽象接口,基于 TCP/IP 协议
- 浏览器没有实现该接口,开发者无法使用
- 客户端连接服务器(TCP / IP),三次握手,建立了连接通道
- 客户端和服务器通过 socket 接口发送消息和接收消息
- 任何一端在任何时候,都可以向另一端发送任何消息
- 有一端断开了,通道销毁
2)HTTP
相关信息
在 Socket 基础上形成
- 客户端连接服务器(TCP / IP),三次握手,建立了连接通道
- 客户端发送一个 HTTP 格式的消息(消息头、消息体),服务器响应 HTTP 格式的消息(消息头 消息体)
- 客户端主动,服务器被动
- 如果客户端请求头携带了
Connection: keep-alive(长连接),则可以多次发送消息再进入下一步- 此时服务器不会主动断开,客户端也不会立马断开
- 客户端或服务器断开,通道销毁
3)实时性
- 遇到需要实时响应消息的场景,HTTP 处理比较麻烦
- 如,股票信息实时变化,需要服务器持续返回响应数据
- HTTP 有两种方式解决
- 轮询
- 客户端开启定时器,间隔发送请求
- 会导致建立许多没必要的连接
- 长连接
- 请求头携带
Connection: keep-alive - 服务器遇到长连接会开启线程,有额外开销
- 优于轮询
- 请求头携带
- 轮询
4)WebSocket
相关信息
- 专门用于解决实时传输的问题
- 基于 socket 接口
- 客户端连接服务器(TCP / IP),三次握手,建立了连接通道
- 客户端发送一个 HTTP 格式的消息(特殊格式),服务器也响应一个 HTTP 格式的消息(特殊格式)
- 又叫 HTTP 握手
- 双发自由通信,通信格式按照 WebSocket 的要求进行
- 客户端或服务器断开,通道销毁
5)使用 WebSocket 通信
- 通常都是使用第三方库 socket.io
a)客户端(浏览器)
// 创建一个websocket,同时,发送连接到服务器
const ws = new WebSocket("ws://localhost:5008");
// 建立连接,HTTP 握手完成后触发
ws.onopen = function () {
console.log("连接已建立");
};
// 接收消息
ws.onmessage = function (e) {
console.log("来自服务器的数据", e.data);
};
// 连接通道关闭时触发
ws.onclose = function () {
console.log("通道关闭");
};
// 发送消息
document.querySelector("button").onclick = function () {
ws.send("123");
};
// 客户端主动断开连接,需要时断开
// ws.close();
- 请求头携带了以下关键信息
- 服务器收到消息后确认使用 WebSocket 协议通信
- key 是浏览器随机生成的
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Accept: [key]
b)服务器
const net = require("net");
const server = net.createServer((socket) => {
console.log("收到客户端的连接");
// 建立连接后立马发送消息,所以只接收一次即可
socket.once("data", (chunk) => {
const httpContent = chunk.toString("utf-8");
// 将请求头分割为对象格式
let parts = httpContent.split("\r\n");
parts.shift(); // 去掉首行GET / /HTTP1.1
parts = parts
.filter((s) => s)
.map((s) => {
const i = s.indexOf(":");
return [s.substr(0, i), s.substr(i + 1).trim()];
});
const headers = Object.fromEntries(parts);
// 获取浏览器随机生成的key
const crypto = require("crypto");
const hash = crypto.createHash("sha1");
hash.update(headers["Sec-WebSocket-Key"] + "258EAFA5-E914-47DA-95CA-C5AB0DC85B11");
const key = hash.digest("base64");
// 服务器响应请求,101切换协议
socket.write(`HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: ${key}
`);
// 接收客户端后续的请求数据
socket.on("data", (chunk) => {
console.log(chunk);
});
});
});
server.listen(5008);
6)服务端的握手响应
- 在 WebSocket 的 HTTP 握手阶段,服务器响应头中需要包含如下内容
Connection: Upgrade
Upgrade: websocket
Sec-WebSocket-Accept: [key]
- 其中
Sec-WebSocket-Accept来自于以下算法
base64(sha1(Sec - WebSocket - Key) + "258EAFA5-E914-47DA-95CA-C5AB0DC85B11");
- 在 Node 中可以使用以下代码获得
const crypto = require("crypto");
const hash = crypto.createHash("sha1");
hash.update(requestKey + "258EAFA5-E914-47DA-95CA-C5AB0DC85B11");
const key = hash.digest("base64");
requestKey来自于客户端请求头中的Sec-WebSocket-Key
2.socket.io
- 适用于多种客户端
- 底层基于 WebSocket,但是封装的很深
1)服务器
const express = require("express");
const socketIO = require("socket.io");
const http = require("http");
const path = require("path");
// 搭建express服务器
const app = express();
const server = http.createServer(app);
app.use(express.static(path.resolve(__dirname, "public")));
// 提供websocket服务
const io = socketIO(server);
// 当有一个新的客户端连接到服务器,连接成功后触发
io.on("connection", (socket) => {
console.log("新的客户端连接进来了");
// 监听客户端的msg消息
socket.on("msg", (chunk) => {
console.log(chunk.toString("utf-8"));
});
// 每隔两秒钟,发送一个消息给客户端,事件名为test
const timer = setInterval(function () {
socket.emit("test", "test message from server");
}, 2000);
// 连接断开后触发
socket.on("disconnect", () => {
clearInterval(timer);
console.log("closed");
});
});
// 监听端口
server.listen(5008, () => {
console.log("server listening on 5008");
});
2)客户端
<button>发送数据到服务器</button>
<script src="https://cdn.bootcdn.net/ajax/libs/socket.io/2.3.0/socket.io.js"></script>
<script>
// 参数可传服务器地址,不传使用当前页面地址
// const socket = io.connect("http://localhost:5008");
const socket = io.connect();
// 发送消息到服务器,事件名为msg
document.querySelector("button").onclick = function () {
socket.emit("msg", "msg from client");
};
// 监听服务器发送的消息,事件名为test
socket.on("test", (chunk) => {
console.log(chunk);
});
// 连接断开后触发
socket.on("disconnect", () => {
console.log("closed");
});
</script>
3.在线聊天室
1)客户端发送的消息格式
- 获取当前所有在线用户
- 消息名称:users
- 消息内容:无
- 登录
- 消息名称:login
- 消息内容:用户名
- 消息
- 消息名称:msg
- 消息内容:
{to:"目标用户名,null表示所有人", content:"消息内容"}
2)服务器发送的消息格式
- 获取当前所有在线用户
- 消息名称:users
- 消息内容:用户数组
- 登录
- 消息名称:login
- 消息内容:true 或 false
- true 表示登录成功
- false 表示登录失败(昵称已存在)
- 新用户进入
- 消息名称:userin
- 消息内容:用户名
- 用户离开
- 消息名称:userout
- 消息内容:用户名
- 新消息来了
- 消息名称:new msg
- 消息内容:
{from:"用户名", content:"消息内容", to:"接收消息的人,如果是null,表示所有人"}
3)搭建服务器
const express = require("express");
const http = require("http");
const path = require("path");
// express
const app = express();
const server = http.createServer(app);
app.use(express.static(path.resolve(__dirname, "public")));
// websocket
require("./chatServer")(server);
// 监听端口
server.listen(5008, () => {
console.log("server listening on 5008");
});
4)客户端
const socket = io.connect();
/**
* 客户端发送消息给服务器
*/
// 进入聊天室
page.onLogin = function (username) {
socket.emit("login", username);
};
// 监听发送消息
page.onSendMsg = function (me, msg, to) {
socket.emit("msg", {
to,
content: msg,
});
page.addMsg(me, msg, to);
page.clearInput();
};
/**
* 客户端监听服务器消息
*/
socket.on("login", (result) => {
if (result) {
page.intoChatRoom();
socket.emit("users", "");
} else {
alert("昵称不可用,请更换昵称");
}
});
// 渲染成员列表
socket.on("users", (users) => {
page.initChatRoom();
for (const u of users) {
page.addUser(u);
}
});
// 用户进入
socket.on("userin", (username) => {
page.addUser(username);
});
// 用户离开
socket.on("userout", (username) => {
page.removeUser(username);
});
// 收到新消息
socket.on("new msg", (result) => {
page.addMsg(result.from, result.content, result.to);
});
5)服务器
const socketIO = require("socket.io");
// 用户数组,模拟数据库
let users = [];
module.exports = function (server) {
const io = socketIO(server);
io.on("connection", (socket) => {
// 当前用户名
let curUser = "";
// 监听客户端消息
socket.on("login", (data) => {
if (data === "所有人" || users.filter((u) => u.username === data).length > 0) {
// 昵称不可用
socket.emit("login", false);
} else {
// 昵称可用
users.push({
username: data,
socket,
});
curUser = data;
socket.emit("login", true);
// 新用户进入了
socket.broadcast.emit("userin", data);
}
});
// 返回当前聊天室所有成员
socket.on("users", () => {
const arr = users.map((u) => u.username);
socket.emit("users", arr);
});
// 发送消息
socket.on("msg", (data) => {
if (data.to) {
// 发送给指定的用户
const us = users.filter((u) => u.username === data.to);
const u = us[0];
u.socket.emit("new msg", {
from: curUser,
content: data.content,
to: data.to,
});
} else {
// 发送给所有人
socket.broadcast.emit("new msg", {
from: curUser,
content: data.content,
to: data.to,
});
}
});
// 客户端断开(用户离开)
socket.on("disconnect", () => {
socket.broadcast.emit("userout", curUser);
users = users.filter((u) => u.username !== curUser);
});
});
};
4.CSRF 攻击和防御
- 用户访问了恶意网站后才会被攻击
1)CSRF 特点和原理
- CSRF,Cross Site Request Forgery,跨站请求伪造
- 本质:恶意网站把正常用户作为媒介,通过模拟正常用户的操作,攻击其登录过的站点
- 用户访问正常站点,登录后,获取到正常站点的令牌,以 cookie 的形式保存
- 用户访问恶意站点,恶意站点通过某种形式去请求正常站点(请求伪造),迫使正常用户把令牌传递到正常站点,完成攻击
<img src="http://alipay.com/api/transfer?target=yuanjin&money=1000" />
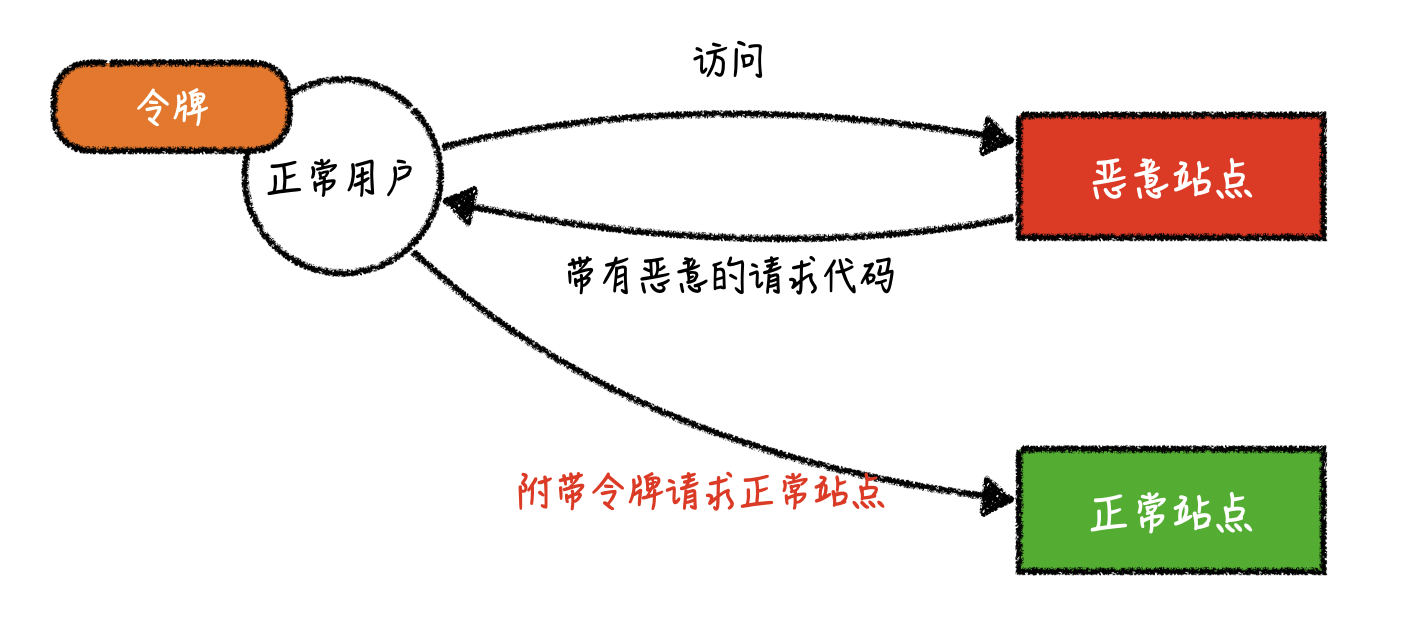
2)防御
a)cookie 的 SameSite
- 现在很多浏览器都支持 禁止跨域附带的 cookie
- 只需要把 cookie 设置的
SameSite设置为Strict即可 - 这种方法非常简单,极其有效,但前提条件是:用户不能使用太旧的浏览器
| SamSite 取值 | 说明 |
|---|---|
| Strict | 严格,所有跨站请求都不附带 cookie,有时会导致用户体验不好 |
| Lax | 宽松,所有跨站的超链接、GET 请求的表单、预加载连接时会发送 cookie,其他情况不发送 |
| None | 无限制 |
b)验证 referer 和 Origin
- 页面中的二次请求都会附带 referer 或 Origin 请求头
- 向服务器表示该请求来自于哪个源或页面,服务器可以通过这个头进行验证
- 但某些浏览器的 referer 是可以被用户禁止的,尽管这种情况极少
c)使用非 cookie 令牌
- 要求每次请求需要在请求体或请求头中附带 token
- 请求的时候:
authorization: token
d)验证码
- 要求每个要防止 CSRF 的请求都必须要附带验证码
- 容易把正常的用户逼疯
e)表单随机数
- 服务端渲染时,生成一个随机数
- 客户端提交时要提交这个随机数,然后服务器端进行对比
- 该随机数是一次性的
流程
- 客户端请求服务器,请求添加学生的页面,传递 cookie
- 服务器生成一个随机数,放到 session 中
- 生成页面时,表单中加入一个隐藏的表单域
<input type="hidden" name="hash" value="<%=session['key'] %>"> - 填写好信息后,提交表单,会自动提交隐藏的随机数
- 服务器拿到 cookie,判断是否登录过
- 服务器对比提交过来的随机数和之前的随机数是否一致
- 服务器清除掉 session 中的随机数
f)二次验证
- 当做出敏感操作时,进行二次验证
5.XSS 攻击和防御
- XSS,Cross Site Scripting,跨站脚本攻击
- 为了和 CSS 区分,不使用该缩写
- 用户正常访问网站时也会被攻击
- 网站安全性没有做好
- 通常发生在服务端渲染网站
1)存储型 XSS
a)原理
- 恶意用户提交了恶意内容到服务器
- 服务器没有识别,保存了恶意内容到数据库
- 正常用户访问服务器
- 服务器在不知情的情况下,给予了之前的恶意内容,让正常用户遭到攻击
b)防御
- 关键在于不要把恶意内容保存到数据库
- Node 可以使用第三方库中间件
- xss
const xss = require("xss");
const myxss = new xss.FilterXSS({
onTagAttr(tag, name, value, isWhiteAttr) {
if (name === "style") {
return `style="${value}"`;
}
},
});
app.use((req, res, next) => {
for (const key in req.body) {
const value = req.body[key];
req.body[key] = myxss.process(value);
}
next();
});
2)反射型 XSS
- 恶意用户分享了一个正常网站的链接,链接中带有恶意内容
- 正常用户点击了该链接
- 服务器在不知情的情况,把链接的恶意内容读取了出来,放进了页面中,让正常用户遭到攻击
3)DOM 型 XSS
a)原理
- 恶意用户通过任何方式,向服务器中注入了一些 DOM 元素,从而影响了服务器的 DOM 结构
- 普通用户访问时,运行的是服务器的正常 js 代码
b)防御
- 模板引擎渲染时使用
<%= %>让浏览器自动编码- 如果使用
<%- %>浏览器不会编码
- 如果使用
- 不要信任任何 DOM 元素
6.NodeJS 组成原理
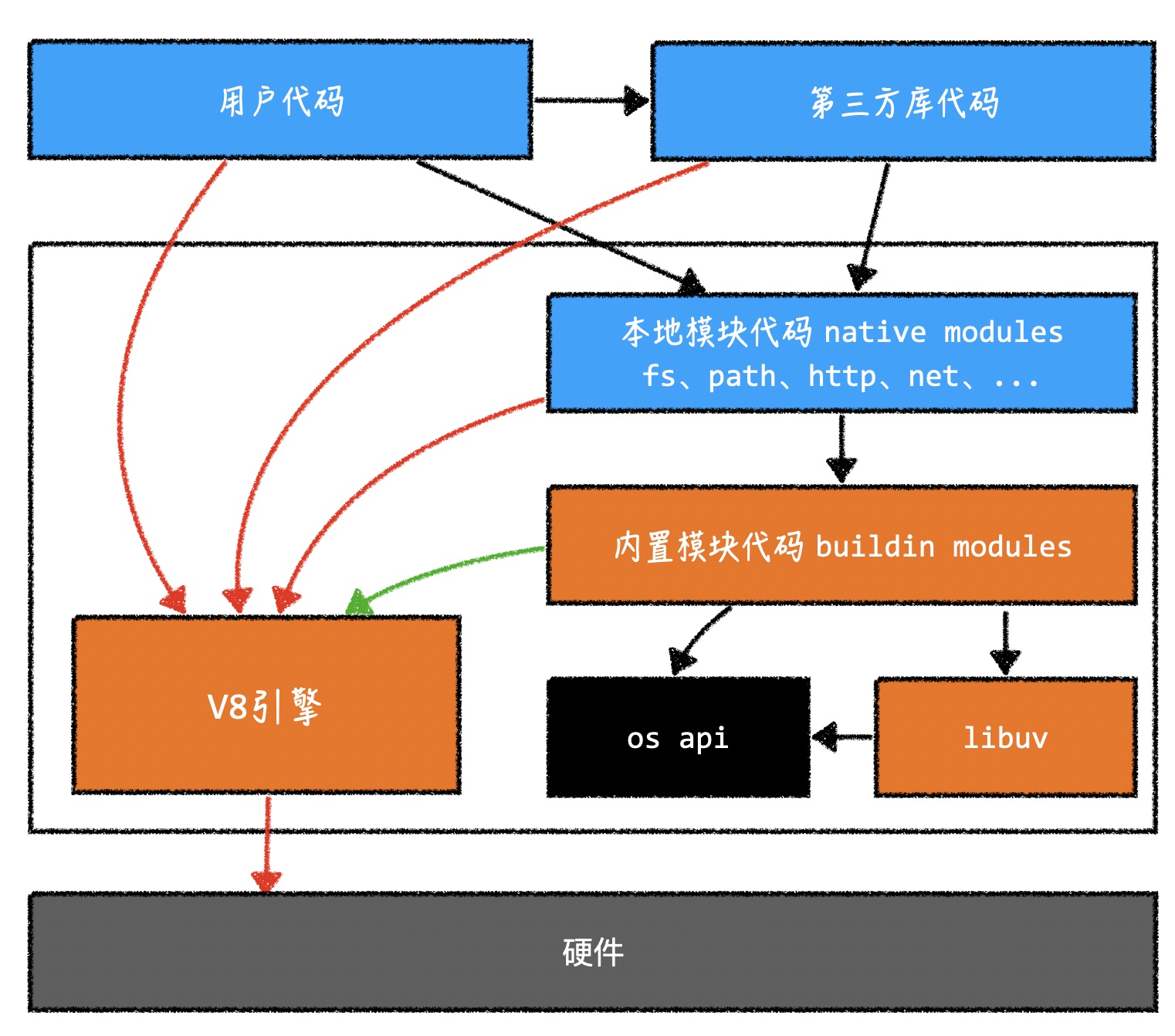
- 黑色边框:Node
- 蓝色:JS 代码
- 橙色:C/C++代码
- libuv:是一个 C/C++的库
- Node 的事件循环是通过 libuv 实现的
- 红色箭头:代码交付
1)用户代码
- JS 代码
- 开发者编写的
2)第三方库
- 大部分仍然是 JS 代码
- 由其他开发者编写
3)本地模块代码
- JS 代码
4)V8 引擎
- C/C++代码
- 作用:把 JS 代码解释成为机器码
- 可以通过 V8 引擎的某种机制,扩展其功能
gyp
- V8 引擎的扩展和对扩展的编译是通过 gyp 工具
- 某些第三方库需要使用
node-gyp工具进行构建- 需要先安装
node-gyp构建工具
- 需要先安装
7.进程和线程
1)进程
- 一个应用程序,总是通过操作系统启动的,当操作系统启动一个应用程序时,会给其分配一个进程
- 一个进程拥有 独立的、可伸缩的 内存空间,原则上不受其他进程干扰
- 进程之间是可以通信的,只要两个进程双方遵守一定的协议,如:IPC、HTTP
警告
CPU 在不同的进程之间切换执行
- 虽然一个应用程序在启动时只有一个进程,但在运行的过程中,可以开启新的进程,进程之间仍然保持相对独立
- 如果一个进程是 直接由操作系统开启,则叫做主进程
- 如果一个进程 B 是由进程 A 开启,则 A 是 B 的父进程,B 是 A 的子进程
- 子进程会继承父进程的一些信息,但仍然保持相对独立
// Node 中开启子进程
const childProcess = require("child_process"); // 导入内置模块
/**
* 回调函数中可以获取子进程的标准输出,这种数据交互是通过IPC完成的,nodejs已经完成了处理
* @param {*} err 开启进程过程中发生的错误
* @param {*} out 子进程输出的正常内容
* @param {*} stdErr 子进程输出的错误内容
*/
childProcess.exec(在子进程运行的命令, (err, out, stdErr) => {
// 子进程发生任何的错误,绝不会影响到父进程,它们的内存空间是完全隔离的
});
// 过去,Node 没有提供给用户创建线程的接口,只能使用进程的方式
// 过去,Node 还提供了 cluster 模块,通过另一种模式来创建进程
// 现在,Node 提供了线程模块,对进程的操作已经很少使用了
2)线程
- 操作系统启动一个进程(无论是主进程,还是子进程),都会自动为它分配一个线程,称之为主线程
- 主线程在运行的过程中,可以创建多个线程,这些线程称之为子线程
- 当操作系统命令 CPU 去执行一个进程时,实际上,是在该进程的多个线程中切换执行
警告
程序一定在线程上运行
- 线程和进程很相似,它们都是独立运行
- 最大的区别在于:线程的内存空间没有隔离,共享进程的内存空间
- 线程之间的数据不用遵守任何协议,可以随意使用
a)什么时候使用
- 使用线程的主要目的,是为了充分使用多核 CPU
- 线程执行过程中,尽量的不要阻塞
最理想的线程效果
- 线程数等于 CPU 的核数
- 线程永不阻塞
- 没有 IO
- 只存在大量运算
- 线程相对独立,几乎不使用共享数据
- 线程一般处理 CPU 密集型操作(运算操作)
- 而 IO 密集型操作不适合使用线程,适合使用异步
- 只有一个线程
- 没有切换开销
b)Node 开启线程
- 为了避免线程执行过程中共享数据产生的麻烦,Node 使用独特的线程机制来尽力规避
// 创建子线程的父线程
const { Worker } = require("worker_threads");
const worker = new Worker(线程执行的入口文件, {
workerData: 开启线程时向其传递的数据,
}); // worker是子线程实例
// 通过EventEmitter监听子线程的事件
worker.on("exit", () => {
// 当子线程退出时运行的事件
});
worker.on("message", (msg) => {
// 收到子线程发送的消息时运行的事件
});
worker.postMessage(任意消息); // 父线程向子线程发送任意消息
worker.terminate(); // 退出子线程
- 子线程
const {
isMainThread, // 是否是主线程
parentPort, // 用于与父线程通信的端口
workerData, // 获取线程启动时传递的数据
threadId, // 获取线程的唯一编号
} = require("worker_threads");
parentPort.on("message", (msg) => {
// 当收到父线程发送的消息时,触发的事件
});
parentPort.postMessage(workerData); // 向父线程发送消息
3)线程使用示例
- 判断素数
module.exports = function (n) {
// 素数:只能被1和自身整除的数
if (n < 2) {
return false;
}
for (let i = 2; i < n; i++) {
if (n % i === 0) {
return false;
}
}
return true;
};
a)单线程
const isPrime = require("./isPrime");
const arr = require("./numbers.json");
console.time();
const newArr = [];
for (const n of arr) {
if (isPrime(n)) {
newArr.push(n);
}
}
console.timeEnd(); // 5.634s
console.log(newArr);
b)多线程
- 父线程
const { Worker } = require("worker_threads");
const os = require("os");
const arr = require("./numbers.json");
// CPU数量
const cpuNumber = os.cpus().length;
// 每个线程需要处理的数字数量
const len = Math.ceil(arr.length / cpuNumber);
console.time();
// 目前的线程数量
let numbers = cpuNumber;
// 保存最终结果
const newArr = [];
for (let i = 0; i < cpuNumber; i++) {
const data = arr.slice(i * len, (i + 1) * len);
// worker是子线程实例
const worker = new Worker("./worker.js", {
workerData: data,
});
worker.on("message", (result) => {
newArr.push(...result);
numbers--;
if (numbers === 0) {
// 所有线程都处理结束
console.timeEnd(); // 1.685s
// 输出最终结果
console.log(newArr);
}
worker.terminate();
});
}
- 子线程
const isPrime = require("./isPrime");
const {
parentPort, // 用于与父线程通信的端口
workerData, // 获取线程启动时传递的数据
threadId, // 获取线程的唯一编号
} = require("worker_threads");
const name = `线程${threadId}`;
const newArr = [];
for (const n of workerData) {
if (isPrime(n)) {
newArr.push(n);
}
}
console.log(`${name}处理完成,并把结果给予了主线程`);
parentPort.postMessage(newArr);